Hi,I am unable to link my Databricks Lakehouse Fundamentals badge to my Linkedin account.I couldn't sign in to credential.databricks.com webpage.My email id is : abhishek.palit@ageas.com.hk
If you're having trouble linking your Databricks Lakehouse Fundamentals badge to your LinkedIn Sales Navigator extension, there are a few things you can try:Check your badge settings: Make sure that you have enabled sharing for your badge and that yo...
We are migrating our Scala jobs from AWS EMR (6.2.1 and Spark version - 3.0.1) to Lakehouse and few of our jobs are failing due to NullPointerException. We tried in Databricks Runtime 7.3 LTS, it is working fine. Because it had same spark version 3.0...
In one of my code statements, I updated scala Boolean to java.lang.Boolean and this is working fine now. May be in new newer Spark versions, null in scala Boolean isn't supported.
An S3 bucket with the prefix "databricks-workspace-stack-lambdazipsbucket" was created by default when I created my AWS Databricks account. It is set to public access. It has one zip file in it called "lambda.zip". What is the purpose of this S3 buck...
Hi @Dian Germishuizen Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best ans...
https://community.cloud.databricks.com/login.htmlUnable to Login and Unable to reset Password . Password reset link keeps on loading even after entering passwords
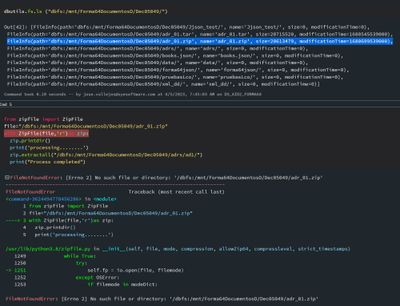
Hello, how are you? I have a small problem. I need to unzip some .zip, tar files. and gz inside these may have multiple files trying to unzip the .zip files i got this errorFileNotFoundError: [Errno 2] No such file or directory: but the files are in ...
Hi @Alfredo Vallejos Thank you for your question! To assist you better, please take a moment to review the answer and let me know if it best fits your needs.Please help us select the best solution by clicking on "Select As Best" if it does.Your feed...
Hi All,There is a CSV with a column ID (format: 8-digits & "D" at the end).When trying to read a csv with .option("inferSchema", "true"), it returns the ID as double and trim the "D". Is there any idea (apart from inferSchema=False) to get correct ...
Hi @tracy ng Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answers your...
@Kaniz Fatma I have cleared the certification exam on 26th January 2023, but still haven't received the certificate. I had given the exam with a different mail ID but I'm not receiving any emails from Databricks to that mail ID.Kindly help me resolv...
Hi @Naeemah Khatib Hope everything is going great.Just wanted to check in if you were able to resolve your issue. If yes, would you be happy to mark an answer as best so that other members can find the solution more quickly? If not, please tell us s...
Hi, can anybody answer this question I posted on StackOverflow? https://stackoverflow.com/questions/73314048/databricks-how-to-exit-the-entire-job-in-the-notebooks-orchestration-scenario
@Vidula Khanna @Vidula Khanna We are experiencing the same issue in our Workflows and I was wondering if there has been any update.We need the functionality to call a method similar to `dbutils.notebook.exit` in a notebook that will cancel the exec...
I'm trying to create a simple UI for a notebook using the recently implemented support for ipywidgets, but I'm having a hard time figuring out how to change certain style attributes like font size and color in widgets that should accept those style p...
Hey Michael,The example you're trying to run is for ipywidgets 8, we currently have ipywidgets 7-which has fewer button customizations. I believe the only font customization available in 7 is "font_weigh t" (no space). I hope this helps.Best,Miguel
Hi team,Could everyone please help explain about the Charity and Charity Name in "Data + AI Summit 2023: VIP ALL-Access Pass" in the Reward Store? I don't know what it means.Thanks and Best Regards,Jensen Nguyen
I recently watched a Data + AI keynote from 2022 and it was announced there and in the below article. What is the status of this? I do not see it on my account; I am currently on a trial. If it is there, how do I get to it?https://www.databricks.com/...
I enrolled myself through the partner academy for Advanced Data Engineering with Databricks (North America) (Instructor-Led course) Just received this message saying my registration for Advanced Data Engineering with Databricks (North America) has be...
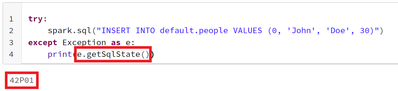
databricks SQL now supports getting the SQLSTATE code of a query to identify errors. You can use the e.getSqlState() method in a try/catch block to get the five-character code that indicates the success or failure of an SQL command. I am still thinki...
Hello @Kris Koirala, Thank you for reaching out to us on the Databricks community! It's great to see your enthusiasm for Databricks and Apache Spark.We do occasionally have swag giveaways, including stickers, during events and conferences. However, ...