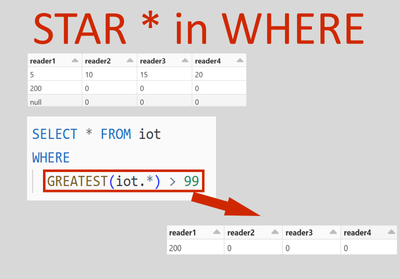
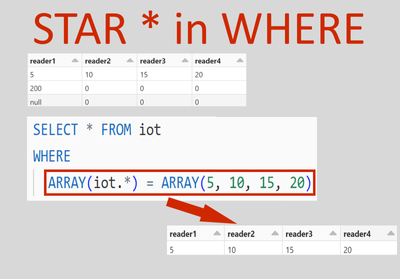
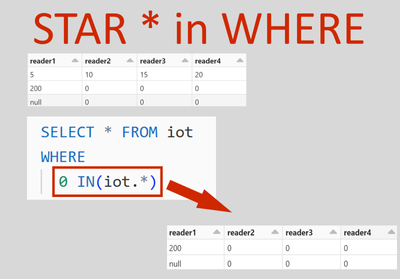
I need help with migrating from dbfs on databricks to workspace. I am new to databricks and am struggling with what is on the links provided.My workspace.yml also has dbfs hard-codedThis was done by an external vendor.
Hi Team,Please provide guidance on enabling SQL cells parallel execution in a notebook containing multiple SQL cells. Currently, when we execute notebook and all the SQL cells they run sequentially. I would appreciate assistance on how to execute th...
Hi @mrtellerz good day!
I believe this document might help you: https://learn.microsoft.com/en-us/azure/databricks/notebooks/notebooks-code#--execute-sql-cells-in-parallel
Best regards,
Hello All,In my Databricks workflows, I have three tasks configured, with the final task set to run only if the condition "ALL_DONE" is met. During the first deployment, I observed that the dependency "ALL_DONE" was correctly assigned to the last tas...
We have around 1800 tables in Parq format (Delta Lake). These 1800 tables are very big, we have all these 1800 tables are converted into tables. But we have a requirement that, we need to download in CSV. (from PowerBI / any other reporting tool). Cu...
Dear Kaniz,Thank you. one doubt 1) converting tables data into CSV and saving again one more of storage layer.IS there any way on fly we can convert these tables into CSV's. and export into PowerBI? and again i see in powerBI has limitations around >...
Hi Team,Please provide guidance on enabling SQL cells parallel execution in a notebook containing multiple SQL cells. Currently, when we execute notebook and all the SQL cells they run sequentially. I would appreciate assistance on how to execute th...
Hi @Phani1 ,Can you please explain your usecase as databricks notebook support the sequential executions we have to look for workaround so it will great if you can explain it more.For now you can manually run multiple cell for sql but it's not possib...
Hello all.We are a new team implementing DLT and have setup a number of tables in a pipeline loading from s3 with UC as the target. I'm noticing that if any of the 20 or so tables fail to load, the entire pipeline fails even when there are no depende...
I have the following code:spark.sparkContext.setCheckpointDir("dbfs:/mnt/lifestrategy-blob/checkpoints")
result_df.repartitionByRange(200, "IdStation")
result_df_checked = result_df.checkpoint(eager=True)
unique_stations = result_df.select("IdStation...
it seems like there is a filter being apply according to this.
Filter (isnotnull(IdStation#2678) AND (IdStation#2678 = 1119844))
I would like to share the following notebook that covers in detail this topic, in case you would like to check it out h...
If I do this%sqlcreate or replace temporary view myviewasselect * from silver.<schema>.<table>;SHOW VIEWS;select * from myview;It works. But if I do the same on a Shared Compute it fails with[TABLE_OR_VIEW_NOT_FOUND] The table or view `myview` cannot...
Since we enable RocksDB in our spark.conf the stream to stream joins/unions results in empty dataframe, does anyone else have the same experience? it is on AWSspark.conf.set("spark.sql.streaming.stateStore.providerClass","com.databricks.sql.streaming...
Hi there,Im trying to run DE 2.1 - Querying Files Directly on my workspace with a default cluster configuration for found below,but I cannot seem to run this file (or any other labs) as it gives me this error message Resetting the learning environme...
Hi Databricks community,Hope you are doing well.I am trying to create an external table using a Gzipped CSV file uploaded to an S3 bucket.The S3 URI of the resource doesn't have any file extensions, but the content of the file is a Gzipped comma sepa...
I was exploring on unity catalog option on Databricks premium workspace.I understood that i need to create storage account credentials and external connection in workspace.Later, i can access the cloud data using 'abfss://storage_account_details' .I ...
Databricks strategic direction is to deprecate mount points in favor of Unity Catalog Volumes.Setup an STORAGE CREDENTIAL and EXTERNAL LOCATION to access and define how to get to your cloud storage account. To access data on the account, define a Tab...
Hello everyone,I work as a Business Intelligence practitioner, employing tools like Alteryx or various low-code solutions to construct ETL processes and develop data pipelines for my Dashboards and reports. Currently, I'm delving into Azure Databrick...
In my SQL data transformation pipeline, I'm doing chained/cascading window aggregations: for example, I want to do average over the last 5 minutes, then compute average over the past day on top of the 5 minute average, so that my aggregations are mor...