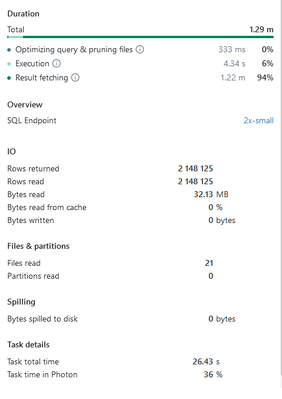
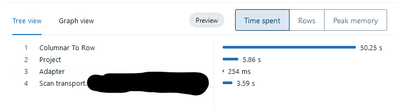
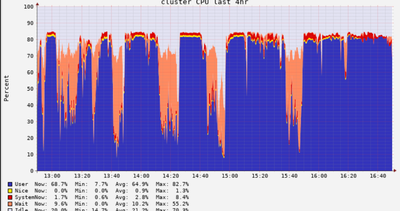
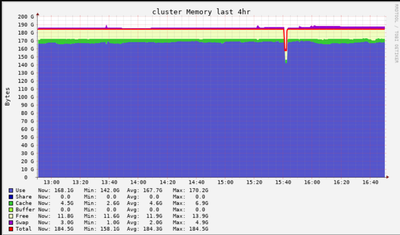
I tried to benchmark the Powerbi Databricks connector vs the powerbi Delta Lake reader on a dataset of 2.15million rows. I found that the delta lake reader used 20 seconds, while importing through the SQL compute endpoint took ~75 seconds. When I loo...
Guys, is there any way to switch off CloudFetch and fall back to ArrowResultSet by default irrespective of size? using the latest version of Spark Simba ODBC driver?
Maybe I'm completely wrong, but from my understanding delta lake only calculates a table at certain points, for instance when you display your data. Before that point, operations are only written to the log file and are not executed (meaning no chang...
Hi @Lukas Goldschmied Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you....
To connect Delta Lake with Microsoft Excel, you can use the Microsoft Power Query for Excel add-in. Power Query is a data connection tool that allows you to connect to various data sources, including Delta Lake. Here's how to do it:Install the Micros...
Our vendor is looking to use Microsoft API Manager to retrieve data from a variety of sources. Is it possible to extract records from the delta lake by using an API?What I've tried:I reviewed the available databricks API's it looks like most of them ...
Another possibility for this potentially is to stand up a cluster and have a notebook running flask to create an API interface. I'm still looking into options, but it seems like there should be a baked in solution besides the JDBC connector. I'm not ...
I have lot of tables with 80% of columns being filled with nulls. I understand SQL sever provides a way to handle these kind of data during the data definition of the tables (with Sparse keyword). Do datalake provide similar kind of thing?
datalake itself not, but the file format you use to store data does.f.e. parquet uses column compression, so sparse data will compress pretty good.csv on the other hand: total disaster
In my findings I have found a lot of delta tables in the lake house to be sparse so just wondering what space data lake takes to store null data and also any suggestions to handle sparse data tables in lake house would be appreciated.I also want to o...
Hi @Akash Ragothu, We haven’t heard from you since the last response from @Ajay Pandey, and I was checking back to see if his suggestions helped you.Or else, If you have any solution, please share it with the community, as it can be helpful to othe...
Tip: These steps are built out for AWS accounts and workspaces that are using Delta Lake. If you would like to learn more watch this video and reach out to your Databricks sales representative for more information.Step 1: Create your own notebook or ...
Our use case is simple - to store our PB scale data and transform and use for BI, reporting and analytics. As my title says am trying to eliminate expenditure on Redshift as we are starting as a green field. I know I have designed/used just Delta lak...
Hi @Swetha Marakani Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Th...
Dear Team,While i was doing hands on practice from the course - Delta Lake Rapid Start with Pythonhttps://customer-academy.databricks.com/learn/course/97/delta-lake-rapid-start-with-pythoni have come across false as the output dbutils.fs.rm(health_t...
Consider a table that gets partitioned on a date field. But, I'm filtering a column that is not partitioned. Now, with this filter condition whether all the files are parsed to attain the required result set, or does any data skipping happens?
DearsI was trying to check what Azure Databricks VM type is best suited for executing OPTIMIZE with ZORDER on a single timestamp value (but string data type) column for around 5000+ tables in the Delta Lake.I chose Standard_F16s_v2 with 6 workers & 1...
We are using delta lake time travelling capability in our current project. We can use select * from timestamp/versionAsOF query. However ,there might be some change in our approach and we might need to recreate the delta lake while persisting the tim...
Hi @Priyanka Mane , We haven't heard from you on the last response from @Debayan Mukherjee , and I was checking back to see if his suggestions helped you. Or else, If you have any solution, please share it with the community as it can be helpful to...
Hey guys,We're considering Delta Lake as the storage for our project and have a couple questions. The first one is what's the pricing for Delta Lake - can't seem to find a page that says x amount costs y.The second question is more technical - if we...
delta lake itself is free. It is a file format. But you will have to pay for storage and compute of course.If you want to use Databricks with delta lake, it will not be free unless you use the community edition.Depending on what you are planning to...
I have set up a Spark standalone cluster and use Spark Structured Streaming to write data from Kafka to multiple Delta Lake tables - simply stored in the file system. So there are multiple writes per second. After running the pipeline for a while, I ...
Hey there @Kim Abasch Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you....
I have a feature table in BQ that I want to ingest into Delta Lake. This feature table in BQ has 100TB of data. This table can be partitioned by DATE.What best practices and approaches can I take to ingest this 100TB? In particular, what can I do to ...