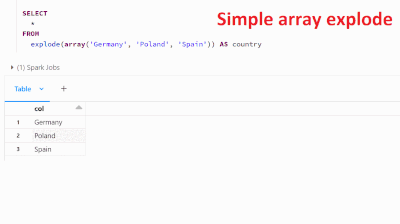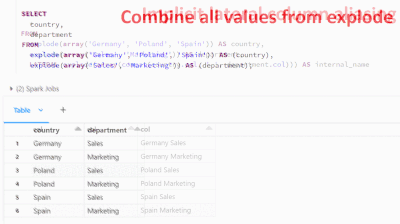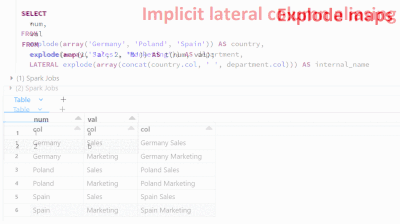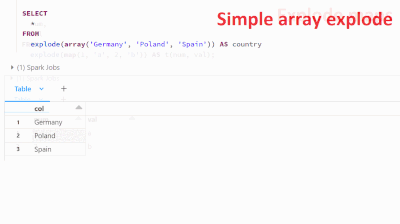
Starting from databricks 12.2 LTS, the explode function can be used in the FROM statement to manipulate data in new and powerful ways. This function takes an array column as input and returns a new row for each element in the array, offering new poss...
Hi,Assume that I have a delta table stored on an Azure storage account. When new records arrive, I repeat the transformation and overwrite the existing table. (DF.write
.format("delta")
.mode("overwrite")
.option("...
the overwrite will add new files, keep the old ones and in a log keeps track of what is current data and what is old data.If the overwrite fails, you will get an error message in the spark program, and the data to be overwritten will still be the cur...
Hello. Is there a way in Databricks sql to convert a date to integer? In Db2, there is days function DAYS - IBM Documentation .For example '2023-03-01' is converted to 738580 value.Thank you in advance
TRy this:CREATE OR REPLACE FUNCTION days(dt DATE) RETURN unix_date(dt) - unix_date(DATE'0001-01-01') + 1;SELECT current_date, days(current_date); 2023-03-09 738588I verified on Db2 for LUW and it matches up.
Hello,I am unable to import tkinter (or Tkinter) into a python notebook.I also tried %pip install tkinter at the top of the notebook.Has anyone else been successful at this, or if it's impossible, why? Thank you
Hi @Haylee Gaddy,Just a friendly follow-up. Did any of the responses help you to resolve your question? if it did, please mark it as best. Otherwise, please let us know if you still need help.
Is it possible to use a calculated column (as like in the delta table using generatedAlwaysAs) definition while writing the data frame as a delta file like df.write.format("delta").Any options are there with the dataframe.write method to achieve this...
Hi @Thushar R ,This option is not a part of Dataframe write API as GeneratedAlwaysAs feature is only applicable to Delta format and df.write is a common API to handle writes for all formats. If you to achieve this programmatically, you can still use...
I predefined my schema for a Delta Live Table Autoload. This included comments for some attributes. When performing a standard readStream, my comments appear, but when in Delta Live Tables I get no comments. Is there anything I need to do get comment...
Hi @Dave Wilson , We haven’t heard from you since the last response from @Debayan Mukherjee and @Hubert Dudek, and I was checking back to see if you have a resolution yet. If you have any solution, please share it with the community as it can be ...
I am working on Databricks Notebook and trying to display a map using Floium and I keep getting this error > Command result size exceeds limit: Exceeded 20971520 bytes (current = 20973510)How can I get increase the memory limit?I already reduced the...
Hi, I have the same problem with keplergl, and the save to disk option, whilst helpful isn't super practical... So how does one plot large datasets in kepler?Any thought welcome
I created the below tables but when I click the lineage graph not able to see the upstream or downstream table .... the + sign goes away after a few sec but not able to click it ... anyone else having this issue?CREATE TABLE IF NOT EXISTS
lineage_d...
Hi @Raj Sharma Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Thanks!
Hi i have a blob storage with multile unzip folders with the same suffix folder_report_name_01_2023_01_02 -> file_name_2023_01_02.xlsxBut i want to load all of this data using pandas or pyspark and insert in my delta table.I'm trying to using widget...
Hi @Fernando Vázquez Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.T...
I was following the tutorial about data transformation with azure databricks, and it says before loading data into azure synapse analytics, the data transformed by azure databricks would be saved on temp storage in azure blob storage first before loa...
@Ajay Pandey Saving the transformed data to temporary storage in Azure Blob Storage before loading into Azure Synapse Analytics provides a number of benefits to ensure that the data is accurate, optimized, and performs well in the target environmen...
Is there an upper bound of number that i can assign to delta.dataSkippingNumIndexedCols for computing statistics. Is there some tradeoff benchmark available for increasing this number beyond 32.
@Chhavi Bansal :The delta.dataSkippingNumIndexedCols configuration property controls the maximum number of columns that Delta Lake will build statistics on during data skipping. By default, this value is set to 32. There is no hard upper bound on th...
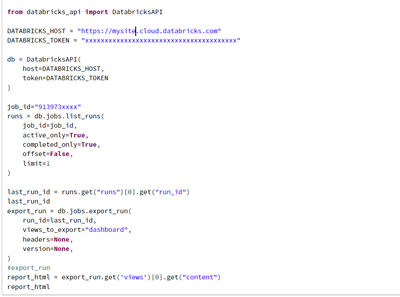
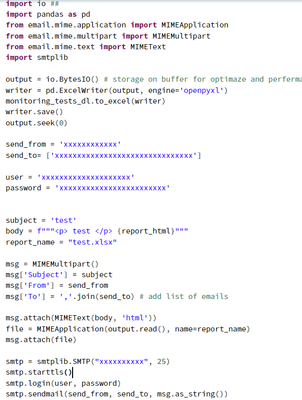
hi everyone, i would like to export my dashbord in html format and embed it in my body of my email in order to send it to my teamso there is my code python for the databriks api and i got this error and when i put my htm in the body of my message i...
@mathild noun :import databricks.workspace as workspace_api
import requests
# set up your Databricks workspace credentials
domain = "<your Databricks workspace domain>"
token = "<your Databricks API token>"
# set up the workspace client
workspac...
Hi All, I am trying to understand the internals shuffle hash join. I want to check if my understanding of it is correct. Let’s say I have two tables t1 and t2 joined on column country (8 distinct values). If I set the number of shuffle partitions as ...
@Vinay Emmadi : In Spark, a hash shuffle join is a type of join that is used when joining two data sets on a common key. The data is first partitioned based on the join key, and then each partition is shuffled and sent to a node in the cluster. The ...
Hello,I know how to create .shp file from Geopandas dataframe using code similar to this, also mentioned on SO:gpd_df = geopandas.GeoDataFrame(pandas_df, geometry='geom')
gpd_df .to_file("username/nh.shp")However I have .parquet files that I can load...
@Bartosz Maciejewski :Spark does not have native support for writing Shapefiles directly. However, you can use a third-party library such as GeoPandas or PyShp to write your Spark DataFrame to a Shapefile.Here's an example of how to use GeoPandas to...