- 2253 Views
- 2 replies
- 0 kudos
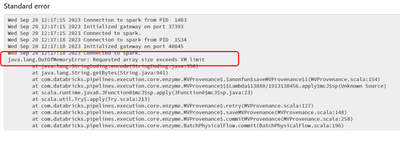
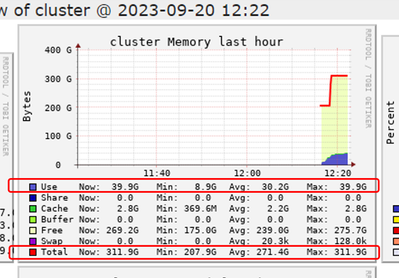
DLT Pipeline Out Of Memory Errors
I have a DLT pipeline that has been running for weeks. Now, trying to rerun the pipeline with the same code and same data fails. I've even tried updating the compute on the cluster to about 3x of what was previously working and it still fails with ou...
- 2253 Views
- 2 replies
- 0 kudos
- 0 kudos
I'd focus on understanding the codebase first. It'll help you decide what logic or data asset to keep or not keep when you try to optimize it. If you share the architecture of the application, the problem it solves, and some sample code here, it'll h...
- 0 kudos
- 4379 Views
- 1 replies
- 0 kudos
How to stop SparkSession within notebook without errr
I want to run an ETL job and when the job ends I would like to stop SparkSession to free my cluster's resources, by doing this I could avoid restarting the cluster, but when calling spark.stop() the job returns with status failed even though it has f...
- 4379 Views
- 1 replies
- 0 kudos
- 0 kudos
Please refer to this Job fails, but Apache Spark tasks finish - Databricks
- 0 kudos
- 8021 Views
- 3 replies
- 1 kudos
Referring to Azure Keyvault secrets in spark config
Hi allIn spark config for a cluster, it works well to refer to a Azure Keyvault secret in the "value" part of the name/value combo on a config row/setting.For example, this works fine (I've removed the string that is our specific storage account name...
- 8021 Views
- 3 replies
- 1 kudos
- 1 kudos
Hello,Is there any update on this issue please? Databricks no longer recommend mounting external location, so the other way to access Azure storage is to use spark config as mentioned in this document - https://learn.microsoft.com/en-us/azure/databri...
- 1 kudos
- 209 Views
- 0 replies
- 0 kudos
Bamboolib error
What is the status of bamboolib? I understand that it is public preview but I'm unable to find any support references. I am getting error below. I've tried installing in a notebook, on a cluster, creating a pandas dataframe and running bam, etc. ...
- 209 Views
- 0 replies
- 0 kudos
- 2535 Views
- 4 replies
- 0 kudos
Create cluster error: Backend service unavailable
hello,i'm new to Databricks (community edition account) and encountered a problem just now.When creating a new cluster (default 10.4 LTS) it fails with the following error: Backend service unavailable.I've tried a different runtime > same issue.I've ...
- 2535 Views
- 4 replies
- 0 kudos
- 0 kudos
Hey mbvb_py,I'm sorry to hear you're facing this "Backend service unavailable" issue with Databricks. I've encountered similar problems in the past, and it can be frustrating. Don't worry; you're not alone in this!From my experience, this error can o...
- 0 kudos
- 1609 Views
- 2 replies
- 0 kudos
How does Job Cluster knows how many resources to assign to an Application ?
Hi All Enthusiasts !As per my understanding when a user submits an application in spark cluster it specifies how much memory, executors etc. it would need . But in Data bricks notebooks we never specify that anywhere. If we have submitted the noteboo...
- 1609 Views
- 2 replies
- 0 kudos
- 0 kudos
@DBEnthusiast great question! Today, with Job Clusters, you have to specify this. As @btafur note, you do this by setting CPU, memory etc. We are in early preview of Serverless Job Clusters where you no longer specify this configuration, instead Data...
- 0 kudos
- 4107 Views
- 4 replies
- 1 kudos
Databricks Job scheduling - continuous mode
While scheduling the Databricks job using continuous mode - what will happen if the job is configured to run with Job cluster.At the end of each run will the cluster be terminated and re-created again for the next run? The official documentation is n...
- 4107 Views
- 4 replies
- 1 kudos
- 1 kudos
Hello @youssefmrini So how is the DBU calculated? As the cluster is reused, the DBU should be calculated per hour on all the jobs run in an hour correct? Or will it be calculated based on each run?I would like to know the cost calculation when runnin...
- 1 kudos
- 25937 Views
- 4 replies
- 3 kudos
Resolved! How to set a variable and use it in a SQL query
I want to define a variable and use it in a query, like below: %sql SET database_name = "marketing"; SHOW TABLES in '${database_name}';However, I get the following error:ParseException: [PARSE_SYNTAX_ERROR] Syntax error at or near ''''(line 1, pos...
- 25937 Views
- 4 replies
- 3 kudos
- 3 kudos
Another option is demonstrated by this example:%sql SET database_name.var = marketing; SHOW TABLES in ${database_name.var}; SET database_name.dummy= marketing; SHOW TABLES in ${database_name.dummy};do not use quotesuse format that is variableName...
- 3 kudos
- 897 Views
- 1 replies
- 1 kudos
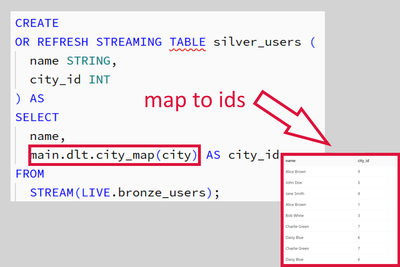
Streaming Data Modeling Normalization with Databricks Delta Live Tables
Streamline Data Modeling Normalization with Databricks Delta Live Tables in Just a Few Steps:- Use the "Apply changes" function to populate tables with slowly changing dimensions using auto-increment IDs.- Register SQL mapping functions to associate ...


- 897 Views
- 1 replies
- 1 kudos
- 6336 Views
- 9 replies
- 0 kudos
Invisible empty spaces when reading .csv files
When importing a .csv file with leading and/or trailing empty spaces around the separators, the output results in strings that appear to be trimmed on the output table or when using .display() but are not actually trimmed.It is possible to identify t...
- 6336 Views
- 9 replies
- 0 kudos
- 0 kudos
I discovered an in-depth article that went beyond the physical aspects of aging and testosterone. It examined the emotional https://misterolympia.shop/buy/injectable-steroids/testosterone/testosterone-cypionate/ and psychological aspects of growing o...
- 0 kudos
- 8745 Views
- 11 replies
- 2 kudos
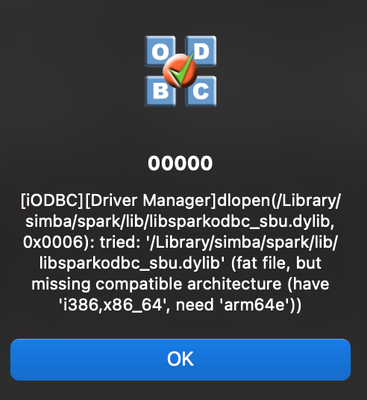
Resolved! Problems connecting Simba ODBC with a M1 Macbook Pro
Hi,There's a way to make work the Simba ODBC Driver for M1 Macbook Pros?I find myself able to run on an old intel version of Macbook easily, but now every time I even test the connection with the iODBC Manager fails.Definitely, the issue is around no...
- 8745 Views
- 11 replies
- 2 kudos
- 2 kudos
Things seem to be mostly working for me now. I've added a bit more detail on my connection steps and process in case it's helpful for anyone on Stack Overflow: https://stackoverflow.com/questions/76407426/connecting-rstudio-desktop-to-databricks-comm...
- 2 kudos
- 3435 Views
- 5 replies
- 1 kudos
com.databricks.spark.safespark.UDFException: UNAVAILABLE: Channel shutdownNow invoked
Trying to determine a root cause of UDFException that occurs when returning a variable length ArrayType. If I hardcode the data returned from the UDF to a fixed length, say 19, the error does not occur. Setup codesplit_runs_UDF = udf(split_runs_udf, ...
- 3435 Views
- 5 replies
- 1 kudos
- 1 kudos
After further investigation, It reproduces slightly differently on single user mode.Single user mode: runs foreverShared: gives the above messageI've determined that there was a corner case in the dataset which lead to UDF never returning. I am am as...
- 1 kudos
- 1855 Views
- 2 replies
- 1 kudos
DLT current channel uses same runtime as the preview channel
Hi,According to the latest release notes, the current channel of DLT should be using Databricks runtime 11.3 and the preview channel should be using 12.2. The current channel was using correct runtime version 11.3 still yesterday morning, but since ...
- 1855 Views
- 2 replies
- 1 kudos
- 1 kudos
I'm seeing the same issue with 12 current / 13 preview. Updating the channel didn't bump the runtime version and even creating a pipeline with the preview channel uses the current version.
- 1 kudos
- 2046 Views
- 4 replies
- 0 kudos
Correlated column is not allowed in non predicate in UDF SQL
Hi Team,I am new to databricks and currently working on creating sql udf 's in databricks .In udf we are calculating min date and that date column using in where clause also.While running udf getting Correlated column is not allowed in non predica...
- 2046 Views
- 4 replies
- 0 kudos
- 0 kudos
Could you please provide your full code? I would also like to know which DBR version you are using in your cluster.
- 0 kudos
- 5669 Views
- 5 replies
- 6 kudos
Bug? Unity Catalog incompatible with Sparklyr in RStudio (on Driver) and as well if used on one cluster from multiple notebooks?
If I start a RStudio Server with in cluster init script as described here in a Unity Catalog Cluster the sparklyr connection fails with an error about a missing Credential Scope.=LI tried it both in 11.3LTS and 12.0 Beta. I tried it only in a Persona...
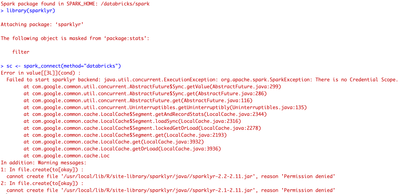
- 5669 Views
- 5 replies
- 6 kudos
- 6 kudos
Have run into this issue as well. Let me know if there was any resolution
- 6 kudos
Connect with Databricks Users in Your Area
Join a Regional User Group to connect with local Databricks users. Events will be happening in your city, and you won’t want to miss the chance to attend and share knowledge.
If there isn’t a group near you, start one and help create a community that brings people together.
Request a New Group-
% Conda
2 -
% Score
3 -
%run
5 -
%sh
2 -
10.4 LTS
1 -
11.2 LTS
1 -
2: Dbutils.notebook.run command
2 -
9.1LTS
1 -
<script>alert(1)<script>
2 -
`python Wheel
2 -
Aad
7 -
AB Testing
2 -
ABFS
3 -
Academic Team
1 -
Academy
12 -
Accdb Files
2 -
Access
33 -
Access Connector
2 -
Access control
4 -
Access Controls
2 -
Access Data
2 -
Access Databricks
4 -
Access Delta Tables
2 -
Access Token
5 -
Account
15 -
Account Console
5 -
AccountPolicy
1 -
Acess Token
2 -
ACL
4 -
Action
4 -
Activate Gift Certificate
1 -
ActiveMQConnector
1 -
Actual Results
2 -
Adaptive Query Execution
5 -
ADB
8 -
adb identifier
1 -
Add
4 -
Adf
23 -
ADF Pipeline
8 -
ADLS
22 -
ADLS Gen
4 -
ADLS Gen2 Storage
4 -
ADLS Gen2 Using ABFSS
2 -
ADLS Gen2 With ABFSS
2 -
Adls-gen2
5 -
Adlsgen2
10 -
Admin
5 -
AdminConsoleUI
1 -
Administration
4 -
Administrator
1 -
AdministratorPrivileges
1 -
Advanced Data Engineering
3 -
Aggregations
4 -
AI
3 -
AI Summit
13 -
Airflow
6 -
Alias
3 -
Alter table
4 -
ALTER TABLE Table
2 -
Amazon
5 -
Amazon s3
2 -
AmazonEKS
1 -
AmazonS3
1 -
AmazonSES
1 -
AML
2 -
Analysisexception
4 -
Analytics
2 -
Announcement
1 -
Apache
3 -
Apache Sedona
2 -
Apache spark
86 -
Apache spark dataframe
2 -
Apache Spark SQL
2 -
ApacheArrow
1 -
ApachePig
3 -
ApacheSolr
1 -
ApacheSpark
1 -
API
64 -
Api Calls
4 -
API Documentation
2 -
Api Requests
2 -
APIAuthentication
1 -
APIBindings
1 -
APIDocs
1 -
ApiLinks
1 -
Apis
2 -
APISecret
1 -
APIStreamMonitoring
1 -
ApiToken
1 -
App
1 -
Append
5 -
Apple
2 -
Application
3 -
Apply
2 -
Aqe
6 -
Architecture
2 -
Arguments
2 -
ARM
3 -
Array
13 -
Array Column
4 -
Arrow
2 -
Arrow Objects
3 -
Article
4 -
Artifacts
2 -
ASEANlakehouse
1 -
Associate Dev Certification
1 -
Associate Developer
7 -
At Least One Column Must Be Specified For The Table
2 -
Athena
5 -
Audit
3 -
Audit Log Delivery
2 -
Audit Logs
7 -
AureAD
1 -
Authentication
8 -
Autloader
2 -
Auto
7 -
Auto Scaling
2 -
Auto-loader
3 -
Auto-optimize
3 -
Auto-scaling
2 -
Autoloader
91 -
Autoloader Approach
3 -
Autoloader Directory Listing Mode
2 -
Autologging
1 -
Automation
5 -
Automl
6 -
AutoML Experiment
3 -
Availability
2 -
Availability Zone
3 -
AvailabilityZone
1 -
Avro
8 -
AWS
114 -
Aws account
5 -
AWS Cloudwatch
3 -
Aws databricks
16 -
Aws glue
2 -
AWS Glue Catalog
1 -
Aws Instance
1 -
Aws lambda
4 -
AWS Learn
2 -
Aws s3
15 -
AWS S3 Storage
3 -
AWSAthena
1 -
AWSCloudwatch
1 -
AWSCredentials
1 -
AWSDatabricksCluster
1 -
AWSEBS
1 -
AWSEFS
1 -
AWSFreeTier
1 -
AWSInstanceProfile
2 -
AWSKinesis
1 -
AWSMacie
1 -
AWSMSK
1 -
AWSQuickstart
1 -
AWSRDS
1 -
AWSRedshift
1 -
AWSSagemaker
1 -
AwsSdk
1 -
AWSSecretsManager
1 -
AWSServices
1 -
AWSStandard Tier
1 -
AZ
2 -
Azure
416 -
Azure Account Console
2 -
Azure active directory
2 -
Azure Active Directory Tokens
2 -
Azure AD
7 -
Azure blob storage
13 -
Azure Blob Storage Container
2 -
Azure data factory
30 -
Azure data lake
14 -
Azure data lake gen2
2 -
Azure Data Lake Storage
7 -
Azure data lake store
2 -
Azure databricks
310 -
Azure Databricks Delta Table
1 -
Azure Databricks Job
2 -
Azure Databricks SQL
4 -
Azure databricks workspace
4 -
Azure DBX
2 -
Azure Delta Lake
2 -
Azure DevOps
15 -
Azure devops integration
7 -
Azure event hub
8 -
Azure functions
3 -
Azure key vault
4 -
Azure Service Principal
3 -
Azure sql data warehouse
2 -
Azure sql database
3 -
Azure SQL DB
2 -
Azure Sql Server
2 -
Azure Storage
11 -
Azure Storage Account
8 -
Azure synapse
2 -
Azure Unity Catalog
3 -
Azure vm
4 -
Azure workspace
4 -
Azure-cosmosdb-sqlapi
2 -
Azure-databricks
3 -
AzureAD
1 -
Azureblob
3 -
AzureContainerRegistry
1 -
AzureDatabricks
12 -
AzureDatalake
1 -
AzureDevopsRepo
2 -
AzureDL
1 -
AzureEnvironments
1 -
AzureExtension
1 -
AzureFirewall
1 -
AzureFunctionsError
1 -
AzureHbase
1 -
AzureKeyVault
3 -
AzureLakeGen
1 -
AzureLogAnalytics
2 -
AzureLogicApps
2 -
AzureManagement
1 -
AzureMaps
1 -
AzureML
1 -
AzurePipelines
1 -
AzurePortal
1 -
AzureRepos
2 -
AzureSchemaRegistry
1 -
Azuresql
2 -
AzureSQLWarehouse
1 -
AzureStorage
6 -
AzureSynapse
1 -
Backend Service
3 -
Backup
4 -
Backup-restore
1 -
Bad Formatting
2 -
Badge
1 -
Bamboolib
2 -
Bangalore
2 -
Bar
1 -
Batch Duration
2 -
Batch Process
2 -
Batch Processing
4 -
BatchJob
5 -
BatchPrediction
1 -
Bay Area
2 -
Best Answer
1 -
Best Architecture
3 -
Best Data Warehouse
1 -
Best practice
23 -
Best Practices
47 -
Best Way
30 -
Beta
1 -
Better Way
1 -
Bi
8 -
BI Integrations
7 -
BI Tool
2 -
Big data
8 -
Big Files
2 -
Bigquery
8 -
Billing
3 -
Billing and Cost Management
8 -
Binary data
2 -
Binary file
3 -
Binary Incompatibility
2 -
Bitbucket
2 -
Blob
11 -
Blob-storage
3 -
BlobData
1 -
BlobHash
1 -
Blobstorage
8 -
BlobStorageContainer
1 -
Blog
1 -
Blog Post
1 -
Bloom Filter
3 -
BloomFilterIndex
2 -
Body
3 -
Bootstrap Timeout
4 -
Boto3
1 -
Broadcast variable
2 -
BroadcastJoin
4 -
Bronze Layer
3 -
Bronze Table
4 -
BTW
1 -
Bucket
8 -
Bucketing
3 -
Bug
13 -
Bug Report
24 -
Business
2 -
Business Analytics
2 -
BYOK Notebook
2 -
Cache
14 -
Caching
1 -
Cancelled
4 -
Cartesian
2 -
CASE Statement
2 -
Cassandra
1 -
Cast
3 -
Cast To Float
2 -
Catalog
10 -
CatalogFeature
1 -
Catalyst
2 -
CatalystOptimizer
1 -
CD Pipeline
3 -
Cdc
18 -
CDCLogs
1 -
CDF
5 -
CDM
2 -
CE
1 -
Cell
12 -
Cells
4 -
Centralized Model Registry
1 -
CentralizedFeatureStore
1 -
Cert
2 -
Certfication
5 -
Certificate
25 -
Certificate & Badge
1 -
Certificate And Badge
2 -
Certificates
2 -
Certification
40 -
Certification Exams
6 -
Certification Guidance
1 -
Certification issues
3 -
Certification Voucher
13 -
Certification Vouchers
1 -
Certified Data Engineer Associate
5 -
Certified Data Engineer Professional
1 -
Certified Machine Learning Associate
1 -
Change
9 -
Change Data
7 -
Change data capture
6 -
Change Data Feed
4 -
Change Logs
1 -
ChangeError
1 -
ChangeFeed
2 -
ChangingDimensions
1 -
ChangingSchema
1 -
chatwithcommunity
2 -
Check
1 -
Checkpoint
12 -
Checkpoint Directory
3 -
Checkpoint File
2 -
Checkpoint Path
4 -
Child Notebook
2 -
Chrome
5 -
Chrome driver
4 -
CHUNK
1 -
Ci
3 -
CICD
24 -
Class
6 -
Class Class
1 -
Classification Model
1 -
Clean up files
2 -
Cli
31 -
Client Secret
2 -
Clone
5 -
CloneRepository
4 -
Cloud
7 -
Cloud Fetch
2 -
Cloud Instance
2 -
Cloud Provider Launch Failure
2 -
Cloud Storage
3 -
Cloud_files_state
2 -
CloudFiles
7 -
CloudFormation
6 -
Cloudformation Error
5 -
Cloudwatch
3 -
Cluster
165 -
Cluster Autoscaling
4 -
Cluster config
3 -
Cluster Configuration
10 -
Cluster Creation
2 -
Cluster Failed To Launch
3 -
Cluster Init Script
3 -
Cluster management
26 -
Cluster Metrics
2 -
Cluster Mode
2 -
Cluster Modes
2 -
Cluster monitoring
2 -
Cluster Policies
3 -
Cluster policy
2 -
Cluster Pools
3 -
Cluster provisioning
5 -
Cluster Start
5 -
Cluster Tags
1 -
Cluster Termination
2 -
Cluster-logs
3 -
ClusterACL
2 -
ClusterConfiguration
1 -
ClusterCreation
1 -
ClusterCreationRestriction
1 -
ClusterDefinition
1 -
Clustering
1 -
ClusterInitialisation
1 -
ClusterIssue
1 -
ClusterLaunch
1 -
ClusterLibraries
1 -
ClusterLibrary
1 -
ClusterLoad
1 -
ClusterLoadBalancing
1 -
Clusterlogs
1 -
ClusterMaxWorkers
1 -
ClusterMode
1 -
ClusterOptimization
1 -
ClusterPool
1 -
ClusterRuntime
1 -
Clusters
30 -
Clusters Users
2 -
ClusterScope
1 -
ClusterSettings
1 -
ClusterSize
2 -
ClusterSQLEndpoints
1 -
ClusterStartTime
2 -
ClusterTermination
1 -
ClusterUsage
1 -
ClusterVersion
1 -
ClusterWeb
1 -
Cmd File
2 -
CMK
4 -
CNN HOF
1 -
Code
45 -
Code Block
2 -
Collect
3 -
Collect_set
3 -
Collibra
1 -
Column
43 -
Column names
5 -
Column Values
2 -
ColumnACL
1 -
ColumnLevelSecurity
1 -
ColumnObject
1 -
ColumnPosition
1 -
Columns
17 -
ColumnType
2 -
ColumnValue
1 -
Command
13 -
Command execution
2 -
Comments
4 -
Common Key
2 -
Community
45 -
Community Account
2 -
Community Champion
1 -
Community Edition
53 -
Community Edition Account
3 -
Community Edition Login Issues
1 -
Community Edition Password
2 -
Community Group
1 -
Community Members
1 -
Community Social
5 -
Community User Account
2 -
Community Version
2 -
Compaction
2 -
Company Email
10 -
COMPANY FROM TEST
2 -
Complete Certification
1 -
Complex Json File
3 -
Complex Transformations
3 -
Compliance
2 -
Compression
2 -
Compute
2 -
Compute Instances
2 -
Concat Ws
3 -
Concurrency
7 -
Concurrency Control
1 -
ConcurrencyCluster
1 -
Concurrent notebooks
3 -
Concurrent Runs
2 -
Concurrent Writes
2 -
ConcurrentJobs
1 -
ConcurrentNotebook
1 -
Conda
1 -
Condition
4 -
Config
5 -
Config File
2 -
Config Parameters
2 -
Configuration
15 -
ConfigurationBestPractices
1 -
ConfigurationInvalid Configuration Value
1 -
ConfigurationSettings
1 -
Configure
3 -
Configure Databricks
3 -
Configure Job
2 -
Confluent
2 -
Confluent Cloud
2 -
Confluent Schema Registry
2 -
ConfluentKafka
1 -
ConfluentKstream
1 -
Congratulate Malleswari
1 -
Connect
22 -
Connection
15 -
Connection error
3 -
Connection String
2 -
Connections
2 -
Connectivity
4 -
Console
2 -
ConsumerLagdedu
1 -
Container
4 -
Containerized Databricks
2 -
ContainerServices
1 -
ContainerSubnet
1 -
ContainerThreshold
1 -
Content
6 -
Continuous Integration Pipeline
2 -
Continuous Jobs
2 -
Control Plane
4 -
ControlPlane
2 -
Conversion
4 -
Convert
6 -
Copy
9 -
Copy File Path
2 -
Copy into
3 -
COPY INTO Command
6 -
COPY INTO Statement
2 -
CosmodDB
1 -
Cosmos Mongo DB
2 -
Cosmos-db
2 -
CosmosDB
4 -
Cost
7 -
Cost Optimization Effort
1 -
CostBreakdown
1 -
CostExplorer
1 -
CostFactor
1 -
CostLimits
1 -
CostOptimization
2 -
CostOptimized
1 -
CostTracking
1 -
Couchbase
1 -
Count
3 -
Course
6 -
Course Code
1 -
Courses
2 -
CRC
2 -
Create
17 -
Create Dashboard API
2 -
Create function
2 -
CREATE OR REPLACE TABLE
2 -
Create table
5 -
CREATE WIDGET
2 -
Creating
4 -
Creating cluster
4 -
Creation
2 -
Credential passthrough
6 -
Credentials
5 -
Cristian
2 -
Cron Syntax
1 -
Cronjob
3 -
Crossjoin
1 -
CSV
77 -
CSV Export
2 -
CSV File
13 -
Csv files
6 -
Ctas
2 -
CURL
1 -
Current Cluster
2 -
Current Date
8 -
Custom Catalog
2 -
Custom Docker Image
4 -
Custom Python
2 -
CustomClusterTag
1 -
CustomContainer
2 -
CustomDocker
1 -
CustomDockerContainer
1 -
Customer Academy
1 -
Customer managed vpc
2 -
Customer Record
2 -
CustomJDBC
1 -
CustomLibrary
2 -
CustomLog4jLogs
1 -
CustomPythonPackage
1 -
CustomQueue
1 -
CustomSchema
1 -
CustomSessionVariable
1 -
CustomSparkExtension
1 -
Cybersecurity
1 -
DAG
1 -
DAIS2023
21 -
Dashboard
28 -
Dashboards
8 -
Data
156 -
Data + AI Summit
1 -
Data + AI World Tour 2022
5 -
Data AI Summit
1 -
Data Analyst
3 -
Data Architecture
2 -
Data Bricks Session
2 -
Data Bricks Sync
2 -
Data Column
2 -
Data Directories
2 -
Data Engineer
8 -
Data Engineer Associate
23 -
Data Engineer Associate Certificate
4 -
Data Engineering
33 -
Data Engineering Professional Certificate
1 -
Data Engineering Professional Certification
3 -
Data Exfiltration
2 -
Data Explorer
7 -
Data factory
5 -
Data Governance
2 -
Data Ingestion
8 -
Data Ingestion & connectivity
150 -
Data Lineage Graph
2 -
Data load
4 -
Data Mesh
2 -
Data Pipeline
8 -
Data Plane
1 -
Data Processing
2 -
Data Quality
3 -
Data Quality Checks
3 -
Data Science
8 -
Data Science & Engineering
2 -
Data Source Mongodb
2 -
Data Tab
2 -
Data Type Conversion
2 -
Data warehouse
5 -
Data-frames
2 -
Database
15 -
Database Db
2 -
DatabaseLocation
1 -
DatabaseOperations
1 -
DatabaseOwner
1 -
DatabaseSchema
1 -
DatabaseTables
1 -
Databrags
4 -
Databrciks Runtime
1 -
Databrick Certification
1 -
Databrick Job
5 -
Databrick Workspace
2 -
DatabrickHive
1 -
DatabrickJobRunTime
1 -
databricks
86 -
Databricks Academy
29 -
Databricks Account
10 -
Databricks Account API
2 -
Databricks Alerts
12 -
Databricks api
12 -
Databricks Audit Logs
1 -
Databricks Auto-Loader
2 -
Databricks autoloader
12 -
Databricks aws
3 -
Databricks Badge
3 -
Databricks Certificate
1 -
Databricks Certification
15 -
DataBricks Certification Exam
2 -
Databricks Certified
13 -
Databricks Certified Data Engineer Professional
2 -
Databricks cli
14 -
Databricks cloud
4 -
Databricks Cluster
69 -
Databricks Cluster Failure
2 -
Databricks Clusters
11 -
Databricks Code
2 -
Databricks Community
32 -
Databricks community edition
31 -
Databricks Community Edition Account
4 -
Databricks Community Post
2 -
Databricks Community Rewards
2 -
Databricks Community Rewards Store
4 -
Databricks Community Version
2 -
Databricks connect
9 -
Databricks Control Plane
3 -
Databricks Course
2 -
Databricks Customers
1 -
Databricks Dashboard
5 -
Databricks Data Analyst Associate Cer
1 -
Databricks Data Engineer Associate
4 -
Databricks Data Engineering Associate
4 -
Databricks Database
2 -
Databricks dbfs
5 -
Databricks delta
14 -
Databricks Delta Table
3 -
Databricks Documentation
1 -
Databricks E2
2 -
Databricks Environment
15 -
Databricks Error Message
4 -
DataBricks Extension
6 -
Databricks Feature Store
4 -
Databricks Fundamentals
2 -
Databricks IDE
3 -
Databricks Instance
5 -
Databricks Integration
2 -
Databricks Issue
5 -
Databricks JDBC
16 -
Databricks JDBC Driver
9 -
Databricks Job
33 -
Databricks JobAPIs
2 -
Databricks jobs
21 -
Databricks Jobs Connection Timeout
2 -
Databricks Lakehouse
6 -
Databricks Lakehouse Fundamentals
5 -
Databricks Lakehouse Fundamentals Accreditation
6 -
Databricks Lakehouse Fundamentals Badge
8 -
Databricks Lakehouse Platform
14 -
Databricks Lakehouse Platform Accreditation
4 -
Databricks Logs
4 -
Databricks Migration
2 -
Databricks Migration Tool
1 -
Databricks Mlflow
1 -
Databricks News
2 -
Databricks Nodes
2 -
Databricks notebook
156 -
Databricks Notebook Command
2 -
Databricks Notebooks
34 -
Databricks ODBC
5 -
Databricks Office Hours
12 -
Databricks Partner
7 -
Databricks Partner Academy
2 -
Databricks Platform
7 -
Databricks Premium
3 -
Databricks Pricing
2 -
Databricks Pyspark
2 -
Databricks Python Notebook
1 -
Databricks Quickstart Cloudformation Error
3 -
Databricks Repo
6 -
Databricks Repos
30 -
Databricks Repos Api
4 -
Databricks Resources
4 -
Databricks rest api
6 -
Databricks run time version
4 -
Databricks Runtime
67 -
Databricks secrets
4 -
Databricks Service Account
5 -
Databricks spark
4 -
Databricks Spark Certification
5 -
Databricks SQL
193 -
Databricks SQL Alerts
4 -
Databricks SQL Analytics
1 -
Databricks SQL Connector
4 -
Databricks SQL Dashboard
4 -
Databricks SQL Dashboards
4 -
Databricks SQL Endpoints Runtime
2 -
Databricks SQL Permission Problems
1 -
Databricks Sql Serverless
4 -
Databricks SQL Visualizations
2 -
Databricks SQL Warehouse
4 -
Databricks Support
2 -
Databricks table
7 -
Databricks Tables
2 -
Databricks Team
6 -
Databricks Terraform
4 -
Databricks Terraform Provider Issues
2 -
Databricks Token
2 -
Databricks Training
2 -
Databricks UI
8 -
Databricks Unity Catalog
4 -
Databricks upgrade
2 -
Databricks Usage
2 -
Databricks User Group
1 -
Databricks Users
2 -
Databricks V2
5 -
Databricks V3
2 -
Databricks version
3 -
Databricks Web
2 -
Databricks Workflow
4 -
Databricks Workflows
13 -
Databricks workspace
54 -
Databricks-cli
8 -
Databricks-connect
25 -
Databricks-sql-connector
2 -
DatabricksAcademy
5 -
DatabricksAPI
1 -
DatabricksAuditLog
1 -
DatabricksAWSAccount
1 -
DatabricksCache
1 -
DatabricksCLI
1 -
DatabricksClusterAutoscaling
1 -
DatabricksClusterCreation
2 -
DatabricksClusterDeltaTables
1 -
DatabricksClusterInitScripts
1 -
DatabricksClusterManager
1 -
DatabricksClusterMetrics
1 -
DatabricksContainer
3 -
DatabricksDefaultCluster
1 -
DatabricksEBS
1 -
DatabricksEMR
1 -
DatabricksEncrypt
1 -
DatabricksEncryption
1 -
DatabricksFunctions
1 -
DatabricksGanglia
1 -
DatabricksJobCluster
2 -
DataBricksJobOrchestration
1 -
DatabricksJobRunTime
1 -
DatabricksJobs
30 -
DatabricksJobsAPI
1 -
DatabricksJobsUI
1 -
DatabricksLog4J
1 -
DatabricksNotebook
29 -
DatabricksRuntime
5 -
DatabricksSecretes
1 -
DatabricksVPC
1 -
DatabricksWorkflows
5 -
DatabricksWorkspace
2 -
Databrics Notebook
2 -
DataCache
1 -
DataCatalog
2 -
DataCleanroom
1 -
Datadog
7 -
DataExplorer
1 -
DataFabric
1 -
Dataframe
105 -
Dataframe Rows
2 -
Dataframes
43 -
Dataframes API
2 -
Datagrip
1 -
Datalake
13 -
DataLakeGen2
1 -
Dataloss
2 -
DataObjects
1 -
DataPersistence
1 -
DataQuality
1 -
Dataset
11 -
Datasets
5 -
DataSkipping
1 -
Datasource
2 -
DataSourceV2
2 -
DataStorage
3 -
DataStreaming
1 -
Datatype
7 -
DataVisualization
1 -
Date
25 -
Date Column
4 -
Date Field
4 -
Dateadd
1 -
DateFunction
2 -
DateGraph
1 -
DateParameter
1 -
DatePartition
1 -
Datepicker
1 -
DateSchema
1 -
DateStrings
1 -
Datetime
1 -
DatetimeColumns
1 -
DatetimeError
1 -
DatetimeFilter
1 -
DateValue
1 -
DB
2 -
DB Academy
2 -
DB Connect
7 -
DB Experts
1 -
DB Notebook
6 -
DB Runtime
2 -
Dbc
5 -
DBC File
3 -
DBCluster
2 -
DBCSQL
1 -
DBeaver
4 -
DBeaverIntegration
1 -
DBFS
66 -
Dbfs - databricks file system
11 -
DBFS File Browser Error
2 -
DBFS FileStore
6 -
DBFS Rest Api
1 -
DBFS Root
3 -
DBFSRoot
1 -
DBIO File Fragments
2 -
DBR
57 -
DBR 7
2 -
DBR 9.1
4 -
DBR Versions
6 -
DBRuntime
1 -
DBSQL
10 -
Dbsqlcli
3 -
Dbt
5 -
Dbu
9 -
DBU Consumption
2 -
Dbutils
30 -
Dbutils.fs.ls
4 -
Dbutils.notebook.run
4 -
Dbx
10 -
DDL
6 -
DDP
1 -
DE
4 -
Deadline
2 -
Dear Community
2 -
Dear Experts
2 -
Debug
2 -
December
3 -
Decimal
4 -
DecimalDataType
5 -
DECLARE
2 -
Deep Clone
2 -
Deep learning
4 -
DeepLearning
1 -
Default Cluster
2 -
Default Location
3 -
Default Python Functions
2 -
Default Query
2 -
Default Value
5 -
Delete
8 -
Delete File
4 -
Delete Table
2 -
Delete User
2 -
Delete Users
2 -
DeleteTags Permissions
1 -
Delt Lake
45 -
Delta
463 -
Delta Cache
4 -
Delta Clone
3 -
Delta engine
3 -
Delta File
3 -
Delta Files
6 -
Delta Format
12 -
Delta History
3 -
Delta Lake
287 -
Delta Lake Files
2 -
Delta Lake On Databricks
1 -
Delta Lake Stream Processing.
2 -
Delta lake table
12 -
Delta Lake Upsert
2 -
Delta Live
10 -
Delta Live Pipeline
3 -
Delta Live Table Pipeline
6 -
Delta Live Table Pipelines
2 -
Delta Live Tables
94 -
Delta Live Tables Quality
2 -
Delta log
7 -
Delta Log Folder
2 -
Delta Pipeline
4 -
Delta Schema
1 -
Delta Sharing
14 -
Delta STREAMING LIVE TABLE
3 -
Delta table
243 -
Delta Table Column
2 -
Delta Table Mismatch
2 -
Delta Table Storage
2 -
Delta Tables
54 -
Delta Time Travel
2 -
Delta-lake
7 -
DeltaCatalog
1 -
DeltaLake
10 -
DeltaLiveTable
1 -
DeltaLog
5 -
Deploy
7 -
Deployment
6 -
DESC
2 -
DESCRIBE DETAIL
2 -
Deserializing Arrow Data
3 -
Design pattern
2 -
Details
2 -
Dev
7 -
Developer
2 -
Developer Foundations Capstone
2 -
Development
2 -
Devops
6 -
DevOps Team
2 -
Df
2 -
Did Not Receive Voucher
1 -
Difference
17 -
Different Account
1 -
Different Environments
2 -
Different Instance Types
1 -
Different Notebook
2 -
Different Notebooks
4 -
Different Number
2 -
Different Parameters
4 -
Different Results
3 -
Different Schema
4 -
Different Tables
2 -
Different Types
5 -
Dir }
2 -
Directory
7 -
Disable
2 -
Disaster recovery
1 -
Disk
2 -
Display
18 -
Display Command
2 -
Displayhtml
5 -
Displaying
2 -
Distinct
2 -
Distinct Values
5 -
Distribution
2 -
DLT
162 -
DLT Pipeline
34 -
DLT Pipelines
4 -
DLTAutoloaderCredentials
1 -
DLTCluster
1 -
DLTDataPlaneException
1 -
DLTDataQuality
1 -
DLTIntegration
1 -
DLTNotebook
1 -
DLTs
3 -
DLTSchema
1 -
DLTSecurity
1 -
DML
6 -
Dns
5 -
Docker
14 -
Docker File
2 -
Docker image
14 -
Dockerized Cluster
2 -
Documentation
20 -
Dolly
1 -
Dolly Demo
1 -
Double
2 -
Download
4 -
Download files
2 -
Downloading Files
2 -
Driver
16 -
Driver Error
2 -
DRIVER Garbage Collection
2 -
DriverIP
1 -
DriverLogs
5 -
DriverNode
3 -
Drop Column
2 -
Drop table
3 -
Duplicate Records
3 -
Duplicate Rows
2 -
DW
2 -
Dynamic
4 -
Dynamic Data Masking Functionality
2 -
Dynamic Partition
2 -
Dynamic Queries
2 -
Dynamic Variables
3 -
E2
3 -
E2 Architecture
2 -
E2 Workspace
5 -
Easy Way
4 -
EBS
6 -
EBSVolumes
1 -
EC2
6 -
EC2Instance
1 -
Efficient Way
2 -
Elasticsearch
2 -
Email
10 -
Emr
5 -
Encrypt
2 -
Encryption
5 -
Encyption
4 -
End Date
3 -
End Time
3 -
Endpoint
11 -
Enhanced Autoscaling
2 -
Entry Point
2 -
Environment Variable
2 -
Environment variables
2 -
Eof
1 -
EphemeralCluster
1 -
EphemeralJob
1 -
EphemeralNotebookJobs
1 -
Epoch
1 -
ERP
2 -
Error
178 -
Error Code
10 -
Error Column
2 -
Error Details
2 -
Error handling
3 -
Error Message
62 -
Error Messages
4 -
Escape Character
3 -
ETA
3 -
ETL
27 -
Etl Batch Jobs
2 -
ETL Pipelines
2 -
ETL Process
3 -
Event
4 -
EventBridge
1 -
Eventhub
12 -
Eventlogs
2 -
Exam
13 -
Exam Vouchers
3 -
Example
6 -
Excel
16 -
excel xlsx xls
2 -
Exception
13 -
Exception Handling
6 -
Execution Context
2 -
Executor Heartbeat
2 -
Executor Logs
3 -
Executor Memory
3 -
Exists
3 -
Expectations
2 -
Experiments
2 -
Explode
2 -
ExportError
1 -
Extension
5 -
External Command
2 -
External Data Sources
1 -
External Hive
2 -
External Metastore
4 -
External Sources
3 -
External Table
11 -
External Tables
6 -
Extract
4 -
Fact Tables
1 -
Fail
3 -
FAILED
5 -
Failure
9 -
FAQ
1 -
FastAPI
1 -
Fatal Error
3 -
Feature
8 -
Feature Lookup
1 -
Feature request
3 -
Feature Store
12 -
Feature Store Table
2 -
Feature Table
4 -
Feature Tables
1 -
Featured Member
1 -
Features
4 -
FeatureStore
1 -
Field Names
2 -
File
92 -
File Notification
2 -
File Notification Autoloader
2 -
File Notification Mode
5 -
File Path
4 -
File Size
3 -
File Trigger
2 -
File upload
2 -
Filenotfoundexception
3 -
Files
58 -
Files In Repos
2 -
Filestore
8 -
Filesystem
4 -
Filter
11 -
Filter Condition
2 -
Find
12 -
Fine Grained Access
2 -
Fine Tune Spark Jobs
1 -
Firefox
2 -
Firewall
4 -
Fivetran
6 -
Flat File
2 -
Fm World Shop
2 -
Folder
3 -
Folder Path
2 -
Folder Structure
2 -
Folders
5 -
Font Size
2 -
Forbidden
2 -
Ford Fiesta
2 -
Foreachbatch
7 -
Foreachpartition
5 -
Forgot Password
1 -
Form Recognizer
2 -
Format
4 -
Format Issue
3 -
FORMAT OPTIONS
2 -
Format String
2 -
Formatting
1 -
Formatting Options
2 -
Free Databricks
1 -
Free trial
1 -
Free Voucher
7 -
friendsofcommunity
3 -
Fs
5 -
FSCK REPAIR
3 -
Function
28 -
Functions
13 -
Fundamentals
13 -
Fundamentals Accreditation
6 -
Fundamentals Certificate
1 -
Fundamentals Certification
1 -
GA
3 -
GAM
2 -
Ganglia
6 -
Ganglia Metrics
1 -
GangliaMetrics
1 -
Garbage Collection
6 -
Garbage Collection Optimization
1 -
Gc
3 -
GCP
24 -
GCP Databricks
6 -
GCP Support
1 -
Gcs
7 -
Gdal
1 -
Gdpr
2 -
GENERATED ALWAYS
3 -
GENERATED ALWAYS AS IDENTITY
4 -
GeojsonFile
1 -
GeopandasDataframe
1 -
Getting started
4 -
Gift Certificate
3 -
Git
12 -
Git Integration
3 -
Git Repo
4 -
Github
15 -
Github actions
3 -
Github integration
3 -
Github Repo
2 -
Gitlab
7 -
GitlabIntegration
1 -
GKE
2 -
Global
1 -
Global Init Script
5 -
Global init scripts
3 -
Global Temp Views
1 -
Global Temporary View
2 -
Glue
1 -
Golang
3 -
Gold Table
3 -
GoldLayer
5 -
Good Documentation
1 -
Google
20 -
Google Bigquery
2 -
Google cloud
4 -
GoogleAnalytics
1 -
GoogleBigQuery
1 -
Governance
1 -
Gpu
10 -
Grafana
2 -
Grant
4 -
Graph
5 -
Graphframes
3 -
GraphQL
1 -
Graphx
2 -
GraphX GraphFrames
2 -
Graviton
2 -
Great Expectations
2 -
GREY CUP
2 -
Gridsearchcv
2 -
Group
2 -
Group Entitlements
1 -
Group-by
2 -
Groupby
5 -
Groupby Window Queries
2 -
Groups
5 -
Gui
3 -
Guide
6 -
Gzip
2 -
H2o
2 -
Hadoop
6 -
HBase
3 -
HDInsight
1 -
Header
2 -
Heading
2 -
Heap
2 -
Heap dump
2 -
Help
15 -
Help Check
2 -
Heroku Kafka
2 -
Hi
9 -
High Concurrency
5 -
High Concurrency Cluster
8 -
HighConcurrencyCluster
1 -
Higher Environments
2 -
HIPAA
3 -
History
6 -
Hive
21 -
Hive metastore
11 -
Hive Metastore Of Databricks
1 -
Hive Table
4 -
HMS
1 -
Horovod
3 -
Href
2 -
Html
9 -
Html Files
1 -
HTML Format
3 -
Http
3 -
Https
2 -
Hudi
1 -
Huge Data
2 -
Hyperopt
5 -
Hyperparameter Tuning
5 -
Iam
5 -
IBM
2 -
Iceberg
5 -
Ide
6 -
IDE Dev Support
7 -
Idea
3 -
Identity Column
13 -
IDM
1 -
Ignite
3 -
Illegal Character
2 -
ILT
1 -
ILT Session
1 -
Image
5 -
Image Data
3 -
Implementation Patterns
2 -
Import
27 -
Import notebook
5 -
Import Pandas
4 -
Importing
3 -
Include
3 -
Incremental
3 -
Incremental Data
3 -
Index
2 -
Industry Experts
1 -
Inference Setup Error
1 -
INFORMATION
3 -
Ingestion
4 -
Init
4 -
Init script
26 -
Init Scripts
12 -
Inner join
2 -
Input
3 -
Insert
5 -
Insert Overwrite
2 -
Installation
1 -
Instance Pool
2 -
Instance Profile
6 -
Instances
2 -
InstanceType
1 -
Int
9 -
Integer
2 -
Integration
7 -
Integrations
3 -
Intellij
2 -
Interactive cluster
10 -
Interactive Clusters
1 -
Interactive Mode
2 -
Internal error
6 -
Internal Metastore
2 -
Interval
2 -
INTERVAL DAY TO SECOND
2 -
Invalid Batch
2 -
Invalid Email Address
1 -
INVALID PARAMETER VALUE
3 -
INVALID STATE
1 -
Invalid Type Code
2 -
IP
6 -
IP Access
2 -
IP Access List
4 -
IP Addresses
2 -
IPAccessList
2 -
IPRange
1 -
Ipython
3 -
IPython Version
2 -
Ipywidgets
7 -
Jar
11 -
JAR Library
4 -
Jar Scala
3 -
Jars
3 -
Java
19 -
Java version
2 -
Java.lang.NoSuchMethodError
2 -
Javapackage
3 -
Jdbc
37 -
Jdbc connection
12 -
JDBC Connections
4 -
JDBC Connector
4 -
Jdbc driver
17 -
Jira
1 -
JKS
1 -
JMS
1 -
JMX
1 -
Job
92 -
Job Cluster
25 -
Job clusters
9 -
Job Definition
2 -
Job Orchestration
3 -
Job Parameters
6 -
Job Run
10 -
Job Runs
2 -
Job scheduling
3 -
Job Task
2 -
Job_clusters
2 -
JobAPI
1 -
JobCluster
1 -
Joblib
3 -
JOBS
89 -
Jobs & Workflows
31 -
Jobs api
27 -
Jobs Api Feature
2 -
Jobs Cluster
2 -
Join
9 -
Joins
4 -
JSON
47 -
JSON Data
2 -
Json Extract
2 -
JSON Files
14 -
Json Format
3 -
JSON Object
4 -
JSON Schema Config File
2 -
Jsonfile
9 -
Jupyter
4 -
Jupyternotebook
17 -
Jvm
8 -
JVMError
1 -
K8s
1 -
Kafka
37 -
Kafka consumer
2 -
Kafka Stream
3 -
Kafka streaming
2 -
Kafka Topic
4 -
Kaniz
2 -
KB
4 -
Kedro
1 -
Kerberos
3 -
Key
12 -
Key Management
1 -
Key Vault
2 -
Kinesis
1 -
Kinesis and spark streaming
2 -
Kinesis Stream
2 -
Kmeans
1 -
KMS
1 -
Koalas
8 -
Koalas Dataframe
3 -
Kolkata
1 -
Lakehouse
37 -
Lakehouse Fundamentals
12 -
Lakehouse Fundamentals Accreditation
5 -
Lakehouse Fundamentals Badge
7 -
Lakehouse Fundamentals Certificate
2 -
Lakehouse Fundamentals Certification
2 -
Lakehouse Fundamentals Quiz
1 -
Lakehouse Fundamentals Training
5 -
Lambda
2 -
Large Datasets
1 -
Large Language Model
1 -
Large Number
3 -
Large Volume
2 -
Large XML File
2 -
LatencyAPI
1 -
Latest Version
1 -
Launch Failure
3 -
Learning
3 -
Learning Material
1 -
Libraries
18 -
Libraries Installation
2 -
Library
21 -
Library Installation
6 -
LIBRARY INSTALLATION FAILURE
2 -
Light
2 -
Limit
4 -
Line
3 -
Lineage
3 -
LineageExtraction
1 -
Linear regression
1 -
Link
7 -
Linkedin
3 -
List
17 -
Live Connection SQL Datawarehouse
2 -
Live Q&A
2 -
Live Table
9 -
Live Table Schema Comment
2 -
Live Tables
8 -
Live Tables CDC
3 -
LLM
4 -
Load
7 -
Load data
7 -
Loading
5 -
Local computer
3 -
Local Development
2 -
Local file
4 -
Local Files
2 -
Local Machine
4 -
Local System
2 -
Location
7 -
Locations
1 -
Log
14 -
Log Analytics
3 -
Log Model
1 -
Log4j
6 -
LogError
1 -
LogEvents
1 -
LogFiles
1 -
Logging
10 -
Login
9 -
Login Account
2 -
Login Issue
2 -
Login Sessions
2 -
Logistic regression
1 -
LogJobs
1 -
LogLevel
1 -
LogPickleFiles
1 -
LogRetention
1 -
Logs
13 -
Long Delay
1 -
Long Time
11 -
Loop
9 -
Low Cost
2 -
Lower Case
3 -
LTS
41 -
LTS ML
4 -
LTS Version
2 -
M1 Macbookpro
2 -
Machine
2 -
Machine Learning
20 -
Machine Learning Associate
2 -
Magic Command
7 -
Magic Commands
5 -
Main Contact Page
1 -
Main Notebook
4 -
MALFORMED REQUEST
4 -
Managed Resource Group
2 -
Managed Table
4 -
ManagedInstance
1 -
Managedtables
1 -
Management
1 -
Map
7 -
Map Markers
2 -
Markdown
6 -
Markdown Cells
2 -
Market Place
2 -
Masking Data Column
2 -
Master Notebook
2 -
Materialized Tables
2 -
Matillion
1 -
Matplotlib
5 -
Maven
20 -
Maven Artifact
2 -
Maven Central
2 -
Maven Libraries
4 -
Max Number
2 -
Max Retries
3 -
Maximum Number
4 -
Medallion Architecture
7 -
Memory
11 -
Memory error
4 -
Memory management
2 -
Memory Size
3 -
Merge
24 -
Merge Into
1 -
MERGE Performance
5 -
MERGE Statement
3 -
MessageCluster
1 -
MessageQueue
1 -
MessagesFlow
1 -
Metadata
7 -
Metadata File
2 -
Metastore
19 -
Method
9 -
Method Public
1 -
Metrics
6 -
MicroBatch
2 -
Microsoft
25 -
Microsoft azure
3 -
Microsoft Azure Active Directory
2 -
Microsoft sql server
3 -
Microsoft Teams
1 -
MicrosoftPurview
1 -
Microstrategy
3 -
Migration
11 -
MigrationHub
1 -
Missing
3 -
ML
3 -
ML Runtime
3 -
MLDeployment
1 -
MlFlow
37 -
MLflow API
1 -
MLflow Experiment
2 -
MLflow Experiments
3 -
Mlflow Model
4 -
Mlflow project
1 -
Mlflow Run
3 -
Mlflow Server
1 -
Mllib
5 -
Mlops
2 -
MLProduction
1 -
MLUseCases
1 -
Model
21 -
Model Deployment
7 -
Model Drift
2 -
Model Lifecycle
2 -
Model Monitoring
1 -
Model registry
4 -
Model Serving
7 -
Model Serving REST API
1 -
Model Training
4 -
Model Tuning
1 -
Model Version
2 -
Models
4 -
Module
6 -
Modulenotfounderror
4 -
Modules
3 -
Monaco
2 -
MongoDB
6 -
MongoDB Server
2 -
Mongodb-spark-connector
2 -
Monitoring
8 -
Monitoring and Visibility
7 -
Month
2 -
Mount
15 -
Mount Point
6 -
Mount point data lake
3 -
Mount points
3 -
Mounting-azure-blob-store
2 -
Mountpoints Definitions
3 -
Mounts
2 -
MQConnector
1 -
MS SQL Server
4 -
MsAccess
2 -
MSAzure
1 -
MSC
1 -
MSExcel
1 -
Mssql
4 -
MssqlConnector
1 -
Multi
5 -
Multi Cluster Load Balancer
1 -
Multi-Task Job
3 -
Multiline
2 -
Multiple
2 -
Multiple Cells
2 -
Multiple Dependent Jobs
2 -
Multiple Jobs
5 -
Multiple Notebooks
2 -
Multiple Queries
3 -
Multiple Sources
3 -
Multiple Spark
2 -
Multiple Tabs
2 -
Multiple Tasks
8 -
Multiple Times
2 -
Multiple Versions
2 -
Multiple workspaces
1 -
Multiple-files
2 -
Multiprocessing
2 -
Multiselect
2 -
MultistageJobs
1 -
Mysql
7 -
MySQLDB
3 -
MySQLServer
1 -
NamedParameters
2 -
Narrow Transformation
2 -
Navigational Pane
3 -
Neo4j
1 -
Neo4j Aura
2 -
Nested
2 -
Nested array struct dataframe
2 -
Nested json
3 -
Network Security
3 -
Networking
5 -
NetworkSecurityGroup
2 -
NeuralNetwork
1 -
New
8 -
New Account
3 -
New Cluster
10 -
New Column
8 -
New Connection
2 -
New Data
5 -
New Databricks Driver
2 -
New Feature
4 -
New Features
6 -
New File
3 -
New Group
2 -
New Job
4 -
New Jobs
2 -
New LMS Migration
2 -
New Metastore
2 -
New Project
2 -
New Releases
2 -
New Rows
3 -
New Table
4 -
New User
3 -
New Workspace
9 -
Newbie
2 -
Nlp
2 -
Nodes
3 -
Note
1 -
Notebook
136 -
Notebook Cell
7 -
Notebook Cell Output Results
2 -
Notebook Context
2 -
Notebook Dashboard
3 -
Notebook Display Widgets
3 -
Notebook Level
2 -
Notebook Names
2 -
Notebook Path
6 -
Notebook Results
2 -
Notebook Run
5 -
Notebook Task
5 -
Notebook Tasks
2 -
Notebooks
56 -
Notification
5 -
November Community Social
2 -
NPIP
3 -
Null
6 -
Null Value
3 -
Null Values
7 -
Nullpointerexception
2 -
Number
4 -
Numpy Arrays
2 -
Nutter
2 -
Oauth
2 -
Object
13 -
Object Storage
2 -
Object Type
1 -
Odbc
22 -
Odbc Connection
2 -
Office Hours
8 -
OLAP
1 -
Old Versions
2 -
Older Version
2 -
OLTP
2 -
OLTPConnector
1 -
On-premises
2 -
Onboarding
9 -
Online Feature Store Table
1 -
Online Training
2 -
OOM Error
5 -
Open Source Spark
2 -
OpenAI
1 -
Operation
10 -
Optimisation
1 -
Optimization
7 -
Optimize
25 -
Optimize Command
9 -
Optimizing For Cost
2 -
Options
5 -
Oracle
14 -
OracleDBPackage
3 -
Orchestrate Data Bricks Jobs
2 -
Orchestration
2 -
Order By
3 -
Organize
1 -
Original Notebook
2 -
OSS
4 -
Out-of-memory
2 -
Output
6 -
Overwrite
3 -
Owner
2 -
Package
14 -
Packages
3 -
Paid Trainings
3 -
Pakistan
3 -
Pandas
30 -
Pandas API
2 -
Pandas Code
2 -
Pandas dataframe
20 -
Pandas Python
3 -
Pandas udf
5 -
Pandas_udf
3 -
Paper
1 -
Paper Airplane
2 -
Parallel
2 -
Parallel notebooks
3 -
Parallel processing
8 -
Parallel Runs
2 -
Parallelisation
2 -
Parallelism
3 -
Parameter
8 -
PARAMETER VALUE
5 -
Parameters
10 -
Parquet
36 -
Parquet File
14 -
Parquet file writes
4 -
Parquet files
24 -
Parquet Format
2 -
Parquet Table
5 -
Parquet Type
2 -
Parser
3 -
Parsing
2 -
Particular Cluster
2 -
Partition
17 -
Partition Column
4 -
Partition Columns
3 -
Partition Filter
3 -
Partition Pruning
3 -
Partitioning
9 -
Partitions
12 -
Partner Academy
4 -
Party Libraries
1 -
Pass
5 -
Password
15 -
Password Reset Link
3 -
PAT Token
3 -
Path
19 -
Path does not exist
2 -
Pattern
4 -
Pending State
2 -
Percentage Values
2 -
Performance
26 -
Performance Issue
4 -
Performance Issues
5 -
Performance Tuning
6 -
Permanent Views
2 -
Permission
1 -
Permission Control
2 -
Permissions
8 -
Persist
3 -
Persistent View
3 -
Personal access token
13 -
Petastorm
2 -
Photon
15 -
Photon Cluster
2 -
Photon Engine
6 -
Php
2 -
Physical Plan
3 -
Pickle
2 -
PII
2 -
Pip
10 -
Pipeline
8 -
Pipelines
5 -
Pivot
3 -
Pivot Function
2 -
Plan
3 -
Platform
5 -
Platform Administrator
1 -
Plotly
2 -
Plugin
1 -
POC
5 -
Points
4 -
Pool
2 -
Pools
5 -
Possible
10 -
Post
5 -
Postgres
5 -
Postgresql
3 -
Postgresql RDS
2 -
PostgresSQL
1 -
Power BI Connector
1 -
Power BI XLMA EndPoint
2 -
Power-bi
2 -
Powerbi
23 -
Powerbi Databricks
3 -
Powershell
2 -
Practice Exams
2 -
Practice Tests Details
1 -
Pre Requisite
2 -
Premium
3 -
Premium Tier
2 -
Premium Workspace
2 -
Presentation
2 -
Presto
3 -
Prevent Duplicate Entries
3 -
Previous Version
2 -
Primary Key
6 -
Primary Key Constraint
2 -
Print
6 -
Private Link
4 -
Private Network
6 -
Private Repo
2 -
Privilege
2 -
PROBLEM
12 -
Process List
2 -
Prod Workspace
1 -
Product Feedback
2 -
Product Manager
3 -
Production
2 -
ProductionJobs
1 -
Professional Data
1 -
Professional Data Engineer
1 -
Profile
3 -
Programming language
1 -
Project Lightspeed
2 -
Prometheus
2 -
Promotion Code Used
2 -
Property
3 -
Protobuf
2 -
Proven Practice
13 -
Public
5 -
Public IP
3 -
Public Preview
6 -
Purpose Cluster
5 -
Purpose Clusters
2 -
PW
2 -
Py File
7 -
Py4jjavaerror
5 -
Pyarrow
1 -
PyAudio
1 -
Pycaret
1 -
Pycharm
3 -
Pycharm IDE
1 -
Pydeequ
3 -
Pylint
1 -
Pyodbc
3 -
PyPI
3 -
Pypi Modules
2 -
Pysaprk dataframes
2 -
Pyspark
202 -
Pyspark Code
4 -
Pyspark Databricks
5 -
Pyspark Dataframe
56 -
Pyspark Dataframes
4 -
PySpark Error
3 -
Pyspark job
2 -
PySpark Jobs
2 -
Pyspark Scripts
2 -
Pyspark Session
2 -
Pyspark Spark Listener
3 -
PySpark UDF
2 -
Pyspark.pandas
2 -
PysparkML
1 -
PySparkOptimization
1 -
Pytest
3 -
Python
242 -
Python API
2 -
Python Code
11 -
Python Dataframe
2 -
Python Dictionary
4 -
Python Error
1 -
Python File
3 -
Python Function
6 -
Python Kernel
7 -
Python Libraries
4 -
Python Library
5 -
Python notebook
17 -
Python Notebooks
4 -
Python package
5 -
Python Packages
1 -
Python programming
1 -
Python Project
2 -
Python Proxy
1 -
Python script
10 -
Python Task
1 -
Python Variables
2 -
Python Wheel
6 -
Python Wheel Task
5 -
Python3
8 -
PythonGraph
1 -
PythonImportError
1 -
PythonJob
1 -
Pytorch
3 -
Q2
2 -
Query
46 -
Query Data
3 -
Query Editor
3 -
Query Execution Plan
2 -
Query History
6 -
Query Limit
3 -
Query Parameters
2 -
Query Plan
2 -
QUERY RESULT ROWS
3 -
Query Results
4 -
Query Snippets
1 -
Query Table
5 -
Query Tables
2 -
QUERY_RESULT_ROWS
2 -
Question
15 -
Quickstart
2 -
R
18 -
R Shiny
1 -
Rakesh
2 -
Ram
1 -
Random Error
2 -
Randomforest
1 -
Rate Limits
1 -
Ray
5 -
RDataFrame
1 -
Rdd
24 -
Rds
2 -
Read
15 -
Read data
4 -
Read from s3
3 -
Read Table
2 -
Read write files
2 -
ReadCSV
1 -
Reading
11 -
Readstream
4 -
Real Data
2 -
Real Estate
2 -
Real Time
5 -
Real time data
4 -
Real Time Model Serving
2 -
REATTEMPT
3 -
Records
5 -
Recursive Calls
2 -
Recursive Cte
2 -
Redis
1 -
Redshift
9 -
Regex
3 -
Region
1 -
ReinforcementLearning
1 -
Relative Path
2 -
ReleaseNotes
1 -
Remote connection integration client
2 -
Remote Repository
2 -
Remote RPC Client
2 -
Remove
3 -
REPAIR TABLE
2 -
Repartitioning
4 -
Repl
4 -
Repos
33 -
Repos API
2 -
Repos REST API
2 -
Repos Support
2 -
Repos Work
2 -
Repository
5 -
Reset
2 -
Resource Group
2 -
Rest
3 -
Rest API
66 -
Rest-api
2 -
RESTAPI
4 -
Restart
6 -
Restart Cluster
2 -
Restore
2 -
Result
5 -
Result Rows
2 -
Retention Period
1 -
Return
2 -
Return value
4 -
Reward Points
3 -
Reward Store
2 -
Rewards Points
1 -
Rewards Portal
2 -
Rewards Store
3 -
Rgdal
1 -
Riley Phillips - Enterprise
1 -
RInDatabricks
1 -
rm command
1 -
Rmysql
2 -
Roadmap
1 -
Rocksdb
2 -
Rollback Error
2 -
Root Bucket
3 -
Root Cause
3 -
Root Directory
1 -
Root Path
1 -
ROOT_DIR
2 -
Row
7 -
Row level
1 -
Row Level Security
4 -
Row Values
1 -
Row_number()
1 -
RPackage
1 -
Rpc
4 -
RPC Disassociate Error
1 -
Rstudio
2 -
Run
38 -
Run Cell
2 -
Run Command
3 -
Run Date
2 -
RUN ID
1 -
Run Notebook
2 -
Run Now
2 -
Running notebook in databricks cluster
2 -
Runs
4 -
Runtime
13 -
Runtime 10.4
8 -
Runtime 11.3
3 -
Runtime Error
1 -
Runtime SQL Endpoints
1 -
Runtime Support
1 -
Runtime update
1 -
Rust
1 -
Rust Support
1 -
Rversion
1 -
S3
25 -
S3 Location
2 -
S3 Path
2 -
S3 permission
1 -
S3 Storage Files
1 -
S3 Supported
2 -
S3 With Python
1 -
S3bucket
11 -
SA
1 -
Sagemaker
1 -
Sagemaker Endpoint
1 -
Salesforce
7 -
Sample Code
3 -
Sample Data UI View
1 -
Sanjay
2 -
SAP
5 -
Sap Hana Driver
2 -
Sas
6 -
SASL SSL
2 -
SAT
2 -
Save
2 -
Scala
72 -
Scala 2.12
1 -
Scala API
1 -
Scala Application Jar
2 -
Scala Code
3 -
Scala Connectivity
1 -
SCALA DATABRICKS
1 -
Scala Function
3 -
Scala Language
1 -
Scala Libraries
1 -
Scala notebook
11 -
Scala Script
1 -
Scala spark
13 -
Scala spark mllib
1 -
Scala Spark Project
1 -
Scala UDF
1 -
Scala Version
1 -
Scalable Machine Learning
2 -
ScalaDriverLocal
1 -
Scalar Iterator Pandas UDF
2 -
Scalatest
1 -
Scaling
2 -
SCD
1 -
SCD Type
2 -
Scd Type 2
2 -
Schedule
2 -
Schedule Cron Expression
3 -
Schedule Job
2 -
Schedule Reload
1 -
Scheduler
1 -
Scheduling
2 -
Schema
29 -
Schema Change
1 -
Schema Check
1 -
Schema Enforcement
1 -
Schema Evaluation
1 -
Schema evolution
8 -
Schema Evolution Issue
3 -
Schema from metadata
1 -
Schema Information
1 -
Schema registry
2 -
Scikit
1 -
Scikit-learn
3 -
SCIM API
3 -
SCIM API OpenAPI
1 -
Scope
3 -
Scope Creation
1 -
Scope Credentials
1 -
Scoped Init Script
3 -
Score Jar File
1 -
Screen Option
1 -
Script
3 -
Script Exit Status
1 -
SDK
4 -
Seaborn
1 -
Search
4 -
Search Function
1 -
Secret
2 -
Secret scope
2 -
Secret Scopes
5 -
Secret Value
1 -
Secrets
8 -
Secrets API
2 -
Secrets Scope
1 -
Secure Private Access
1 -
SecureConnection
1 -
Security
24 -
Security Analysis Tool
3 -
Security Controls
2 -
Security Design
1 -
Security Exception
1 -
Security Group
3 -
Security Patterns
1 -
Security Requirement
1 -
Security Review
1 -
Security Threats
1 -
Sedona
3 -
Sedona Geo
1 -
Seldon Core
1 -
Select
2 -
SELECT COUNT
1 -
SELECT DISTINCT
1 -
SELECT Permissions
2 -
Selectexpr
1 -
Selenium
4 -
Selenium Chrome Driver
1 -
Selenium Webdriver
2 -
Selenium-webdriver
1 -
Self Paced Data Engineering
1 -
Selfpaced Course
2 -
Selfpaced Course Link
1 -
Semantic Layer
1 -
Semi-structured Data
1 -
Semicon Solutions
1 -
Separate Dbt Processes
1 -
Separate Filters
1 -
Serialization
3 -
Server
1 -
Server Hostname
2 -
Serverless
2 -
Serverless SQL Datawarehouse
1 -
Serverless SQL Datawarehouse Cluster
1 -
Serverless SQL Endpoints
4 -
Service
3 -
Service Account
2 -
Service principal
26 -
Service Principals
2 -
Service principle
4 -
Serving
1 -
Session
5 -
Set
13 -
SET ROW FILTER
1 -
SET Statement
1 -
SET Statements
2 -
Settings Button
1 -
Setup
7 -
Setup Audit Log Delivery
1 -
Setup Authentication
1 -
Setup databricks
2 -
Setup Process
1 -
Sf Username
12 -
SFTP
5 -
SFTP Location
2 -
Sftp Server
2 -
Shallow Clone
3 -
Shap
1 -
Shared Folder
2 -
Shared Key
1 -
Shared Mode
2 -
SharePoint
5 -
Sharepoint Lists
1 -
Sharing
4 -
Shell script
1 -
Shell variables
1 -
Shift Work
1 -
Shortcut
1 -
Shorter Duration
1 -
Show
2 -
SHOW Commands
1 -
Showcase Strength
1 -
Shuffle
4 -
Shuffle Partitions
2 -
Significant Performance Difference
1 -
Signup
1 -
Silicone Coated Cloth Gisinsulation
1 -
Silver Delta
1 -
Silver Tables
1 -
Simba
5 -
Simba jdbc
2 -
Simba ODBC Driver
3 -
Simba Spark
1 -
Simba Spark Driver
2 -
Simbasparkjdbc
2 -
SIMEX Bangladesh
1 -
Similar Case
1 -
Similar Deduplicate Values
1 -
Similar Issue
2 -
Similar Question
1 -
Similiar Issue
1 -
Simple Autoloader Job
1 -
Simple Classification Problem
1 -
Simple Comment
1 -
Simple Queries
2 -
Simple Query
1 -
Simple SQL Command
1 -
Simple Steps
1 -
Simple Terms
1 -
Single Cluster
1 -
Single CSV
1 -
Single CSV File
1 -
Single Node
5 -
Single User Access Permission
1 -
Single User Cluster Mode
1 -
Singleton Design Principle
1 -
Singular Week
1 -
Sink Connector
1 -
Site Bazel
1 -
Size
7 -
Skew
3 -
Skewdata
1 -
Skincare
1 -
Skip rows
1 -
Sklean
1 -
Sklean Pipeline
2 -
Sklearn
4 -
SKU
1 -
SLA
4 -
Slack Notification
1 -
Slice
1 -
Slots Full
1 -
Slow
5 -
Slow Imports
1 -
Slow Inference
1 -
Slow Nodes
1 -
Slow Performance
2 -
Slow response
1 -
Slowly Changing Dimension
2 -
Small Code
1 -
Small Data
1 -
Small Dataframes
2 -
Small Example
1 -
Small Files
5 -
Small files problem
1 -
Small FONT
1 -
Small Model
1 -
Small Parquet Files
1 -
Small Scale Experimentation
1 -
Smart City
1 -
Smart Solutions
1 -
Smolder
1 -
SMTP
1 -
Snowflake
16 -
Snowflake Connector
1 -
Snowflake Spark Connector
2 -
SnowflakeSparkConnector
1 -
Sns
1 -
Social Group
5 -
Social media
1 -
Social Networking Sites
1 -
Sockettimeoutexception
1 -
Software
2 -
Software 2.0
1 -
Software Development
2 -
Sort
2 -
Sorting
3 -
Source
5 -
Source Code
2 -
Source control
1 -
Source Control Dashboard
1 -
Source Data
3 -
Source Data Size
1 -
Source Error
1 -
Source File
1 -
Source Location Path
1 -
Source Paths
1 -
Source Systems
2 -
Source Table
6 -
Sourse Data
1 -
Soy Wax Melts
1 -
SP
1 -
Space
2 -
Spaces
3 -
Spacy Model
1 -
Spam Post
1 -
Spanish
1 -
Spark
623 -
Spark & Scala
3 -
Spark 2.1.0
1 -
Spark 3.2.0
1 -
Spark api
1 -
Spark application
3 -
Spark Application Code
1 -
Spark Applications
1 -
Spark Behavior
1 -
Spark Caching
2 -
Spark Catalog
1 -
Spark Certification Videos
1 -
Spark checkpoint
2 -
Spark Cluster
4 -
Spark Cluster Config Databricks
1 -
Spark Cluster Manager
1 -
Spark Cluster Monitoring
2 -
Spark Cluster UI
1 -
Spark Code
3 -
Spark config
14 -
Spark Config Settings
2 -
Spark Configuration
2 -
Spark Connect
2 -
Spark connector
1 -
Spark Course
1 -
Spark Crashes
1 -
Spark Data Frame Columns
1 -
Spark databricks
2 -
Spark Dataframe API
1 -
Spark Dataframe Row
1 -
Spark DataFrames
3 -
Spark DataFrames Verse DataFrames
1 -
Spark dataset
2 -
Spark developer certification
1 -
Spark Driver
14 -
Spark Driver Crash
1 -
Spark elasticsearch
1 -
Spark Error
1 -
Spark Eventlog
1 -
Spark Exe
1 -
Spark execution
1 -
Spark Failure Error
1 -
Spark History
1 -
Spark History Server
1 -
Spark Hours
1 -
Spark Image
1 -
Spark Issue Handling Data
1 -
Spark Java Job
1 -
Spark jdbc
1 -
Spark JDBC Query
2 -
Spark job
15 -
Spark jobs
2 -
Spark join
1 -
Spark Kmeans
1 -
SPARK LOCAL IP
1 -
Spark Local Mode
1 -
Spark Meetup
1 -
Spark Migration
1 -
Spark MLlib
5 -
Spark MLlib Models
1 -
Spark monitoring
4 -
Spark Nodes
1 -
Spark Notebook
1 -
Spark Odbc Connections
1 -
Spark oracle
1 -
Spark out of memory
1 -
Spark Package
1 -
Spark Pandas Api
3 -
Spark Pandas Code
1 -
Spark Performance
5 -
Spark Plan
1 -
Spark Plots
1 -
Spark Programming
1 -
Spark Properties Files
1 -
Spark Pushdown Filter
1 -
Spark Python Task
1 -
Spark Query
1 -
Spark redis
1 -
Spark Salesforce Library
1 -
Spark Save Modes
1 -
Spark scala
5 -
Spark sql
88 -
Spark SQL Catalyst
1 -
Spark SQL Query
1 -
Spark standalone cluster
1 -
Spark Stream
3 -
Spark Stream Job
1 -
Spark streaming
62 -
Spark Streaming Job
1 -
Spark Structure
1 -
Spark structured streaming
33 -
Spark Structured Streaming Application
1 -
Spark Submit Job
1 -
SPARK SUBMIT OPTS
1 -
Spark Synapse Connector
1 -
Spark Task
1 -
Spark Tasks
1 -
Spark Training Videos
1 -
Spark udf
2 -
Spark ui
16 -
Spark UI Simulator
2 -
Spark Version
4 -
Spark view
2 -
Spark Vs Spark
1 -
Spark Wht
1 -
Spark xml
1 -
Spark Yarn Cluster Mode
1 -
Spark--dataframe
12 -
Spark--ml
1 -
Spark--sql
6 -
Spark-2.0
3 -
Spark-csv
2 -
Spark-java
1 -
Spark-monitoring
1 -
Spark-nlp
1 -
Spark-postgres
1 -
Spark-redshift s3 redshift
1 -
Spark-shell
1 -
Spark-sql
27 -
Spark-streaming
3 -
Spark-submit
4 -
Spark-ui
1 -
Spark-xml
1 -
Spark.catalog.clearCache
1 -
Spark.kryoserializer.buffer.max
1 -
Spark.sql
1 -
Spark1.6
1 -
spark3
2 -
SparkCluster
2 -
Sparkconf
2 -
Sparkcontext
6 -
Sparkdataframe
19 -
SparkFiles
1 -
Sparkjar
1 -
Sparkjdbc42.jar
1 -
SparkJDBCDriver
1 -
Sparklistener
4 -
Sparklyr
3 -
Sparklyr Extension Work
1 -
Sparklyr Table
1 -
Sparkml
1 -
Sparknlp
1 -
Sparkr
6 -
SparkR Session
3 -
SparkRedshift
1 -
Sparks Apis
1 -
Sparks Notebook
1 -
Sparksession
5 -
SparkSQL Application Execution
1 -
Sparksubmit Type
1 -
SparkVersion
1 -
Sparse Data
1 -
Sparse Matrix
1 -
Special Characters
1 -
Specific Branch
1 -
Specific Cluster Policy
2 -
Specific Cluster Size
1 -
Specific Column
2 -
Specific Commit
1 -
Specific Container
2 -
Specific Endpoint
1 -
Specific Event Hub Partition
1 -
Specific File
1 -
Specific Folder
1 -
Specific Group
1 -
Specific Order
1 -
Specific Pydeeque Function
1 -
Specific Tasks
1 -
Specific Time
1 -
Specific User
1 -
Specific User Groups
1 -
Specific Version
1 -
Specific Workspace
1 -
Speculative Execution
1 -
Speculative Task
1 -
Speech Matching Scenario
1 -
Speed
1 -
Spill
3 -
Split
4 -
Split_part
1 -
Splunk
2 -
Splunk Monitoring
1 -
Spn
1 -
Sports
1 -
Spot
5 -
Spot Fleet Pools
1 -
Spot Instance
3 -
Spot instances
5 -
Spot Pools
1 -
Spot VM
1 -
Spotipy Import
1 -
SQL
389 -
SQL ACL
1 -
Sql alter table
1 -
SQL Analytics Dashboarding
3 -
SQL Analytics Query
1 -
SQL Cast Operator
1 -
SQL Cluster
2 -
SQL Code
4 -
SQL Command
3 -
SQL CONCAT
1 -
SQL Configuration
1 -
SQL Connector
3 -
SQL Connector Abstraction
1 -
SQL CONTAINS Function
1 -
SQL CTE
1 -
SQL Cursor
1 -
SQL Dashboard
8 -
SQL Dashboard Report
1 -
SQL Data
1 -
SQL Data File
1 -
Sql data warehouse
3 -
SQL DB
1 -
SQL Editor
5 -
SQL End
1 -
SQL Endpoint
15 -
SQL Endpoints
10 -
SQL Engine
1 -
SQL Error
1 -
SQL External Connections
1 -
Sql file
1 -
Sql Files
2 -
SQL Formatting
1 -
SQL Group
1 -
SQL Issues
1 -
SQL Merge
2 -
SQL Mode
1 -
SQL Notebook
3 -
SQL Notebooks
1 -
SQL Output
1 -
SQL Parameters
2 -
SQL Queries
15 -
Sql query
22 -
SQL Query Result Data
1 -
Sql Script
2 -
Sql Scripts
1 -
SQL SERVER + Sql
1 -
Sql Server Agent Job
1 -
Sql Server Agent Jobs
1 -
Sql server reporting services
1 -
Sql Server Tables
1 -
SQL Serverless
1 -
SQL Spark Databrick
1 -
SQL Statement
6 -
SQL Statements
2 -
Sql table
3 -
SQL Table Alias
1 -
SQL UI
1 -
Sql Update
1 -
SQL Variables
1 -
SQL View
2 -
SQL Visualizations
4 -
Sql Warehouse
28 -
SQL Warehouse Configuration
1 -
Sql Warehouse Endpoints
1 -
SQL Warehouse Serverless Endpoint
1 -
SQL Warehouse Tables
1 -
Sql Week Format Issue
1 -
Sql Wharehouse
2 -
SQL Workspace
1 -
SQLAlchemy ORM Connection
1 -
Sqlanalytics
4 -
Sqlcontext
3 -
Sqldatawarehouse
1 -
Sqlexecutionexception
1 -
Sqli
1 -
Sqlite
1 -
Sqlserver
18 -
SQLServerException Deadlock
1 -
SQLSTATE
1 -
Square Brackets
2 -
Square Brackets Results
1 -
SRC
1 -
Ssas-tabular
1 -
Ssh
5 -
Ssh Connection
1 -
Ssis
2 -
Ssis On Prem
1 -
Ssl
15 -
SSL Certification
1 -
SSL Error
2 -
Sslexception
1 -
SSMS
1 -
Sso
12 -
Ssrs
5 -
SSRS Connect
1 -
Sst Files
1 -
St Constructors
1 -
ST VPC
1 -
Stack
1 -
Stack overflow
2 -
StackOverflow Question
1 -
Stage failure
7 -
Stage Failures
1 -
Stages
1 -
Stages Bronze
1 -
Standard
20 -
Standard Cluster
2 -
Standard Deviation
2 -
Standard DS14 V2 Cluster
1 -
Standard DS4
1 -
Standard Error
1 -
Standard Functions
1 -
Standard Height
1 -
Standard NC12
1 -
Standard Pandas
1 -
Standard SKU
1 -
Standard Spark Implementation
1 -
Standard Users
1 -
Standard Workspace
3 -
Start
18 -
Start Time
1 -
Startup Failure
1 -
Startup Names
1 -
Startup Notebook
1 -
Startup Time
1 -
Stateful
1 -
Stateful Spark
1 -
Stateful Stream Processing
2 -
Static ip
1 -
Static Table
1 -
Statistical Analysis System
1 -
Statistical Function
1 -
Statistics
6 -
Status
2 -
Status Page
1 -
Steamboat Condos
1 -
Steamboat Ski Condos
1 -
Step Documentation
1 -
Step In
1 -
Stickers
1 -
Stop
1 -
Storage
12 -
Storage account
15 -
Storage Accounts
1 -
Storage API
1 -
Storage Container
4 -
Storage Container List
1 -
Storage Credential
1 -
Storage Error
1 -
Storage Level
1 -
Storage Mount
1 -
Storage Optimization
1 -
Storage Space
1 -
Store data
3 -
Store Error
1 -
Stored procedure
2 -
STPP
1 -
Strange Behavior
2 -
Strange Error
3 -
Strange Object
1 -
Stream
8 -
Stream Analytics
1 -
Stream Data
2 -
Stream Files
1 -
Stream Initializing
1 -
Stream Processing
13 -
Stream vs batch read
1 -
StreamCorruptedException Databricks
2 -
Streaminf Pipeline
1 -
Streaming
26 -
Streaming Checkpoint
1 -
Streaming Data
1 -
Streaming Listener
1 -
Streaming Pipelines
1 -
Streaming spark
4 -
Streaming Table
3 -
Streamlit Connectivity
1 -
Streamlit URL
1 -
Streams
4 -
Strict Performance Requirements
1 -
String
20 -
String Column
6 -
String Comparison
1 -
String Converstion
1 -
String Length
1 -
String Type
1 -
String Variable
1 -
Strongest Feeling
1 -
Struct
1 -
Structered Data
1 -
Structered Streamin
1 -
Structfield
3 -
Structtype
2 -
Structured streaming
29 -
Structured Streaming ForeachBatch
2 -
Structured Streaming Job
1 -
Stuck
4 -
Students
2 -
Studnet
1 -
Study Material
1 -
Study Problem
1 -
Style Interior
1 -
Submit
1 -
SUBNET FAILURE
1 -
SUBNET_EXHAUSTED_FAILURE
1 -
Subscription
2 -
Subscription Cancellation Issues
1 -
Substring
1 -
Success Message
1 -
Successful Status
1 -
Successfullly
1 -
Sudden Decrease
1 -
Suddenly
1 -
Suitable Driver Error
1 -
Sujata
1 -
Sumit22
1 -
Summarise Options
1 -
Summit22
28 -
Summit23
2 -
SummitTraining
2 -
Sunil
1 -
Superior Quality
1 -
Supply Chain
1 -
Support
13 -
Support Perspective
1 -
Support Request
1 -
Support Team
3 -
Support Ticket
1 -
Support Tickets
1 -
Surrogatekey
2 -
Survey Link
2 -
Surveys
2 -
Survminer Package
1 -
Suspened State
1 -
Suspicious Way
1 -
Syllabus Change
1 -
Synapse
6 -
Synapse Analytics
1 -
Synapse ML
1 -
Synapse sql dw connector
2 -
Synapse Table
1 -
Synapse Write
1 -
Sync
5 -
Synchronization
1 -
Synonym Functions
1 -
Syntax
4 -
Syntax Highlight Support
1 -
System
5 -
System ML
1 -
Systemd
1 -
Tab
2 -
Tab Button
1 -
Table
102 -
Table access control
9 -
Table Access Control Cluster
2 -
Table Access Controls
1 -
Table Access Logs
1 -
Table ACL
5 -
Table Changes
3 -
Table Content
1 -
Table Conversion
1 -
Table Creation
2 -
Table Data
2 -
Table Data Type
1 -
Table Definition
2 -
Table Deletion
1 -
Table Download
1 -
Table History
2 -
TABLE IF EXISTS
1 -
TABLE IF NOT EXISTS
1 -
Table import
2 -
Table Join
1 -
Table Merge Operation
2 -
Table Migration Advantages
1 -
Table Names
2 -
Table Naming
1 -
Table Optimize Error
1 -
Table Pipeline
12 -
Table Pipeline Load Error
1 -
Table Properties
2 -
Table Property
1 -
Table Records
3 -
Table schema
5 -
Table Schema Comment
1 -
Table Service Upgrade
1 -
Table Structure
1 -
Table Structure Design
1 -
TABLE Table
2 -
Table Vs View
1 -
Tableau
5 -
Tableau Hyper
1 -
Tableau server
1 -
Tables
27 -
Tables Batch
1 -
Tables Development
1 -
Tables Difference
2 -
Tables Directory
1 -
Tables Pipeline
1 -
Tables Source
1 -
Tabs Vs Spaces
1 -
Tabular Cube
1 -
Tabular Formats
1 -
Tabular model
1 -
TAC
1 -
Tag
1 -
Tags
3 -
Tagsinput
1 -
Target
11 -
Target Coverage
1 -
Target Date
1 -
Target DB
1 -
Target Schema
1 -
Target Table
4 -
Task
13 -
Task Attempt
1 -
Task Integration
1 -
Task Losses
1 -
Task Orchestration
5 -
Task Parameter Variables
1 -
Task Parameters
5 -
Task Pool
1 -
Task Running Long
2 -
Task Variables
2 -
TaskNotSerailizable Error
1 -
Tasks
11 -
Tasks Python
1 -
TaskValues
1 -
TBH
1 -
TBL
1 -
TBLPROPERTIES
1 -
TCO
1 -
Tcp
1 -
TDD
1 -
Team Appreciation
1 -
Team Community
1 -
Team Members
1 -
Team Want
1 -
Team's Databricks Notebooks
1 -
Tech & Wordpress Guest
1 -
Technical Pros
1 -
Technologies Inc
1 -
Telemetry
1 -
Temp File Deletion
1 -
Temp Table
3 -
Temp Views
1 -
Temporal Table
1 -
Temporary
2 -
Temporary File
2 -
Temporary Function
1 -
Temporary Problem
1 -
Temporary Table
1 -
Temporary View
3 -
Tempview
5 -
Tensor flow
1 -
Tensorboard Profile Board
1 -
Tensorboard Profiler
1 -
TensorFlow Models
2 -
Teradata
3 -
Terminated Reason
1 -
Terraform
17 -
Terraform Authentication
1 -
Terraform aws provisioning
2 -
Terraform Configuration
2 -
Terraform Databricks Documentation
1 -
Terraform Import
1 -
Terraform Plan
1 -
Test
12 -
Test Set
1 -
Testing
1 -
Testing Framework
1 -
Texas
1 -
Text
7 -
Text Data Source
1 -
Text Field
2 -
Text Function
1 -
Text Processing
1 -
Text Query Parameters
1 -
Text Widget
1 -
Textfile
1 -
Thank You
1 -
Third-Party Pharma Manufacturer
1 -
This
4 -
This Visualization Cannot Be Shown. Please Refresh The Visualization Or Update Its Configuration.
1 -
Thread
1 -
Thread Dump
1 -
Threading
1 -
Threadpool
1 -
Thrift
2 -
Ticker Number
1 -
Ticket Status
1 -
TID
23 -
TID 23832
1 -
TID 7
1 -
Tier
1 -
Tier Account
1 -
Tier Strategy
1 -
Time
24 -
Time Autoloader Runs
1 -
Time Parameter Returns
1 -
Time Parquets File
1 -
Time Run
1 -
Time Run Python Notebook
1 -
Time Series Analysis
1 -
Time Series Forecasts
1 -
Time Stamp Changes
1 -
Time travel
6 -
Time Travel Capability
1 -
TIME ZONE EST
1 -
TIME ZONE EST Function
1 -
Time--series
3 -
Time-out
1 -
Timeout
7 -
Timeout Error
1 -
Timeout Issue
1 -
TimeoutException
1 -
Timeseries
4 -
Timestamp
6 -
Timestamp Column
1 -
TIMESTAMP WITH TIMEZONE
1 -
TimestampFormat Issue
1 -
Timestamps
1 -
Timetravelling
1 -
Timezone
4 -
Timezone Understanding
1 -
Tips And Tricks
2 -
Title
1 -
Tkinter
1 -
Tmp
5 -
Tmp File Path
2 -
To
1 -
To_date
1 -
TOC
1 -
TODAY
3 -
Today's Date
1 -
TOEFL
1 -
Token
5 -
Token Access
1 -
Token Management
1 -
Token Management API
1 -
Tokens
3 -
Top Level
1 -
Topic
2 -
Total
1 -
Total Api
1 -
Total Size
1 -
Tour Asia Pacific
1 -
Tpc-ds
1 -
TPC_DS
1 -
Track Changes
1 -
Track Databricks
1 -
Tracking
1 -
Traffic Sources
1 -
Training
7 -
Training Notebook
1 -
Training Support
1 -
Trainings
2 -
Trainings In December
1 -
Transaction History
2 -
Transaction Log
4 -
Transaction Logs
1 -
Transactional Loading
1 -
Transfer Files
2 -
Transformation
5 -
Transformer
2 -
Transient Cluster
1 -
Transit Security
1 -
Translation Services
1 -
Transscript
1 -
Trasform SQL Cursor
1 -
Tree
1 -
Trial Account
1 -
Trial Databricks Account
1 -
Trigger
6 -
Trigger Intervals
1 -
Trigger notebooks
1 -
Trigger.AvailableNow
4 -
Tring
1 -
Trino Integration
1 -
Troubleshooting
4 -
Truncate
1 -
Truncating Results
1 -
Trustworthy Source
1 -
Trying
6 -
Trying to upload data in using create table with ui option into but showing internal server error
1 -
Tuning
3 -
Tuning Of Databricks Notebook
1 -
Turn On Notebook
1 -
Tutorial
2 -
Tutorial error
1 -
Txt
1 -
Txt File
2 -
Type
17 -
Type `import Pandas
1 -
Type Changes
1 -
TYPES OF TACTICAL GEAR
1 -
Typesafe Config File
1 -
Typescript Example
1 -
Typical Model
1 -
UAT
3 -
Ubuntu
5 -
Ubuntu Versions
1 -
UC
6 -
Udf
33 -
Udf in sparkr
2 -
UDFs Wrapping Modules
1 -
Ui
9 -
UI Bu
1 -
UI Issue
1 -
Unacceptable User Experience
1 -
Understanding Delta Lake
1 -
Undescriptive Error
1 -
UNDROP
1 -
Unexpected Behavior
1 -
Unexpected Behaviour
1 -
Unexpected Error
2 -
Unexpected Failure
2 -
Unexpected Keyword Argument
1 -
Unexpected Launch Failure
1 -
Unexpected Result
1 -
Unexpected Results
1 -
Unexpected Workspace Setup Dialog
1 -
Unicode
2 -
Unicode Field Separator
1 -
Union
3 -
Unionall
1 -
UnionAll Function
1 -
Unique Challenges
1 -
Unique Values
1 -
Unit Test
2 -
Unit testing
3 -
Unit Tests
4 -
United States
2 -
Unittest.main
1 -
Unity
2 -
Unity Catalog
56 -
Unity Catalog Delta Lake
1 -
Unity Catalog Object
1 -
Unity Catalog Quickstart
1 -
Unity Catalogue
2 -
Unity Catalouge
1 -
Unity Catlog
1 -
University Faculty Members
1 -
University Modules
2 -
University Students
1 -
Unix
1 -
Unknown Kernel
1 -
Unknown Token
1 -
Unknown WKB
1 -
Unmanaged Table
1 -
Unmanaged Tables
2 -
Unmatchable Quality
1 -
Unmount Issue
1 -
UNPIVOT
1 -
Unpivot PySpark DataFrame
1 -
Unsupported Azure Scheme
1 -
UNSUPPORTED CORRELATED SCALAR SUBQUERY
1 -
Unzip
2 -
Upcoming Days
1 -
Upcoming Sessions
1 -
Upcoming Updates
1 -
Update
10 -
Update Mode
1 -
Update Openapi Specs
1 -
Updates
3 -
Upgrade Azure Databricks
2 -
Upgrade-related
1 -
Upload
2 -
Upload CSV Files
1 -
Upload Files
1 -
Upload local files into dbfs
1 -
Uploading
1 -
Upper Bound
1 -
Upsert
6 -
Upsert Data
1 -
Upsert Mode
1 -
Uptime Workloads
1 -
Urgent Help
1 -
URI
7 -
Url
5 -
Usage
5 -
Usage Details
1 -
Usage Log
1 -
USAGE Privilege
1 -
Use
19 -
Use Case
6 -
Use cases
2 -
Use Dbutils
1 -
USE Hive
1 -
Use Microbatch Process
1 -
Use Parameter
1 -
Use Variables
1 -
Use Windows Machine
1 -
Usecase Development
1 -
Used Handbags
1 -
Used Laptop In Calicut
1 -
User
26 -
User and Group Administration
13 -
User Bases
1 -
User Code Compile Error
1 -
User Defined Function
1 -
User Folders
1 -
User Group
2 -
User Logs
1 -
User Notebook
1 -
User Security Configurations
1 -
Usercase Development
1 -
Usererror
1 -
UsermetadataAsOf Option
1 -
Users
11 -
Users Group
1 -
Users Permissions
1 -
USING CSV
1 -
USING PARQUET OPTIONS
1 -
UTC
10 -
Utf-16
1 -
UTF-16 Decoding
1 -
Utilization %
1 -
Uuid
2 -
UX
1 -
V2
1 -
V3 Vs. V2
1 -
VA
1 -
Vacumm
1 -
Vacuum
13 -
VACUUM Command
6 -
Vacuum Files
2 -
Vacuum Jobs
1 -
VACUUM Operation
2 -
Vacuum Operation Result
1 -
Val Spark
1 -
Value %
1 -
Value CustomerSchema
1 -
Value err
1 -
Value Labels
1 -
Value not found
1 -
Value }
1 -
Valueerro
1 -
Values
7 -
Variable
4 -
Variable Explorer
3 -
Variable Values
1 -
Variables
9 -
Variance Reduction
1 -
Various Features
1 -
VDP
1 -
VDS
1 -
Vectorized Pandas
1 -
Vectorized Pandas UDFs
1 -
Vectorized Reader
1 -
Vectorized Reading
1 -
Vendor
1 -
Verbose Audit Logs
1 -
Verification Databricks Community Edition
1 -
Version
12 -
Version Control Systems
1 -
Version Data
1 -
Version Information
1 -
Version Suporte
1 -
Versioncontrol
1 -
Vertical View
1 -
VERY SLOW
1 -
Vesrioning
1 -
Video
2 -
Video File Data
2 -
Video Lesson
1 -
View
19 -
View Name
1 -
View Query
1 -
Views
6 -
Vigor Now
1 -
Vim
1 -
Vinayak
1 -
VINN Automotive
1 -
Virtual
1 -
Virtual Environment
3 -
Virtual Instructor
2 -
Virtual Network Requirements InAzure
1 -
Visio
1 -
Visio Diagram
1 -
Visio Stencils
1 -
Visual Person
1 -
Visual Studio
2 -
Visual studio code
3 -
Visualisation Libraries
2 -
Visualisations Pane
1 -
Visualization
11 -
Visualization Tools
1 -
Visualizations
7 -
Visualizing Dataframe
1 -
Vm
2 -
VM Family
1 -
VM Size Limit
1 -
VM Types
1 -
VMs
2 -
Vnet
4 -
VNET CIDR
1 -
Vnet Injection
4 -
Vnet peering
2 -
Void Column
1 -
Volume ExecutionError
1 -
VOUCHER
11 -
Voucher Code
3 -
Vpc
13 -
VPD
1 -
Vpn
2 -
Vs code
4 -
VScode Extension
2 -
WAF
1 -
Waiting
1 -
War File
1 -
Wardrobe Space
1 -
Warehouse
3 -
Warehouse Configuration Tweaking
1 -
WARN NetworkClient
1 -
Wasbs
1 -
Watermark
2 -
WAVICLE
1 -
WBM
1 -
Web
3 -
Web App Azure Databricks
1 -
Web Application
2 -
Web Application Firewalls
1 -
Web Dashboards
1 -
Web Design Services
1 -
Web Form
1 -
Web Hosting
1 -
Web Pages
1 -
Web Portals
1 -
Web Terminal
3 -
Web Terminal Now
1 -
Web ui
3 -
Webaccesor Mail
1 -
Webhook
1 -
Webinar
5 -
Webinar Survey
1 -
Websocket
1 -
Week Number
1 -
Week Of Year
1 -
Week Year
1 -
Weekly Documentation Update
1 -
Weekly Release Notes
9 -
weeklyreleasenotesrecap
9 -
Weird Py4 Errors
1 -
Weird Thing
1 -
Welcome Emails
1 -
Wget
1 -
Whatsapp Group
1 -
Wheel
4 -
Wheel Method
1 -
Wheel Name
1 -
Wheel Package
1 -
Where
1 -
While
1 -
Whitcomb
1 -
White Page
1 -
Whitelist
1 -
Whl
1 -
Whl File
3 -
Wide Transformation
2 -
Widget
13 -
Widget Value
1 -
Widget Values
3 -
Widgets
18 -
Widgets Api
2 -
Wildcard Character
1 -
Window
2 -
Window Authentication
1 -
Window Function
2 -
Window functions
1 -
Windowing
1 -
Windows
5 -
Windows authentication
2 -
Windows Commands
1 -
Windows Function
1 -
Wit Databricks
1 -
With
2 -
Withcolumn
3 -
Withpassing Parameters
1 -
WKB Type
1 -
Wokspace Error Message
1 -
Women
1 -
Wood
1 -
Word2vec
1 -
Work Place
1 -
Worker
4 -
Worker Nodes
10 -
Worker Pool
1 -
Worker Type
3 -
Workers
2 -
Workflow
14 -
Workflow Cluster
3 -
Workflow Dbt Task
2 -
Workflow Execution
1 -
Workflow Integration Error
1 -
Workflow Issue
1 -
Workflow Job
2 -
Workflow Job Concurrency
1 -
Workflow Job Concurrency Limit
1 -
Workflow Job Limitations
1 -
Workflow Jobs
3 -
Workflow Scheduler
1 -
Workflow Tasks
2 -
Workflows
202 -
Worklaods
1 -
Workload
2 -
Works
4 -
Workspace
55 -
Workspace Access
1 -
Workspace Account Owner
1 -
Workspace api
1 -
Workspace Config
1 -
Workspace Delta Tables
1 -
Workspace Deployment
2 -
Workspace Directory
1 -
Workspace Environment
1 -
Workspace Files
3 -
Workspace Folder Hierarchy
1 -
Workspace Library
1 -
Workspace permission api for databricks
1 -
Workspace Settings
3 -
Workspace SKU
1 -
Workspace Spark
1 -
Workspace Storage States
1 -
Workspace Usage
1 -
Workspace User
1 -
Workspace's Url
1 -
Workspaceid
2 -
Workspaces Databricks Customer
1 -
World Databricks Community
1 -
Write
10 -
Write Table
1 -
Write.mode.append
1 -
WriteLines Errors
1 -
Writes
1 -
Writestream
2 -
Writing
4 -
Wrong Data Type Values
1 -
Wrong Data Types
1 -
Wrong Schedule Time
1 -
Wrote Bytes
1 -
WrtieStream
1 -
XComs Value
1 -
Xgboost
2 -
Xgboost4j
1 -
XLA Compilation
1 -
Xls File
1 -
Xlsx File
1 -
Xml
20 -
XML File
4 -
XML Files
3 -
XML Parser
1 -
Xml parsing
1 -
XMLA
1 -
Xss
1 -
Xyz
1 -
Yaml
1 -
Yarn
1 -
Year
2 -
Year Filter
1 -
Yellow Tripdata
1 -
Yield Keyword
1 -
Yolov5 Object Detection
1 -
YouTube
1 -
Z Ordering
1 -
Z-ordering
9 -
Zakaria
1 -
Zip
5 -
Zip file
2 -
Zookeeper
2 -
Zorder
7 -
ZORDER Option
1
- « Previous
- Next »
| User | Count |
|---|---|
| 1609 | |
| 751 | |
| 349 | |
| 285 | |
| 248 |