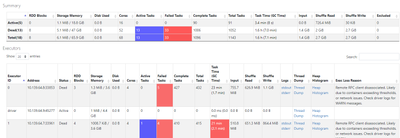
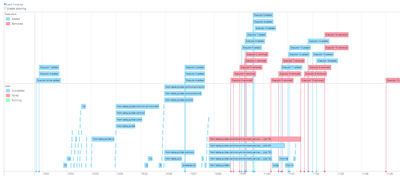
We observe the following behavior when we keep adding new runs to an experiment:- In the beginning, the runs are still displayed correctly in the UI.- After a certain number of total runs, the following bug occurs in the UI: - In the UI, there are ...
Hi @Timo Burmeister Apologies for the delay! I went through the video, does it happen all the time? I see after sorting it with different filter the list appears.
00007160: 2023-01-30T14:22:06 [TARGET_LOAD ]E: Failed (retcode -1) to execute statement: 'COPY INTO `e2underwriting_dbo`.`product` FROM(SELECT cast(_c0 as INT) as `ProductID`, _c1 as `ShortName`, cast(_c2 as INT) as `Status`, cast(_c3 as TIMESTA...
You can ensure there is always an active run of your Databricks job with the new continuous trigger type. https://docs.databricks.com/workflows/jobs/jobs.html#continuous-jobs
Current Cluster Config:Standard_DS3_v2 (14GB, 4 Cores) 2-6 workersStandard_DS3_v2 (14GB, 4Cores) for driverRuntime: 10.4x-scala2.12We want to overwrite a temporary delta table with new records. The records will be load by another delta table and tran...
Hi,thank you for your help!We tested the configuration settings and it runs without any errors.Could you give us some more information, where we can find some documentation about such settings. We searched hours to fix our problem. So we contacted th...
Hello to everyone!I am trying to read delta table as a streaming source using spark. But my microbatches are disbalanced - one very small and the other are very huge. How I can limit this? I used different configurations with maxBytesPerTrigger and m...
Hi @Yuliya Valava, If you are setting the maxBytesPerTrigger and maxFilesPerTrigger options when reading a Delta table as a stream, but the batch size is not changing, there could be a few reasons for this:The input data rate is not exceeding the li...
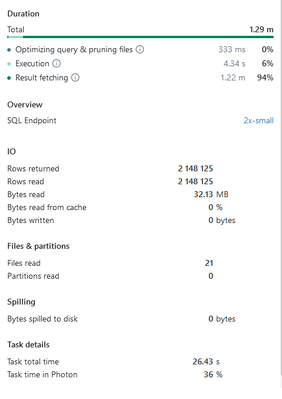
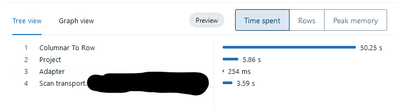
I tried to benchmark the Powerbi Databricks connector vs the powerbi Delta Lake reader on a dataset of 2.15million rows. I found that the delta lake reader used 20 seconds, while importing through the SQL compute endpoint took ~75 seconds. When I loo...
Guys, is there any way to switch off CloudFetch and fall back to ArrowResultSet by default irrespective of size? using the latest version of Spark Simba ODBC driver?
Benefit: This will help simplify the where clauses of the consumers of the tables? Just query on the main date field if I need all the data for a day. Not an extra day field we had to make.
Hi @Ryan Hager , Just a friendly follow-up. Do you still need help, or @Hubert Dudek (Customer) 's response help you to find the solution? Please let us know.
Is it possible to attach a notebook to cluster and run it via the REST API?The closest approach I have found is to run a notebook, export the results (HTML!) and import it into the workspace again, but this does not allow us to retain the original ex...
Hi @Akihiko Nagata , have you checked the jobs API? You can run a job on the existing cluster that can use the notebook of concern. I believe this is the only way.https://docs.databricks.com/dev-tools/api/latest/jobs.html#operation/JobsRunsSubmit
Hi Team, Can you please suggest to me how to implement the late arriving dimension or early arriving fact with examples or any sample script for reference? I have to implement the same using pyspark.Thanks.
Hi @Hare Krishnan Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Than...
Passed the Fundamentals of the Databricks Lakehouse Platform Accreditation, but no badge recieved. Tried "https://v2.accounts.accredible.com/retrieve-credentials?" showing no badge.
Hi @Ranjeet Ahlawat ,Congratulations on the certification. For any certification you take in the databricks you will be receiving the certificate and the badge in 24-48 hours and sometimes in lesser time as well. All the best for your future certifi...
I cannot log in to my Databricks community account. I have already tried to receive support and no real support has been given. I attempt to reset my password, the link gets sent, but once I enter the new password it gets stuck permanently loading. I...
Hi @Ahmet Korkmaz Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Than...
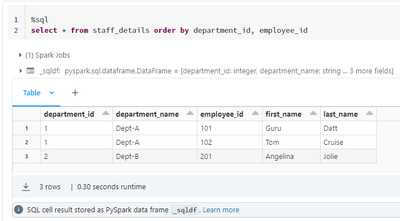
Let's say I have a delta table in Azure databricks that stores the staff details (denormalized). I wanted to export the data in the JSON format and save it as a single file on a storage location. I need help with the databricks sql query to group/co...
After using spark.read.format("snowflake").options(**options).option("dbtable", "table_name").load() to read a table from Snowflake, when I then change the table from Snowflake and read it again, it gives me the first version of the table. I have wor...
Yes, that would work. However, it is a longish Snowflake query producing a number of tables that are all called by the Databricks notebook, so it requires quite a few changes. I'll use this alternative if I automate the process. However, I think this...
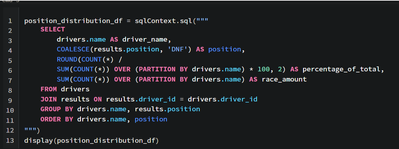
Previously we were able to see SQL queries inside spark.sql() like this:But now it just looks like a plain string: I know it's not a big issue, but it's still annoying to have to code in SQL while having it all be blue, it makes debugging more cumber...
Hi @Emilio Garza,Just a friendly follow-up. Did any of the responses help you to resolve your question? if it did, please mark it as best. Otherwise, please let us know if you still need help.