- 1236 Views
- 3 replies
- 9 kudos
- 1236 Views
- 3 replies
- 9 kudos
Latest Reply
- 9 kudos
Hi, @Vidula Khanna, the new version of Databricks still has only 2.12 scala support.
- 9 kudos
Hi, @Vidula Khanna, the new version of Databricks still has only 2.12 scala support.
I could able to parse .doc extension files using Java programming with the help of POI libraries but when trying to convert Java code into Scala i expect it has to work with same java libraries with Scala programming but it is showing with below erro...
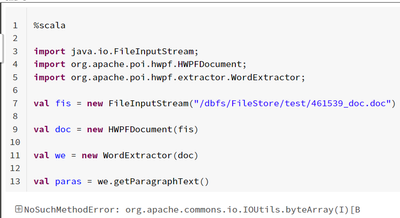

Hi @Ramesh Bathini In pyspark, we have a docx module. I found that to be working perfectly fine. Can you try using that ?Documentation and stuff could be found online. Cheers...
I am trying to read a sql file in the repo to string. I have triedwith open("/Workspace/Repos/xx@***.com//file.sql","r") as queryFile: queryText = queryFile.read()And I get following error.[Errno 1] Operation not permitted: '/Workspace/Repos/***@*...
I checked in my unity_catalog enabled cluster, i am able to access the @repos file to read and display
Databricks supports SQL, Scala, Python, and R. Is there a most performant language to use on Databricks? I know SQL well but would like to get into one of the other languages and don't know which to focus on.
It total depends on you? BTW, you can choose Python and SQL
import org.apache.spark.sql._import scala.collection.JavaConverters._import com.microsoft.azure.eventhubs._import java.util.concurrent._import scala.collection.immutable._import org.apache.spark.eventhubs._import scala.concurrent.Futureimport scala.c...
The dataframe to write needs to have the following schema:Column | Type ---------------------------------------------- body (required) | string or binary partitionId (*optional) | string partitionKey...
Hi All, We are developing a new Scala/Java program which needs to read & process the raw data stored in source ADLS (which is a Databricks Environment) in parallel as the volume of the source data is very high (in GBs & TBs). What kind of connection ...
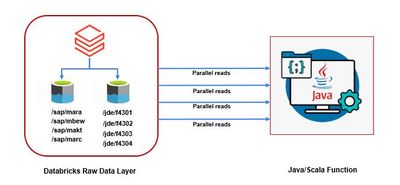
hello experts. any advise on this question ?? tagging some folks from whom I have received answers before. Please help on this requirement or tag someone who can help on this@Kaniz Fatma , @Vartika Nain , @Bilal Aslam
I wish to run a scala command, which I believe would normally be run from a scala command line rather than from within a notebook. It happens to be:scala [-cp scalatest-<version>.jar:...] org.scalatest.tools.Runner [arguments](scalatest_2.12__3.0.8.j...
Hi @David Vardy Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Thanks...
How to Install Libraries on DatabricksYou can install libraries in Databricks at the cluster level for libraries commonly used on a cluster, at the notebook-level using %pip, or using global init scripts when you have libraries that should be install...
It can be a risky to install libraries without any sort of oversite/security structure to ensure those libraries have no vulnerabilities. I think more caution needs to be added to the wording of these documents to express that. All of the libraries w...
Hello Guys,I am new to databricks. I have try to read the documentation as much I can. Now I want to jump in. What I Want : I have store my parquet file in Databricks storage system. I want to load this file into Data Lake Table. And then want to do ...
Hi @Learner bricks Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Tha...
As shown in the figure, the case class and the json string are converted through fasterxml.jackson, but an unexpected error occurred during the running of the code. I think this problem may be related to the loading principle of the notebook. Because...


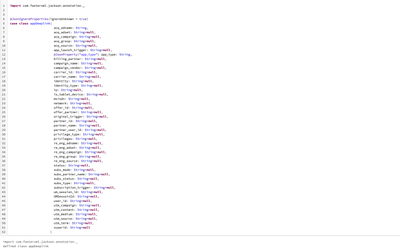
code:var str="{\"app_type\":\"installed-app\"}" import com.fasterxml.jackson.databind.ObjectMapper import com.fasterxml.jackson.module.scala.DefaultScalaModule val mapper = new ObjectMapper() mapper.registerModule(DefaultScalaModule) ...
I am working in a migration project, where lift and shift method is used to migrate SQL server DB from onprem to AZure Cloud. There are a lot of stored procedures used for integration in On prem. Now here in On prem , to process the XMl file and exec...
Hi @shafana Roohi Jahubar I hope that your queries are answered. Please let me know if you have more doubts.
What version of Spark, Python, Scala, R are included in each Databricks Runtime? What libraries are pre-installed?You can find this info at the Databricks runtime releases page (AWS | Azure | GCP).Let us know if you have any additional questions on t...
Wow! Thanks for the help @Isaac Gritz !
We need to hit REST web service every 5 mins until success message is received. The Scala object is inside a Jar file and gets invoked by Databricks task within a workflow.Thread.sleep(5000) is working fine but not sure if it is safe practice or is t...
Hey there @Sundeep P Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.C...
is DLT supported for Scala? Any reference implementations or wikis to get started?
Hi @Karthik Munipalle, Delta Live Tables queries can be implemented in Python or SQL.Here are few articles best explaining about DLT. Please have a look.https://docs.databricks.com/data-engineering/delta-live-tables/index.htmlhttps://databricks.com/...
I am facing issue in while accessing python data frame in Scala shell and vice versa. I am getting error variable not defined.
The context is not shared between Scala and Python so you won't be able to access the same variables directly. However you can use createOrReplaceTempView to create a temporary view of your dataframe and read it in the other language with read_df = s...