I have a large stream of data read from Confluent Kafka, 500+ millions of row. When I initialize the stream I cannot control the batch sizes that are read.I've tried setting options on the readstream - maxBytesPerTrigger, maxOffsetsPerTrigger, fetc...
Hi @Adam Rink Just checking for further info on your question. How are you deducing that the batch sizes are more than what you are providing as maxOffsetsPerTrigger ?
I have a databricks job running in azure databricks. A similar job is also running in databricks gcp. I would like to compare the cost. If I assign a custom tag to the job cluster running in azure databricks, I can see the cost incurred by that job i...
Probably not feasible, but is there a way to update (via STORED PROCEDURE, FUNCTION or SQL query) the information schema of all external tables within Databricks. Last updated that I can see was when I converted the tables to Unity. From my understa...
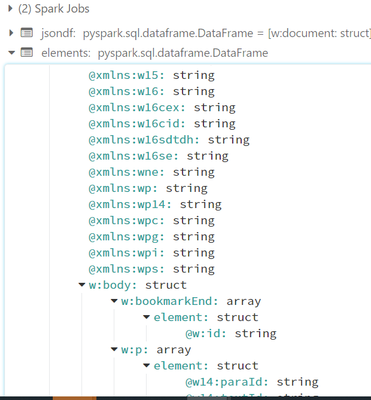
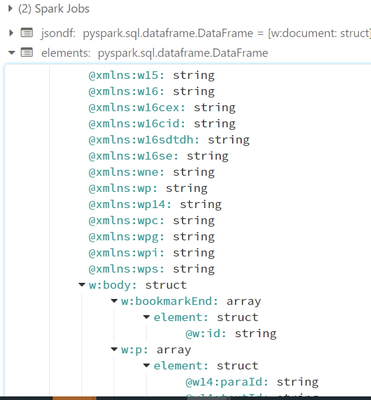
File.json from the below code contains huge JSON data with each key containing namespace prefix(This JSON file converted from the XML file).I could able to retrieve if JSON does not contain namespaces but what could be the approach to retrieve record...
I'm following a class "DE 3.1 - Databases and Tables on Databricks", but it is not possible create databases due to "AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: MetaException(message:Got exception: org.apache.hadoop.fs.Unsupp...
I have been reading this article https://www.databricks.com/session_na20/native-support-of-prometheus-monitoring-in-apache-spark-3-0 and it has been mentioned that we can get the spark streaming metrics like input rows, processing rate and batch dura...
do you help me with the next error?MessageCluster terminated. Reason: Azure Vm Extension FailureHelpInstance bootstrap failed.Failure message: Cloud Provider Failure. Azure VM Extension stuck on transitioning state. Please try again later.VM extensio...
I would need some suggestion from DataBricks Folks. As per documentation in Schema Evaluation for Drop and Rename Data is overwritten. Does it means we loose data (because I read data is not deleted but kind of staged). Is it possible to query old da...
Overwritte option will overwritte your data. If you want to change column name then you can first alter the delta table as per your need then you can append new data as well. So both problems you can resolve
Last night the cluster was working properly, but this morning the cluster was terminated automatically and cannot be restarted. Got an error message under sparkUI: Could not find data to load UI for driver 5526297689623955253 in cluster 1125-062259-i...
The old version of the notebook had this feature, where you could Ctrl+click on different positions in a notebook cell to bring the cursor there, and type to update the code in both the positions like in JupyterLab. The newer version is awesome but s...
I have uploaded a csv file which have well formatted data and I was trying to use display(questions) where questions=spark.read.option("header","true").csv("/FileStore/tables/Questions.csv")This is throwing an error as follows:SparkException: Job abo...
Hi,I have a Databricks instance and I mounted the Azure Storage Account. When I run the following command, the output is ExecutionError: An error occurred while calling o1168.ls.: shaded.databricks.org.apache.hadoop.fs.azure.AzureException: java.util...
Hi thereI have used my company email to register an account for databricks learning .databricks.com a while back.Now what I need to do is create an account with partner-academy.databricks.com using my company email too.However when I register at part...
Hi @Muthukrishnan Balasubramanian I got the same issue a while back what worked for me is registering using personal account on partner academy then later I changed my email to my work email. Not sure if it's the best way to sort the issue.
I have installed the library via PyPI on the cluster. When we import the package on notebook, getting the following errorimport librosaOSError: cannot load library 'libsndfile.so': libsndfile.so: cannot open shared object file: No such file or direct...
Thank you werners. Just figured that out and had an init script to sort out the issue. Below steps helped me to solve the issue.dbutils.fs.mkdirs("dbfs:/cluster-init/scripts/")dbutils.fs.put("/cluster-init/scripts/libsndfile-install.sh","""#!/bin/bas...