from pyspark.sql import functions as F
from pyspark.sql import types as T
from pyspark.sql import DataFrame, Column
from pyspark.sql.types import Row
import dlt
S3_PATH = 's3://datalake-lab/XXXXX/'
S3_SCHEMA = 's3://datalake-lab/XXXXX/schemas/'
...
This documentation https://api-docs.databricks.com/python/pyspark/latest/pyspark.sql/api/pyspark.sql.SparkSession.sql.html#pyspark.sql.SparkSession.sql claims that spark.sql() should be able to take kwargs, such that the following should work:display...
Ok, it looks like Databricks might have broken this functionality shortly after it came out: https://community.databricks.com/t5/data-engineering/parameterized-spark-sql-not-working/m-p/57969/highlight/true#M30972
Hi Team,Please provide guidance on enabling SQL cells parallel execution in a notebook containing multiple SQL cells. Currently, when we execute notebook and all the SQL cells they run sequentially. I would appreciate assistance on how to execute th...
There are multiple tables in the config/metadata table. These tables need to bevalidated for DQ rules.1.Natural Key / Business Key /Primary Key cannot be null orblank.2.Natural Key/Primary Key cannot be duplicate.3.Join columns missing values4.Busine...
Hi @subha2, To dynamically validate the data quality (DQ) rules for tables configured in a metadata-driven system using PySpark, you can follow these steps:
Define Metadata for Tables:
First, create a metadata configuration that describes the rules ...
Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answers your question?This...
I need databricks for a university research project. Is there any possibility of EDU discounts on DBU? So far I was unable to reach out to Databricks sales. Can you connect me with someone from DB?
Hi community,I am using a pyspark udf. The function is being imported from a repo (in the repos section) and registered as a UDF in a the notebook. I am getting a PythonException error when the transformation is run. This is comming from the databric...
I was getting a similar error (full traceback below), and determined that it's related to this issue. Setting the env variables DATABRICKS_HOST and DATABRICKS_TOKEN as suggested in that Github issue resolved the problem for me (albeit it's not a grea...
I have a notebook in Azure Databricks that does some transformations on a bronze tier table and inserts the transformed data into a silver tier table. This notebook is used to do an initial load of the data from our existing system into our new datal...
Please review your Spark UI from the old job execution versus the new job execution. You might need to check if the data volume has increase and that could be the reason of the OOM
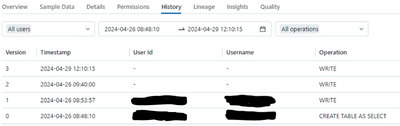
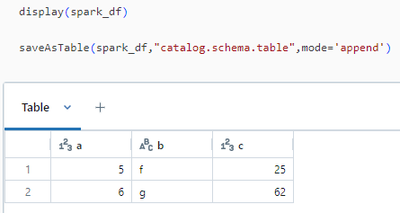
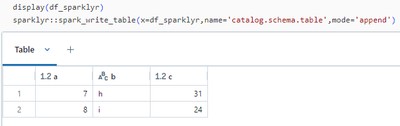
Hi,for some reason Azure Databricks doesn't show History if the data is saved with SparkR (2 in the figure below) or Sparklyr (3), but it does show it with Data Ingestion (0) or with PySpark (1). Is this a known bug or am I doing something wrong? Is ...
Hi @Sagas, Let’s address your questions regarding Azure Databricks, SparkR, and Sparklyr.
History in Azure Databricks:
Each operation that modifies a Delta Lake table creates a new table version. You can use history information to audit operation...
Hi Team,We intend to activate the job cluster around the clock. We consider the following parameters regarding cost: - Data volumes - Client SLA for job completion- Starting with a small cluster configuration Please advise on any other options we s...
Hi @Phani1, When configuring a job cluster for 24/7 operation, it’s essential to consider cost, performance, and scalability.
Here are some recommendations based on your specified parameters:
Data Volumes:
Analyze your data volumes carefully. If...
Dear allI have a workflow with 2 tasks : one that does OPTIMIZE, followed by one that does VACUUM. I used a cluster with F32s driver and F64s - 8 workers (auto-scaling enabled). All 8 workers are launched by Databricks as soon as OPTIMIZE starts. As ...
Hi,I am having an issue of loading source data into a delta table/ unity catalog. The error we are recieving is the following:grpc_message:"[DELTA_EXCEED_CHAR_VARCHAR_LIMIT] Exceeds char/varchar type length limitation. Failed check: (isnull(\'metric_...
Hey @Paul92S Looking at the error message it looks like column "metric_name" is the culprit here:Understanding the Error:Character Limit Violation: The error indicates that values in the metric_name column are exceeding the maximum length allowed fo...
Hello Databricks Community,I am currently working in a Databricks environment and trying to set up custom logging using Log4j in a Python notebook. However, I've run into a problem due to the use of Spark Connect, which does not support the _jvm attr...
Hi Team,Is there any impact when integrating Databricks with Boomi as opposed to Azure Event Hub? Could you offer some insights on the integration of Boomi with Databricks?https://boomi.com/blog/introducing-boomi-event-streams/Regards,Janga
Hi @Phani1, Let’s explore the integration of Databricks with Boomi and compare it to Azure Event Hub.
Databricks Integration with Boomi:
Databricks is a powerful data analytics platform that allows you to process large-scale data and build machin...
Hi Community,i was trying to load a ML Model from a Azure Storageaccount (abfss://....) with: model = PipelineModel.load(path) i set the spark config: spark.conf.set("fs.azure.account.auth.type", "OAuth")
spark.conf.set("fs.azure.account.oauth.provi...