- 911 Views
- 2 replies
- 1 kudos
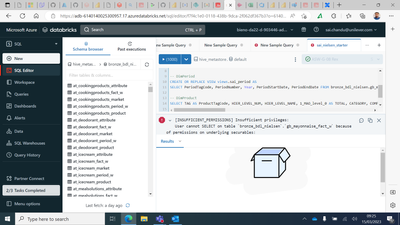
I would like to get rid of the error
the SPN we use for the mount points has access to the dataset in question, but for some reason I get this errorPlease find the attached screenshot for the error details.
- 911 Views
- 2 replies
- 1 kudos
Latest Reply
- 1 kudos
Hi @sai chandu palkapati Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from y...
- 1 kudos