I am working on Google Cloud and want to create Databricks workspace with custom VPC using terraform. Is that supported ? If yes is it similar to AWS way ?Thank youHoratiu
Hi @horatiu guja GCP Workspace provisioning using Terraform is public preview now. Please refer to the below doc for the steps.https://registry.terraform.io/providers/databricks/databricks/latest/docs/guides/gcp-workspace
Hi!I saved a dataframe as a delta table with the following syntax:(test_df
.write
.format("delta")
.mode("overwrite")
.save(output_path)
)How can I issue a SELECT statement on the table?What do I need to insert into [table_name] below?SELECT ...
Hi @John B there is two way to access your delta table-SELECT * FROM delta.`your_delta_table_path`df.write.format("delta").mode("overwrite").option("path", "your_path").saveAsTable("table_name")Now you can use your select query-SELECT * FROM [table_...
Hello there @G Z I would say "we have a history of open sourcing our biggest innovations but there's no concrete timeline for dlt. It's built on the open APIs of spark and delta, so the most important parts (your transformation logic and you data) ...
Hi - I have created a Databricks job - under Workflow - its running fine without any issues . I would like to promote this job to other workspaces using a script.Is there a way to script the job definition and deploy it across multiple workspaces .I ...
We are trying to connect Azure Databricks Cluster to Azure SQL database but the firewalls at SQL level is causing an issue.Whitelisting dbks subnet is not an option here as both the resources are in two different azure regions. Is there a secure way ...
Hi @Timir Ranjan,Have you tried looking into private endpoints? This allows you to expose your Azure SQL database from the Azure backbone and is cross-regional supported.https://learn.microsoft.com/en-us/azure/private-link/private-endpoint-overviewP...
I'm new to databricks. (Not new to DB's - 10+ year DB Developer).How do you generate a MERGE statement in DataBricks? Trying to manually maintain a 500+ or 1000+ lines in a MERGE statement doesn't make much sense? Working with Large Tables of between...
In my opinion, when possible MERGE statement should be on the primary key. If not possible you can create your own unique key (by concatenate some fields and eventually hashing them) and then use it in merge logic.
Im trying to get the lineage graph to work in Unity catalog, however nothing seems to appear even though I followed the docs. I did the following steps1. Created a Unity metastore and attached the workspace to that metastore.2. Created a Single user ...
@Stephan Smit We finally got a solution from level 3 support (Databricks support).You may check your firewall logs.On our side, we had to open communication to "Event Hub endpoint".The destination depends on your workspace region: Azure Databricks r...
Are there any event streams that are or could be exposed in AWS (such as Cloudwatch Eventbridge events or SNS messages? In particular I'm interested in events that detail jobs being run. The use case here would be for monitoring jobs from our web app...
Yes, there are several event streams in AWS that can be used to monitor jobs being run. Your Texas BenefitsCloudWatch Events: This service allows you to set up rules to automatically trigger actions in response to specific events in other AWS service...
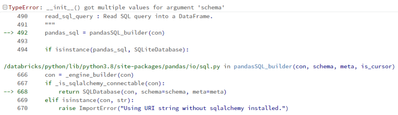
EnvironmentAzure Databricks 10.1, including Spark 3.2.0ScenarioI want to retrieve the average of a series of values between two timestamps, using a SQL UDF.The average is obviously just an example. In a real scenario, I would like to hide some additi...
Hi databricks community,I have searched quite a while through the internet but did not find an answer. If I have configured the azure datalake connection in Unity data catalog, is it possible to grant the access to users for a specific file or a fold...
As @werners said service principal needs to have access to the file level.In the unity catalog, you can use "READ FILES"/"WRITE FILES" permission to give someone the possibility of reading files from the storage level (but through databricks).
Hi there! I'm trying to use Azure DevOps Pipeline to automate Azure Databricks Repos API. Im using the following workflow:Get an Access Token for a Databricks Service Principal using a Certificate (which works great)Usage REST Api to generate Git Cre...
Hi, i am trying to load mongo into s3 using pyspark 3.1.1 by reading them into a parquet. My code snippets are like:df = spark \ .read \ .format("mongo") \ .options(**read_options) \ .load(schema=schema)df = df.coalesce(64)write_df_to_del...
So i think i have solved the mystery here it was to do with the retention config. By setting the retentionEnabled to True and rention hours being 0, we somewhat loses a few rows in the first file as they were mistaken as files from last session and ...
I am not able to login with my credentials. This is happening with me again and again.i have created different account then also,i am facing the same proble..please help me to resolve this issue...i am a new learner here
Hi @PREM RANJAN It might be a temporary issue, for any issue with Academy learning/certifications, you can raise a ticket in the below link, sharing it with you for your future reference as well.https://help.databricks.com/s/contact-us?ReqType=train...