To create external tables we need to use the location keyword and use the link for the storage location, in reference to that does the user need to have permission for the storage location if not then will we use storage credentials to provide the ac...
Hi Nimai, That's partially right. You can grant permissions directly on the storage credential, but Databricks recommends that you reference it in an external location and grant permissions to that instead. An external location combines a storage cre...
I have a streaming notebook which fetches messages from confluent Kafka topic and loads them into adls. It is a streaming notebook with the trigger as continuous processing. Before loading the message (which is in Avro format), I'm flattening out the...
Best approach is to not to depend on Kafka’s commit mechanism! We can store processing result and message offset to external data store in the same database transaction. So, if the database transaction fails, both commit and processing will fail and ...
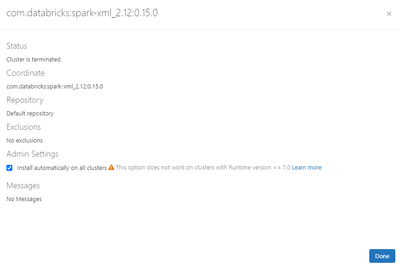
Even after maven library installation using the Auto installation.spark.read.option("rowTag", "tag").xml("dbfs:/mnt/dev/bronze/xml/fileName.xml")not working.
At present DLT does not support installing the maven library from the DLT pipeline. In the future this feature will come for sure so please wait for some time and keep checking data bricks runtime release docs https://docs.databricks.com/release-note...
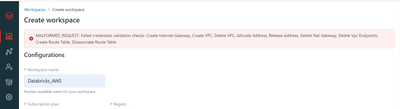
I am trying to configure databricks with AWS, I have configured the cloud resources as described in this https://docs.databricks.com/administration-guide/account-api/iam-role.html#language-Databricks%C2%A0VPC I have selected "Your VPC Default" as the...
@samruddhi ChitnisCan you please check the below troubleshooting guide : Credentials configuration error messages: Malformed request: Failed credential configuration validation checksThe list of permissions checks in the error message indicate the li...
Example:TABLE 1FIELD_TEXTI like salty food and Italian foodI have Italian foodbread, rice and beansmexican foodscoke, spritearray['italia', 'mex','coke']match TABLE1 X ARRAYResults:I like salty food and Italian foodI have Italian foodmexican foodsis ...
a bit old, but I just faced the same issue, specifying a custom EncryptionMaterialsProvider (as described in the previous post) did the trick for me but I did had to also specify my kms endpoint, just because my region:"fs.s3.cse.kms.endpoint" -> "km...
I am trying to pass parameter from SSRS to User Defined Function in Databricks which in turn will return table that will be shown as output in report.I tried below calling function from SSRS, but it looks like parameter value is not passed. I have di...
Hi I am trying to use the SQL Merge statement on databricksMERGE INTO targetUSING sourceON source.key = target.keyWHEN MATCHED UPDATE SET *WHEN NOT MATCHED INSERT *WHEN NOT MATCHED BY SOURCE DELETEThis is failing with the error [PARSE_SYNTAX_ERROR...
I was missing the THEN before UPDATE, INSERT and DELETE. This keyword is missing from the documentation on Databricks https://learn.microsoft.com/en-us/azure/databricks/delta/mergeIt now works. Thanks
Even after specifying SSL options, unable to connect to MySQL. What could have gone wrong? Could anyone experience similar issues? df_target_master = spark.read.format("jdbc")\.option("driver", "com.mysql.jdbc.Driver")\.option("url", host_url)\.optio...
Hey,Here the solution: The correct option for ssl is "useSSL" and not just "ssl".This code below could works:df_target_master = spark.read.format("jdbc")\.option("driver", "com.mysql.jdbc.Driver")\.option("url", host_url)\.option("dbtable", supply_ma...
I am running steps mentioned in https://github.com/databrickslabs/splunk-integration/blob/master/notebooks/source/push_to_splunk.pyWhen I am running spark.catalog.listDatabases()getting error py4j.security.Py4JSecurityException: Method public java.l...
Hi @Purnima Bhatia , I faced a similar error for a different command when I was using a wrong type of cluster access mode. You can try to create a different cluster with different access mode and check. I might be wrong but try and check this.
Do we see any risk of saving a Number field as String? Will we use any functionality/feature if we save as String ? Will it have any impact on performance ?
Hi @Manju Chugani. Yes. In Short, it is not really recommended to save the columns as string if all the values are expected to be numbers.Here are some of them Storage Space: Storing numbers as strings can take up more storage space than storing the...
I am posting this on behalf of my customer. They are currently working on the deployment & config of their workspace on AWS via Terraform.Is it possible to set some configs in the Admin/workspace settings via TF? According to the Terraform module, it...
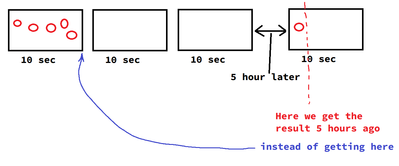
The problem is very simple, when you use TUMBLING window with append mode, then the window is closed only when the next message arrives (+watermark logic). In the current implementation, if you stop incoming streaming data, the last window will NEVER...
No, the problem remains the same. The meaning doesn't change because you increased the timeout a little bit. As the window did not close, and does not close until a new message arrives
Hi!I am training a Random Forest (pyspark.ml.classification.RandomForestClassifier) on Databricks with 1,000,000 training examples and 25 features. I employ a cluster with one driver (16 GB Memory, 4 Cores), 2-6 workers (32-96 GB Memory, 8-24 Cores),...
Hi @John B Hope everything is going great.Just wanted to check in if you were able to resolve your issue. If yes, would you be happy to mark an answer as best so that other members can find the solution more quickly? If not, please tell us so we can...
pandas 2.0.0 was released on 4.3.2023 and was pushed to my cluster on the same day. The day after I tried using training_set.load_df().toPandas() and it failed. Reverting to pandas 1.5.3. fixed the problem.
Hi @Al IDI Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answers your q...