Hello All,In my Databricks workflows, I have three tasks configured, with the final task set to run only if the condition "ALL_DONE" is met. During the first deployment, I observed that the dependency "ALL_DONE" was correctly assigned to the last tas...
After updating my CLI, I successfully deployed the job from Databricks CLI and it is functioning correctly. However, when attempting to deploy the same job using Azure DevOps, I encounter the same issue.
In JupyterLab notebooks, we can --In edit mode, you can press Ctrl+Shift+Minus to split the current cell into two at the cursor position In command mode, you can click A or B to add a cell Above or Below the current cellare there equivalent shortcuts...
What's the status of the ctrl-alt-minus shortcut for splitting a cell? That keyboard combination does absolutely nothing in my interface (running Databricks via Chrome on GCP).
Hello,I am attempting to configure Autoloader in File Notification mode with Delta Live Tables. I configured an instance profile, but it is not working because I immediately get AWS access denied errors. This is the same issue that is referenced here...
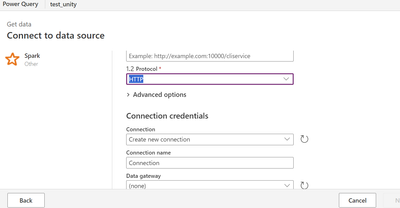
Hi All,Currently I trying to connect databricks Unity Catalog from Powerapps Dataflow by using spark connector specifying http url and using databricks personal access token as specified in below screenshot: I am able to connect but the issue is when...
I install the newest version "databricks-connect==13.0.0". Now get the issue Command C:\Users\Y\AppData\Local\pypoetry\Cache\virtualenvs\X-py3.9\Lib\site-packages\pyspark\bin\spark-class2.cmd"" not found konnte nicht gefunden werden. Traceback...
I am trying to schedule some jobs using workflows and leveraging dynamic variables. One caveat is that when I try to use {{job.start_time.[iso_date]}} it seems to be defaulted to UTC, is there a way to change it?
Hi, all the dynamic values are in UTC (documentation).
Maybe you can use the code like the one presented below + pass the variables between tasks (see Share information between tasks in a Databricks job) ?
%python
from datetime import datetime, timed...
from pyspark.sql import functions as F
from pyspark.sql import types as T
from pyspark.sql import DataFrame, Column
from pyspark.sql.types import Row
import dlt
S3_PATH = 's3://datalake-lab/XXXXX/'
S3_SCHEMA = 's3://datalake-lab/XXXXX/schemas/'
...
Just want to post this issue we're experiencing here in case other people are facing something similar. Below is the wording of the support ticket request I've raised:SQL code that has been working is suddenly failing due to syntax errors today. Ther...
Hi Team,Please provide guidance on enabling SQL cells parallel execution in a notebook containing multiple SQL cells. Currently, when we execute notebook and all the SQL cells they run sequentially. I would appreciate assistance on how to execute th...
Hi @Phani1 ,Can you please explain your usecase as databricks notebook support the sequential executions we have to look for workaround so it will great if you can explain it more.For now you can manually run multiple cell for sql but it's not possib...
Hi Team,We are currently planning to implement Databricks cell-level code parallel execution through the Python threading library. We are interested in comprehending the resource consumption and allocation process from the cluster. Are there any pot...
If I do this%sqlcreate or replace temporary view myviewasselect * from silver.<schema>.<table>;SHOW VIEWS;select * from myview;It works. But if I do the same on a Shared Compute it fails with[TABLE_OR_VIEW_NOT_FOUND] The table or view `myview` cannot...
How/how many databricks notebooks should be created to populate multiple silver delta tables, all having different and complex transformations ? What's the best practice -1. create a single reusable notebook each for a silver table ?2. push SQL trans...
You can find more information on that topic here.
"With Databricks, your serverless workloads are protected by multiple layers of security. These security layers form the foundation of Databricks’ commitment to providing a secure and reliable environ...
Hi Team,Hi Team,Is it feasible to run pyspark cells concurrently in databricks notebooks? If so, kindly provide instructions on how to accomplish this. We aim to execute the intermediate steps simultaneously.The given scenario entails the simultaneou...
Hi @Phani1, You can run PySpark cells concurrently in Databricks Notebooks.
To achieve this, consider the following approaches:
Using dbutils.notebook.run():
The simplest way is to utilize the dbutils.notebook.run() utility. You can call it from ...
Hi @DLL, It seems like there might be some confusion or an issue with how the dataset is being loaded or processed. Could you please provide more details about which columns are being dropped and how you are moving the dataset to a pandas DataFrame?
...