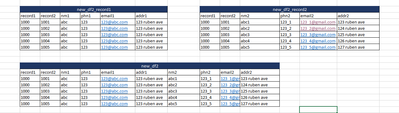
My two dataframes look like new_df2_record1 and new_df2_record2 and the expected output dataframe I want is like new_df2:
The code I have tried is the following:
If I print the top 5 rows of new_df2, it gives the output as expected but I cannot pri...
I am using the sample code which is available in getting start tutorial. And it is simple read the json file and move in another table. But it is throwing error related to EventHubsSourceProvider
Is there any way to overwrite a partition in delta table without specifying each and every partition in replace where. For non dated partitions, this is really a mess with delta tables.Most of my DE teams don't want to adopt delta because of these gl...
Hello all, I'm using the older 6.4 runtime and noticed that a query return no result whereas the same query on 10.4 provided the expected result. This is bad, because I got no error, simply no result at all.Is there is some spark settings on the clus...
Hi @Alessio Palma, We haven’t heard from you on the last response from me, and I was checking back to see if you have a resolution yet. If you have any solution, please do share that same with the community as it can be helpful to others. Otherwise...
I am using DBR version 10.1. I want to use Synapse ML package. I am able to install and import it by following instructions on the link: https://github.com/microsoft/SynapseML. However when I try to run the code it gives me the error shown in the att...
Hello @Vikram Mahawal Clusters need to be in the running state to install/uninstall the libraries. Could you please start the cluster and try installing it.If you are still stuck, please file a support case with us, so we can take a look.Thanks
Hi, I have Databricks installation in Azure. I want to run a job that connects to HBase in a separate HDinsight cluster.What I tried:Created a peering between base cluster and Databricks vNets.I can ping IPs of Hbase zookeeper nodes but I cannot acce...
I have a delta table with 20 M rows, Ther table is being updated dozens of times per day. The merge into is used, and the merge works fine for 1 year. But recently I begin notice some of data is deleted from merge into without delete specified. Mer...
I can't reproduce the issue anymore. for now, I am going to limit the number of merge into commands as intermediate data transformation does not need versioning history. I am going to try to use combined views for each step, and do a one-time merge i...
Py4JJavaError: An error occurred while calling o236.sql. : org.apache.spark.SparkException: Job aborted. at org.apache.spark.sql.execution.datasources.FileFormatWriter$.write(FileFormatWriter.scala:201) at org.apache.spark.sql.execution.datasources.I...
could you please increase the below config (at the cluster level) to a higher value or set it to zero spark.databricks.queryWatchdog.maxQueryTasks 0The spark config while it alleviates the issue.
Is there a way to prevent the _success and _committed files in my output. It's a tedious task to navigate to all the partitions and delete the files.
Note : Final output is stored in Azure ADLS
Please find the below steps to remove _SUCCESS, _committed and _started files.spark.conf.set("spark.databricks.io.directoryCommit.createSuccessFile","false") to remove success file.run vacuum command multiple times until _committed and _started files...
I have a notebook that runs many notebooks in order, along the lines of:```%pythonnotebook_list = ['Notebook1', 'Notebook2'] for notebook in notebook_list: print(f"Now on Notebook: {notebook}") try: dbutils.notebook.run(f'{notebook}', 3600) e...
I found the problem. Even if a notebook creates and specifies a widget fully, the notebook run process, e.g, dbutils.notebook.run('notebook') will not know how to use it. If I replace my widget with a non-widget provided value, the process works fine...
In Apache Spark prior to 2.1, once a SQL query was run, there was no way to re-run it; all history was lost. Spark SQL introduced the "replay" functionality in Spark 2.1.0, enabling users to re-run any query they have already run. You can run a query...
Problem Statement : When running Delta Live tables ,it is giving the error.Error Message : Could not initialize class org.rocksdb.Optionsorg.apache.spark.sql.streaming.StreamingQueryException: Query cpicpg_us_tgt_amz_bronze [id = a42eec82-0ee8-41b4-9...
Hi Team ,Thanks for your response, I faced this issue while executing the Delta Live tables / pipeline.Initially i choose product edition as Core and attached 4 notebooks to the pipeline and each notebook have Bronze and silver tables creation. duri...
Hi all, If we have multiple tasks under the job, How to invoke a specific task under a job.Do we have any API to invoke Job and its specific tasks instead of Job.Use case: When we receive multiple messages from the event hub, each underlying task in ...
Thanks for your response, My question is ,if we have multiple tasks in a job ,How can we invoke specific task, I can see API to invoke the job but not a particular task in it. Kindly find attachment for your reference.
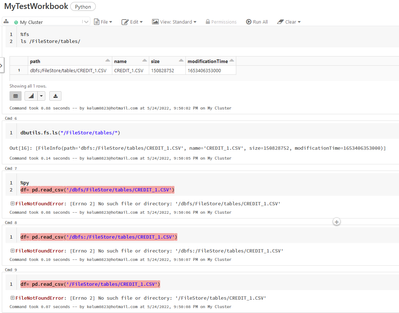
I'm trying to read a CSV file saved in data using pandas read_csv function. But it gives No such file error.%fs
ls /FileStore/tables/
df= pd.read_csv('/dbfs/FileStore/tables/CREDIT_1.CSV')
df= pd.read_csv('/dbfs:/FileStore/tables/CREDIT_1.CSV')...