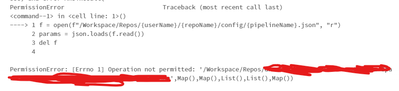
I had a working DLT pipeline that failed in the morning because it cannot read files from the Workspace or Repo directory. It is throwing an Operation not permitted error.Even when I am listing directories, it is throwing the same error (although it ...
currently I have some prblem about my DataBricks workspace when an user was deleted and it cause some issue:Applications or scripts that use the tokens generated by the user will no longer be able to access the Databricks APIJobs owned by the user wi...
I access databricks feature store outside databricks with databricks-connect on my IDE pycharm.The problem is just outside Databricks, not with a notebook inside Databricks.I use FeatureLookup mecanism to pull data from Feature store tables in my cus...
Also, Please refer to the below KB for additional resolution - https://learn.microsoft.com/en-us/azure/databricks/kb/dev-tools/dbconnect-protoserializer-stackoverflow
Consider a table that gets partitioned on a date field. But, I'm filtering a column that is not partitioned. Now, with this filter condition whether all the files are parsed to attain the required result set, or does any data skipping happens?
Hello. We would like to understand how many parquet files are created per data table. To be more specific, we refer to the current snapshot of the table. For example, we noticed that while we performed initial inserts to a table, one parquet file was...
I have a notebook (nb1) that calls another one (nb2) via the %run command. This returns some visualizations that I want to add to a dashboard of the caller notebook (nb1-db). When I select the visualization drop down, then select Add to dashboard, th...
Hi @Nicholas Couture, We haven’t heard from you since the last response from @Debayan Mukherjee , and I was checking back to see if you have a resolution yet. If you have any solution, please share it with the community as it can be helpful to othe...
Hi, We are currently using a Azure AAD Token inorder to authenticate with Databricks instead of generating Personal Access Tokens from Databricks. We have a multi-tenant architecture and so we are using Azure container instances to run multiple trans...
Hi @Dharit Sura , We haven’t heard from you since the last response from @Debayan Mukherjee , and I was checking back to see if you have a resolution yet. If you have any solution, please share it with the community as it can be helpful to others....
Hello,
Please suggest how can we implement Referential Integrity (Primary Key / Foreign Key Constraint) - between different tables defined on Azure Databricks Database.
Basically the syntax to add Primary and Foreign Key constraint in the table defi...
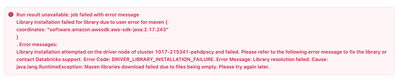
I have like 5 maven libraries, and with all of them, I have the same issue with Job or Notebooks. How much do I have to wait? is there another solution? Thank you very much!
Hi,there is no option to take VMs from a Pool for a new workflow (Azure Cloud)?default schema for a new cluster:{
"num_workers": 0,
"spark_version": "10.4.x-scala2.12",
"spark_conf": {
"spark.master": "local[*, 4]",
"spark...
Hi,
I tried following the Delta Live Tables quickstart (https://docs.databricks.com/data-engineering/delta-live-tables/delta-live-tables-quickstart.html), but I don't see the Pipelines tab under the Jobs page in my workspace.
The same guide mentions...
Hi, you need a Premium workspace for the Pipelines tab to show up. This is what I see on my workspace with Standard Pricing Tier selected: And this is what what I see on my workspace with the Premium Pricing Tier:
Hi Team for secure connection we created secured cluster withNPIP(https://learn.microsoft.com/en-us/azure/databricks/security/secure-cluster-connectivity) WORKSPACE hosted in a private VNET.We had a hub vnet with private endpoint for key vault ,We pe...
Hi @somanath Sankaran , We haven’t heard from you since the last response from @Hubert Dudek, and I was checking back to see if you have a resolution yet. If you have any solution, please share it with the community as it can be helpful to others....
Hi All,i am getting the below error when i am ingesting the data from source file , source file is also attached , i have tried in both Community edition and Azure databricks as well getting the same error , can any one suggest me the solution ? # ...
Hi @Rakesh Reddy Gopidi , We haven’t heard from you since the last response from me, and I was checking back to see if you have a resolution yet. If you have any solution, please share it with the community as it can be helpful to others. Otherwise...