When running automl on its UI, it classifies a feature "local_convenience_store" as both a numeric and categorical column. This affects the result as for numeric columns a scaler is used while in a categorical column it is one hot encoded. For contex...
@hr then :The approach taken by AutoML to classify features as numeric or categorical depends on the specific AutoML framework or library being used, as different implementations may use different methods or heuristics to make this determination.In ...
While inserting into target table i am getting an error '"not enough data columns;target has 3 but the inserted data has 2" but it's the identity column which is the 8th column ".insert into table A(col 1,col 2,col3)select col2,col3from table Bjoin t...
Hi @sky blue Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Thanks!
Hi Team,Just wondering, how can I add a column to an existing table.I'd tried the below script but giving me an error:ParseException: [PARSE_SYNTAX_ERROR] Syntax error at or near '<'(line 1, pos 121)ALTER TABLE table_clone ADD COLUMNS col_name1 STRUC...
@Gil Gonong :In Databricks, you can add a column to an existing table using the ALTER TABLE statement in SQL. Here is an example:ALTER TABLE table_clone ADD COLUMN col_name1 STRUCT<
type: STRING,
values: ARRAY<STRING>
>Note that you need to ...
I have json files falling in our blob with two fields, 1. offset(integer), 2. value(base64).This value column is json with unicode. so they sent it as base64. Challenge is this json is very large with 100+ fields. so we cannot define the schema. We c...
Hi @MerelyPerfect Per Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you....
let's say there is a database db in which 700 tables are there, and we need to find all the tables name in which column "project_id" is present.just an example for ubderstanding the questions.
Is it possible to use a calculated column (as like in the delta table using generatedAlwaysAs) definition while writing the data frame as a delta file like df.write.format("delta").Any options are there with the dataframe.write method to achieve this...
Hi @Thushar R ,This option is not a part of Dataframe write API as GeneratedAlwaysAs feature is only applicable to Delta format and df.write is a common API to handle writes for all formats. If you to achieve this programmatically, you can still use...
I have a table with a timestamp column (t) and a list of columns for which I would like to compute the difference over time (v), by some key(k): v_diff(t) = v(t)-v(t-1) for each k independently.Normally I would write:lag_window = Window.partitionBy(C...
I created a simple definition of delta live table smth like:CREATE OR REFRESH STREAMING LIVE TABLE customers_silverAS SELECT * FROM STREAM(LIVE.customers_bronze)But I am getting an error when running a pipeline:com.databricks.sql.transaction.tahoe.De...
You might need to execute the following on your tables to avoid this error message ALTER TABLE <table_name> SET TBLPROPERTIES ( 'delta.minReaderVersion' = '2', 'delta.minWriterVersion' = '5', 'delta.columnMapping.mode' = 'name' )Docs https...
hi , I want date for runtime from ADF as @utcnow() -- base paramater of notebook activity in ADF and take the data in ADB using widgets as runtime_date, further i want that column to be added in my table X with the populated value from the widget.Eve...
I found an issue:For a table with an identity column defined.when the table column is renamed using this method, the identity definition will be removed. That means using an identity column in a table requires extra attention to check whether the ide...
try to avoid reload table, I found we can upgrade table version, and use rename column commandALTER TABLE test_id2 SET TBLPROPERTIES ( 'delta.columnMapping.mode' = 'name', 'delta.minReaderVersion' = '2', 'delta.minWriterVersion' = '6')ALTER TABLE ...
I have created a database called retail and inside database a table is there called sales_order. I want to create an identity column in the sales_order table, but while creating it I am getting an error.
After accumulating many updates to a delta table,like,keyExample bigint GENERATED ALWAYS AS IDENTITY (START WITH 1 INCREMENT BY 1),my identity column values are in the hundreds of millions. Is there any way that I can reset this value through vacuumi...
Hey there @Andrew Fogarty Does @Werner Stinckens's response answer your question? If yes, would you be happy to mark it as best so that other members can find the solution more quickly? Else please let us know if you need more help. Thanks!
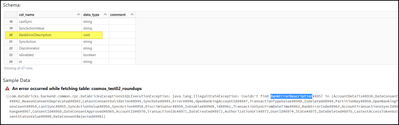
Hi everyone, I have connected to Cosmos using this tutorial https://github.com/Azure/azure-sdk-for-java/tree/main/sdk/cosmos/azure-cosmos-spark_3_2-12/Samples/DatabricksLiveContainerMigrationAfter creating a table using a simple SQL command:CREATE TA...
Hey there @Joel iemma Hope all is well! Just wanted to check in if you would be happy to mark an answer as best for us, please? It would be really helpful for the other members too.Cheers!
Thanks i modified my code as per your suggestion and it worked perfectly Thanks again for all your inputsdflist= spark.createDataFrame(list(a.columns), "string").toDF("Name")dfg=dflist.filter(col('name').isin('ref_date')).count()if dfg==1 : a = a.wi...