Hi @Hariharan Sambath, We haven't heard from you on the last response from @Debayan Mukherjee and @Hubert Dudek, and I was checking back to see if his suggestions helped you. Or else, If you have any solution, please share it with the community as...
When I am trying to read data from elasticsearch by spark sql, it throw an error like RuntimeException: Error while encoding: java.lang.RuntimeException: scala.collection.convert.Wrappers$JListWrapper is not a valid external type for schema of string...
Hi there @KARTHICK N Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.T...
Hello Experts,I am new to Databricks. Building data pipelines, I have both batch and streaming data.Should I use Dataframes API to read csv files then convert to parquet format then do the transformation? orwrite to table using CSV then use Spark SQL...
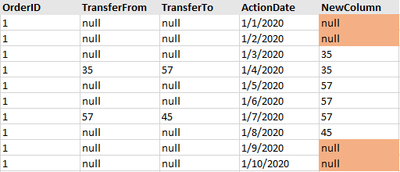
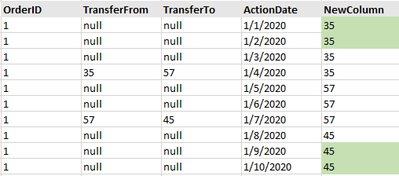
I'm trying to create a new column that fills in the nulls below. I tried using leads and lags but isn't turning out right. Basically trying to figure out who is in "possession" of the record, given the TransferFrom and TransferTo columns and sequence...
Hi there @Eric Lohbeck Does @Hubert Dudek response answer your question? If yes, would you be happy to mark it as best so that other members can find the solution more quickly?We'd love to hear from you.Thanks!
I am try to get the percentile values on different splits but I got that the result of Databricks PERCENTILE_DISC() function is not accurate . I have run the same query on MS SQL but getting different result set.Here are both result sets for Pyspark ...
I am using below code to create the Spark session and also loading the csv file. Spark session and loading csv is running well. However SQL query is generating the Parse Exception.%pythonfrom pyspark.sql import SparkSession # Create a SparkSessio...
This is resolved. Below query works fine nowsqldf = spark.sql("select sum(cast(enrollment as float)), sum(cast(growth as float)),`plan type`,`Parent Organization`,state,`Special Needs Plan`,`Plan Name Sec A`, CASE when `Plan ID` between '800' and '89...
Hello Community,I am trying to search for Databricks notebook command logging feature for compliance purpose.My requirement is to log the exact spark sql fired by user.I didnt get spark sql (notebook command) tracked under this azure diagnostic logs....
Hi @C P we don't have this feature implemented, however, there is already an existing idea available in our idea portal here: https://databricks.aha.io/features/DB-7583.You can check and vote the same.
Is there a way to compare a time stamp within on field/column for an individual ID? For example, if I have two records for an ID and the time stamps are within 5 min of each other....I just want to keep the latest. But, for example, if they were an h...
Hi @Cory Bullard, We haven't heard from you on the last response from @Merca Ovnerud, and I was checking back to see if you have a resolution yet. If you have any solution, please share it with the community as it can be helpful to others. Otherwis...
Hi:It's possible to create temp views in pyspark using a dataframe (df.createOrReplaceTempView()), and it's possible to create a permanent view in Spark SQL. But as far as I can tell, there is no way to create a permanent view from a dataframe, somet...
Hi Kaniz:This is what I understood from the research I did, I was curious more as to why permanent views can't be created from dataframes and whether this is a feature that might be implemented by Databricks or Spark at some point. Temporary views ca...
Hi Johan,Were you able to resolve the correlated column exception issue? I have been stuck on this since past week. If you can guide me that will be alot of help.Thanks.
Seems to be a duplicate of your comment on https://community.databricks.com/s/question/0D53f00001XCuCACA1/correlated-column-exception-in-sql-udf-when-using-udf-parameters. I guess you did that to be able to put other tags?
I am using databricks sql notebook to run these queries. I have a Python UDF like %python
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType, DoubleType, DateType
def get_sell_price(sale_prices):
return sale_...
Hello. I am trying to using the Pivot function for email addresses. This is what I have so far:Select fname, lname, awUniqueID, Email1, Email2From xxxxxxxxPivot ( count(Email) as Test For Email In (1 as Email1, 2 as Email2) )I get everyth...
When i try to execute sql query(2 joins) i get below message: com.databricks.backend.common.rpc.DatabricksExceptions$SQLExecutionException: org.apache.spark.util.SparkFatalException
at org.apache.spark.sql.execution.exchange.BroadcastExchangeExec.$a...
@Erni Jed , I tested, and your query is ok. So it has to be some other issue. Maybe you could try it on a smaller data set. Please analyze/debug also using SPARK UI.
Hi,Using the below cosmos DB query it is possible to achieve the expected output, but how can I do the same with spark SQL in Databricks.COSMOSDB QUERY : select c.ReportId,c.ReportName,i.price,p as provider from c join i in in_network join p in i.pr...
Hi @Abhishek Tomar , If you want to get it from Cosmos DB, use the connector with a custom query https://github.com/Azure/azure-cosmosdb-sparkIf you want to have JSON imported directly by databricks/spark, please go with the below solution:SELECT
...
I have python variable created under %python in my jupyter notebook file in Azure Databricks. How can I access the same variable to make comparisons under %sql. Below is the example:%python
RunID_Goal = sqlContext.sql("SELECT CONCAT(SUBSTRING(RunID,...
You can use {} in spark.sql() of pyspark/scala instead of making a sql cell using %sql.This will result in a dataframe. If you want you can create a view on top of this using createOrReplaceTempView()Below is an example to use a variable:-# A variab...