Today, the entire private limited company registration process and other regulatory filings are paperless; documents are filed electronically through the MCA website and is processed at the Central Registration Centre (CRC). The Online Private Limite...
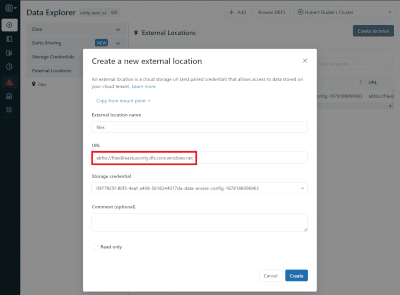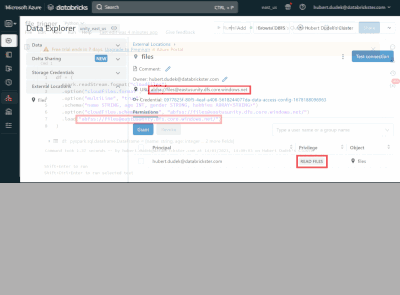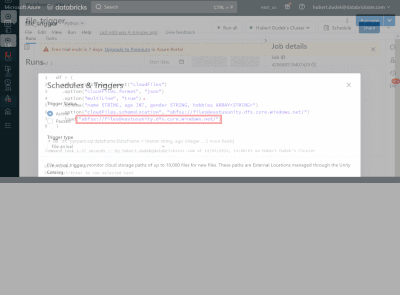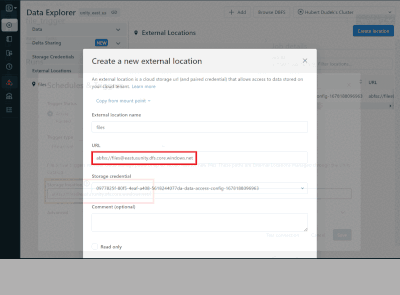
Databricks now supports event-driven workloads, especially for loading cloud files from external locations. This means you can save costs and resources by triggering your Databricks jobs only when new files arrive in your cloud storage instead of mou...
@daniel_sahal I get your point, but if for a scheduled trigger you can get all kind of attributes on the trigger time (arguably, this is available for all the triggers), then why wouldn't the most important attribute of a file event not be available ...
I have an idea of sharing & trading IoT data streamlined from many data sources on the incentive platform.I would be appreciate it if you guys discuss with me about the idea.Thank you
Hello @Rene,Building an IoT data trading platform using Databricks is indeed a feasible and innovative idea. Databricks provides a unified analytics platform that can handle massive amounts of data processing and advanced analytics, which is essentia...
I have two clusters. Cluster A(spark cluster) and cluster B(SQL warehouse). whenever I try to run a particular query using cluster B, it works fine but whenever I try to run same query using cluster A. It's taking time and never show the output
I'm recieving this error from autoloader. It seems to be stuck on this one file. I don't care when it was read and last modified, I just want to ingest it. Any ideas?java.io.IOException: Read old version of file s3a://<file-path>.json. Read modificat...
In the documentation for enabling iceberg compatibility on delta tables, it states that the minReaderVersion for IcebergCompatV1 and IcebergCompatV2 is 2 (https://docs.databricks.com/en/delta/uniform.html#requirements).However, when you run the REORG...
@stevenayers-bge I've just checked source code of delta and you're right - documentation states that tat minReaderVersion should be >=2, but source code is upgrading it to 3https://github.com/delta-io/delta/blob/78970abd96dfc0278e21c04cda442bb05ccde4...
Hello,We have unity catalog enabled workspace. To get the completion time of a pipeline that runs multiple times a day, I am checking system.access.audit table. Comparing the completion time of the pipeline compared to other pipeline time I am creat...
@angel_ba System tables are still in public preview thus there are some limitations, one of them is a blocker for your use case.Currently no support for real-time monitoring. Data is updated throughout the day. If you don’t see a log for a recent eve...
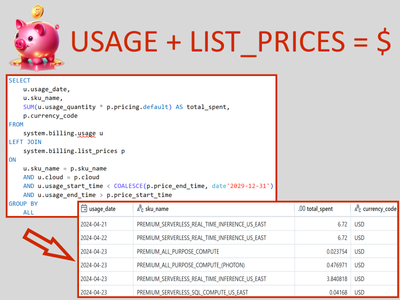
Join two system tables and get exactly how much USD you are spending.The short version of the query: SELECT
u.usage_date,
u.sku_name,
SUM(u.usage_quantity * p.pricing.default) AS total_spent,
p.currency_code
FROM
system.billing....
Parameters can be passed to Tasks and the values can be retrieved with:dbutils.widgets.get("parameter_name")More recently, we have been given the ability to add parameters to Jobs.However, the parameters cannot be retrieved like Task parameters.Quest...
@Kaniz This method works for Task parameters. Is there a way to access Job parameters that apply to the entire workflow, set under a heading like this in the UI:I am able to read Job parameters in a different way from Task parameters using dynamic v...
Hi, Is there any connectivity pipeline established already to access MuleSoft or AnyPoint exchange data using Databricks. I have seen many options to access databricks data in mulesoft but can we read the data from Mulesoft into databricks. Please gi...
I have the following code:spark.sparkContext.setCheckpointDir("dbfs:/mnt/lifestrategy-blob/checkpoints")
result_df.repartitionByRange(200, "IdStation")
result_df_checked = result_df.checkpoint(eager=True)
unique_stations = result_df.select("IdStation...
Thanks a lot for your response. It seems the Filter is not pushed down, no? station_df.explain()
== Physical Plan ==
*(1) Filter (isnotnull(IdStation#2678) AND (IdStation#2678 = 1119844))
+- *(1) Scan ExistingRDD[Date#2718,WindSpeed#2675,Tower_Accele...
When running my notebook using personal compute with instance profile I am indeed able to readStream from kinesis. But adding it as a DLT with UC, while specifying the same instance-profile in the DLT pipeline setting - causes a "MissingAuthenticatio...
I am currently trying to use this feature of "Trigger jobs when new file arrive" in one of my project. I have an s3 bucket in which files are arriving on random days. So I created a job to and set the trigger to "file arrival" type. And within the no...
Looks like a major oversight not to be able to get the information on what file(s) have triggered the job. Anyway, the above explanations given by Anon read like the replies of ChatGPT, especially the scenario where a dataframe is passed to a trigger...
I use AWS Databricks which has an SSO&Scim integration with AAD. I generated an SPN in AAD, synced it to Databricks, and want to use this SPN with using AAD client secrets to use Databricks SDK. But it doesnt work. I dont want to generate another tok...
I have a DLT pipeline, where all tables are non-streaming (materialized views), except for the last one, which needs to be append-only, and is therefore defined as a streaming table.The pipeline runs successfully on the first run. However on the seco...