Hi everyone!I am trying to run pytest inside a notebook on repos and store the results inside dbfs but i am getting an error stating permission denied, does anyone know why this happens and the solution. Error:
Hi @João Peixoto Hope everything is going great.Just wanted to check in if you were able to resolve your issue. If yes, would you be happy to mark an answer as best so that other members can find the solution more quickly? If not, please tell us so ...
Hi @Vidula Khanna , Recently there has been too many spams posted in the community discussions. I'm sure you might have noticed them. Is there any chance to clear all of them and may be restrict them in some way so that the purpose of this community...
@Suteja Kanuri using Azure OpenAI GPT4 we could connect it to the community and use 2 features of it.Ask the question, "is it spam?" and verify the user post this way.Display ready answers by OpenAI so we will avoid asking over and over again duplic...
Hi @Venkata Krishna Jonnalagadda Hope you are well.Just checking in. If @John Lourdu's answer helped, would you let us know and mark the answer as best? If not, would you be happy to give us more information?Thanks!
Hi @William Scardua We haven't heard from you since the last response from @josephk and I was checking back to see if it helped you.Or else, If you have any solution, please share it with the community, as it can be helpful to others. Also, Please d...
How to create a new group in the Databricks community?Dear esteemed community users,It is with great pleasure that we inform you of an important update regarding the creation of Groups on Community. As part of our continuous efforts to enhance your e...
HI @Hubert Dudek and @Ratna Chaitanya Raju Bandaru : Thanks for pointing this out. This is going to be a design decision which we will take after looking into the ask carefully. Thanks for getting the conversation going. This really helps us.
Last week, around the 21st of march, we started having issues with databricks-connect (DBR 9.1 LTS). "databricks-connect test" works, but the following code snippet:from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
s...
Hi @Jordi Dekker Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answers ...
Hi @Govardhana Reddy Hope everything is going great.Does @Suteja Kanuri's answer help? If yes, would you be happy to mark an answer as best so that other members can find the solution more quickly? If not, please tell us so we can help you. Cheers!
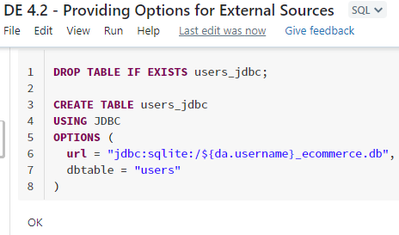
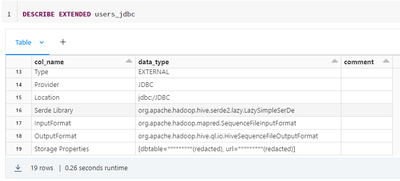
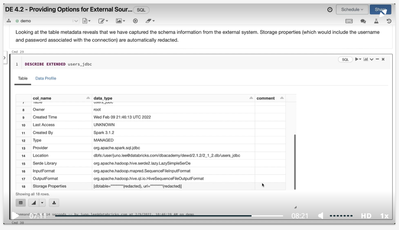
While following the video lesson and executing the notebook 4.2, I noticed that creating the CREATE Table "users_jdbc" command generates an EXTERNAL table, while the video and, notebook too, suggests it as being a Managed table.Here are some printscr...
Hi @Tiago Barata Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Thank...
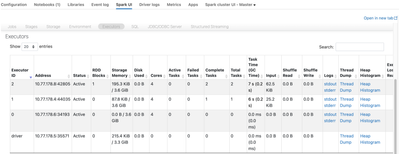
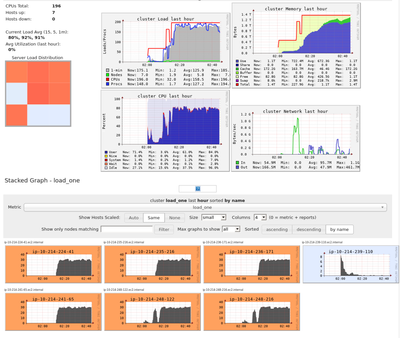
Hi, I have a Pyspark job that takes about an hour to complete, when looking at the SQL tab on Spark UI I see this:Those processes run for more than 1 minute on a 60-minute process.This is Ganglia for that period (the last snapshot, will look into a l...
Hi @Alejandro Martinez Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you...
I have a delta table that is partitioned by Year, Date and month. I'm trying to merge data to this on all three partition columns + an extra column (an ID). My merge statement is below:MERGE INTO delta.<path of delta table> oldData
using df newData ...
Isn't the suggested idea only filtering the input dataframe (resulting in a smaller amount of data to match across the whole delta table) rather than prune the delta table for relevant partitions to scan?
Hi all,I've just encountered with this issue. Before I launched an My SQL database in RDS of AWS after use this simple code to create connection to it but it all fails with this error.Is there any additional step? or could anyone can take a look on i...
Hello, It looks issue with JDBC URL. When I am trying to access the Azure SQL database. I was facing the same issue. So I have created JDBC URL as below and it went well.jdbc:sqlserver://<serverurl>:1433;database=<databasename>;user=<username>@<serve...
Division of two numbers is auto truncating decimals and I can't get a more precise result.Example of things I've tried:10 / 60 => 0.17cast(10 as float) / cast(60 as float) => 0.17cast(cast(10 as float) / cast(60 as float) as float) => 0.17round(10 / ...
Hi @Alex Python Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answers y...
I imported .dbc notebook using url successfully but I can't be able to import using upload file option and I didn't get either any error message or anything when I tried to import using upload file option.
Hi @Raj Sethi We haven't heard from you since the last response from @Lakshay Goel and @Vigneshraja Palaniraj , and I was checking back to see if her suggestions helped you.Or else, If you have any solution, please share it with the community, a...
I'm using spark version 3.2.1 on databricks (DBR 10.4 LTS), and I'm trying to convert sql server sql query to a new sql query that runs on a spark cluster using spark sql in sql syntax. However, spark sql does not seem to support XML PATH as a functi...
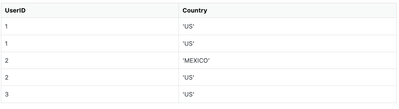
Posting the solution that I ended up using:%sql
DROP TABLE if exists UserCountry;
CREATE TABLE if not exists UserCountry (
UserID INT,
Country VARCHAR(5000)
);
INSERT INTO UserCountry
SELECT
L.UserID AS UserID,
CONCAT_WS(',', co...