The Databricks Certified Data Engineer Professional exam most questions are too long for those English as second language. Not enough time to read through the questions and sometimes hard to comprehend
I strongly agree with you. There is not a Spanish version of this exam. Those exam are long even for native speakers just imagine for people with English as a second language. For instance, since Amazon does not have a Spanish version, they took this...
I have a dataframe that inexplicably takes forever to write to an MS SQL Server even though other dataframes, even much larger ones, write nearly instantly. I'm using this code:my_dataframe.write.format("jdbc")
.option("url",sqlsUrl)
.optio...
Hi all, I've a dataframe with CreateDate column with this format:CreateDate/Date(1593786688000+0200)//Date(1446032157000+0100)//Date(1533904635000+0200)//Date(1447839805000+0100)//Date(1589451249000+0200)/and I want to convert that format to date/tim...
Hi @Bruno Franco ,Can you please try the below code, hope it might for you.from pyspark.sql.functions import from_unixtime
from pyspark.sql import functions as F
final_df = df_src.withColumn("Final_Timestamp", from_unixtime((F.regexp_extract(col("Cr...
Hi @Hui Hui Wong (Customer), We haven’t heard from you since the last response from @Daniel Sahal (Customer) , and I was checking back to see if his suggestions helped you.Or else, If you have any solution, please share it with the community, as...
I am looking for similar requirements to explore various options to encrypt/decrypt the ADLS data using ADB pyspark. Please share list of options available.
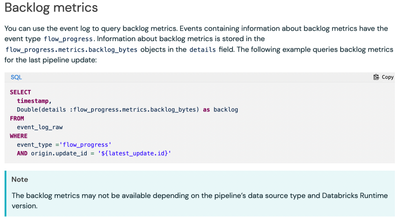
I am trying to use the event log to collect metrics on the 'flow_progess' under the 'event_type' field. In the the docs it suggests that this information may not be collected based on the data source and runtime used (see screenshot). Can anyone let ...
Thanks for contacting Databricks Support! I understand that you're looking for information on unsupported data source types and runtimes for the backlog metrics. Unfortunately, we currently have not documented that information. It's possible that som...
We are using jobs/runs/submit API of databricks to create and trigger a one-time run with new_cluster and existing_cluster configuration. We would like to check if there is provision to pass "job_clusters" in this API to reuse the same cluster across...
I am working on Google Cloud and want to create Databricks workspace with custom VPC using terraform. Is that supported ? If yes is it similar to AWS way ?Thank youHoratiu
Hi @horatiu guja GCP Workspace provisioning using Terraform is public preview now. Please refer to the below doc for the steps.https://registry.terraform.io/providers/databricks/databricks/latest/docs/guides/gcp-workspace
Hi!I saved a dataframe as a delta table with the following syntax:(test_df
.write
.format("delta")
.mode("overwrite")
.save(output_path)
)How can I issue a SELECT statement on the table?What do I need to insert into [table_name] below?SELECT ...
Hi @John B there is two way to access your delta table-SELECT * FROM delta.`your_delta_table_path`df.write.format("delta").mode("overwrite").option("path", "your_path").saveAsTable("table_name")Now you can use your select query-SELECT * FROM [table_...
Hello there @G Z I would say "we have a history of open sourcing our biggest innovations but there's no concrete timeline for dlt. It's built on the open APIs of spark and delta, so the most important parts (your transformation logic and you data) ...
Hi - I have created a Databricks job - under Workflow - its running fine without any issues . I would like to promote this job to other workspaces using a script.Is there a way to script the job definition and deploy it across multiple workspaces .I ...
We are trying to connect Azure Databricks Cluster to Azure SQL database but the firewalls at SQL level is causing an issue.Whitelisting dbks subnet is not an option here as both the resources are in two different azure regions. Is there a secure way ...
Hi @Timir Ranjan,Have you tried looking into private endpoints? This allows you to expose your Azure SQL database from the Azure backbone and is cross-regional supported.https://learn.microsoft.com/en-us/azure/private-link/private-endpoint-overviewP...
I'm new to databricks. (Not new to DB's - 10+ year DB Developer).How do you generate a MERGE statement in DataBricks? Trying to manually maintain a 500+ or 1000+ lines in a MERGE statement doesn't make much sense? Working with Large Tables of between...
In my opinion, when possible MERGE statement should be on the primary key. If not possible you can create your own unique key (by concatenate some fields and eventually hashing them) and then use it in merge logic.