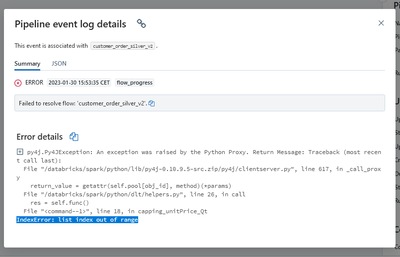
HI,I am tying to use the approxQuantile() function and populate a list that I made, yet somehow, whenever I try to run the code it's as if the list is empty and there are no values in it.Code is written as below:@dlt.table(name = "customer_order_silv...
Maybe try to use (and the first test in the separate notebook) standard df = spark.read.table("customer_order_silver") to calculate approxQuantile.Of course, you need to set that customer_order_silver has a target location in the catalog, so read us...
ERROR: Query termination received for [id=37bada03-131b-4fbb-8992-a427263fef2c, runId=cf3d7c18-780e-43ae-aed0-9daf2939b823], with exception: java.lang.IllegalArgumentException: Input byte array has wrong 4-byte ending unit at java.util.Base64$Decoder...
The issue could be due to the mismatch in the eventHub jar and the dependencies added. Also, not all the required dependencies may be added.Suggestions:Using the azure_eventhubs_spark_2_12_.jar eventHub spark jar along with the following dependencies...
I'd like to ingest data into my ADLS from sql server in an incremental manner using Delta Live Tables. I do not want to use any staging tables. I was using CDC, While I call dlt.apply_changes, its asking me to specify source and target. SInce source ...
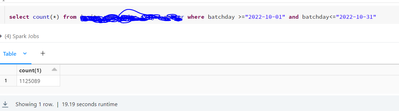
count of the table : 1125089 for october month data , So I am optimizing the table. optimize table where batchday >="2022-10-01" and batchday<="2022-10-31"I am getting error like : GC overhead limit exceeded at org.apache.spark.unsafe.types.UTF8St...
Hi @Nagini Sitaraman To understand the issue better I would like to get some more information. Does the error occur at the driver side or executor side? Can you please share the full error stack trace? You may need to check the spark UI to find wher...
Understanding Rename in DatabricksNow there are multiple ways to rename Spark Data Frame Columns or Expressions.We can rename columns or expressions using alias as part of selectWe can add or rename columns or expressions using withColumn on top of t...
we have a library that allows dotnet applications to talk to databricks clusters (https://github.com/clearbank/SparkSqlClient). This communicates with the clusters over the spark thrift serverAlthough this works great for clusters in the "data scienc...
I have tried those connection details however it they give me 400 errors when trying to connect directly using the hive thrift server contract (https://github.com/apache/hive/blob/master/service-rpc/if/TCLIService.thrift). I do not get the issues whe...
Greetings,Recently we were doing cleanups in AWS and removed some Databricks related resources that were used only once for setting up our workspace and were not used since then.Since there is no plan to create any other workspaces the decision was t...
The resources that were cleaned up were just the ones that were used for the initial setup of the workspace, everything else important for the day to day operation are in place and we are actively using the workspace, therefore there is no plan to de...
The Databricks Certified Data Engineer Professional exam most questions are too long for those English as second language. Not enough time to read through the questions and sometimes hard to comprehend
I strongly agree with you. There is not a Spanish version of this exam. Those exam are long even for native speakers just imagine for people with English as a second language. For instance, since Amazon does not have a Spanish version, they took this...
I have a dataframe that inexplicably takes forever to write to an MS SQL Server even though other dataframes, even much larger ones, write nearly instantly. I'm using this code:my_dataframe.write.format("jdbc")
.option("url",sqlsUrl)
.optio...
Hi all, I've a dataframe with CreateDate column with this format:CreateDate/Date(1593786688000+0200)//Date(1446032157000+0100)//Date(1533904635000+0200)//Date(1447839805000+0100)//Date(1589451249000+0200)/and I want to convert that format to date/tim...
Hi @Bruno Franco ,Can you please try the below code, hope it might for you.from pyspark.sql.functions import from_unixtime
from pyspark.sql import functions as F
final_df = df_src.withColumn("Final_Timestamp", from_unixtime((F.regexp_extract(col("Cr...
Hi @Hui Hui Wong (Customer), We haven’t heard from you since the last response from @Daniel Sahal (Customer) , and I was checking back to see if his suggestions helped you.Or else, If you have any solution, please share it with the community, as...
I am looking for similar requirements to explore various options to encrypt/decrypt the ADLS data using ADB pyspark. Please share list of options available.
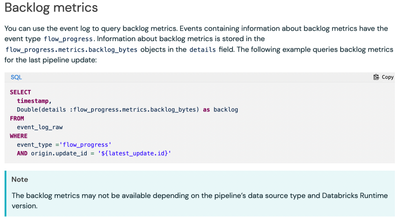
I am trying to use the event log to collect metrics on the 'flow_progess' under the 'event_type' field. In the the docs it suggests that this information may not be collected based on the data source and runtime used (see screenshot). Can anyone let ...
Thanks for contacting Databricks Support! I understand that you're looking for information on unsupported data source types and runtimes for the backlog metrics. Unfortunately, we currently have not documented that information. It's possible that som...
We are using jobs/runs/submit API of databricks to create and trigger a one-time run with new_cluster and existing_cluster configuration. We would like to check if there is provision to pass "job_clusters" in this API to reuse the same cluster across...