Hi @Aly Ayman Hope everything is going great.Just wanted to check in if you were able to resolve your issue. If yes, would you be happy to mark an answer as best so that other members can find the solution more quickly? If not, please tell us so we ...
I cannot access the course anymore, it's shows it's under maintenance. For how long this will be? Is there any way to access it's videos for the Data Engineer Associate part?
Hi @Juan Manuel Moviglia Hope everything is going great.Just wanted to check in if you were able to resolve your issue. If yes, would you be happy to mark an answer as best so that other members can find the solution more quickly? If not, please tel...
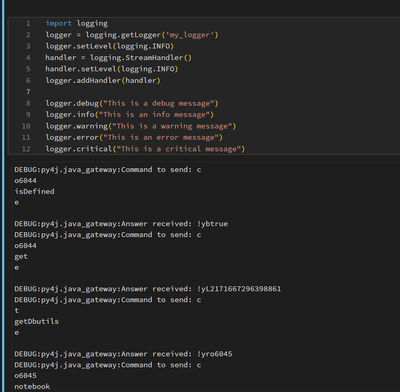
I have a repo that have python files that use the built in logging module. Additionally in some of the notebooks of the repo I want to use logging.debug()/logging.info() instead of print statements everywhere. However when I use the root logger or cr...
Hi @Yusuf Khan Hope everything is going great.Just wanted to check in if you were able to resolve your issue. If yes, would you be happy to mark an answer as best so that other members can find the solution more quickly? If not, please tell us so we...
I am using a threadpool executor and running notebooks in parallel. However, these parallel notebooks are not using executors at all and all the load is going towards the driver node resulting in running out of memory for the driver node and eventual...
Hi @uzair mustafa Thank you for your question! To assist you better, please take a moment to review the answer and let me know if it best fits your needs.Please help us select the best solution by clicking on "Select As Best" if it does.Your feedbac...
Using ODBC or JDBC to read from a table fails when I attempt to use an ORDER BY clause. In one sample case, I have a fairly small table (just 1946 rows).select *
from some_table
order by some_fieldResult:java.lang.IllegalArgumentException: requiremen...
Hi @petter@hightouch.com Petter Thank you for your question! To assist you better, please take a moment to review the answer and let me know if it best fits your needs.Please help us select the best solution by clicking on "Select As Best" if it doe...
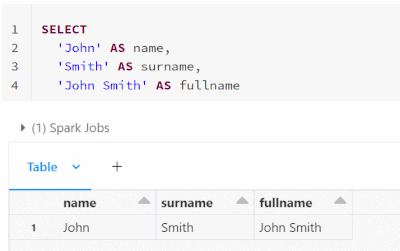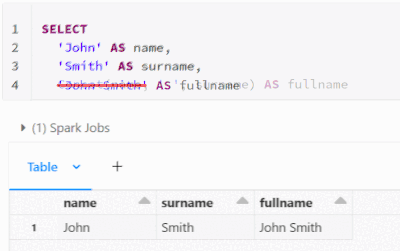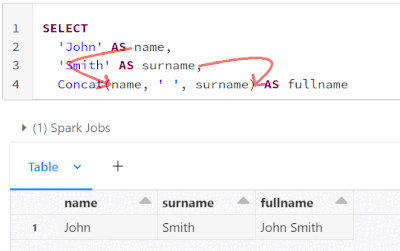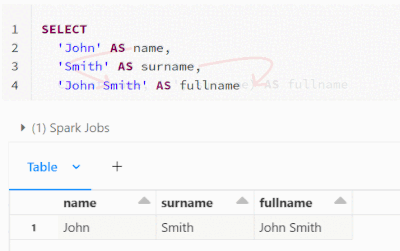
Starting from #databricks runtime 12.2 LTS, implicit lateral column aliasing is now supported. This feature enables you to reuse an expression defined earlier in the same SELECT list, thus avoiding repetition of the same calculation.For instance, in ...
Hi! I have a problem with user memory on driver (I have almost several mb of storage memory, 0 Execution memory and more than 7GB of JVM Memory on Heap in use). How it can be? I don't have any broadcast variables, joins or aggregations. All the pipe...
Hi @Yuliya Valava Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Than...
Hi @Youssef Mrini Thank you for your question! To assist you better, please take a moment to review the answer and let me know if it best fits your needs.Please help us select the best solution by clicking on "Select As Best" if it does.Your feedbac...
I am trying to migrate Databricks SQL Dashboards and Queries from one workspace to another.Recently Databricks allows storing SQL objects in Workspace folders (https://docs.databricks.com/sql/user/workspace-browser/), but archiving the folder into db...
I have created a job in Databricks Workflow that runs a notebook and have given manage run permissions to users. If any user trigger the job, I expect the job to show their username in Run As Option as it was triggered by them and they have Manage Ru...
Hi @Vigneshraja Palaniraj Rus as is a private preview feature. Please complete this sign up form which will be reviewed by PM and you'll receive the confirmation once it's enabled.
"Hey everyone, it seems like there's some confusion about enhanced autoscaling in Databricks lately. If you're feeling lost or unsure about how it works, don't worry - you're not"Enhanced autoscaling is a feature in Databricks that enables dynamic sc...
Hello everyone, I am trying to setup Databricks CLI by referring to the Databricks CLI documentation. When I setup using the Personal Access Token, it works fine and I am able to access the workspace and fetch the results from the same workspace in D...
Hi @Juned Mala Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Thanks!
Hi All, I need to install a spark-xml package from a notebook cell (hoping it will work on a DLT cluster). Maven Package: com.databricks:spark-xml_2.12:0.16.0Can anyone help me with the command to install from the notebook cell? Fairly new to all thi...
Hi @Jason Johnson I'm sorry you could not find a solution to your problem in the answers provided.Our community strives to provide helpful and accurate information, but sometimes an immediate solution may only be available for some issues.I suggest ...
Databricks Community version - Unable to clone a public git repository, as the 'Repository' tab that should appear below 'Workspace' tab on the portal does not appear and I am not aware of any alternate method. I have referred to some documents on th...
Hi @Jay Kumar Thank you for your question! To assist you better, please take a moment to review the answer and let me know if it best fits your needs.Please help us select the best solution by clicking on "Select As Best" if it does.Your feedback wi...