- 2164 Views
- 9 replies
- 12 kudos
- 2164 Views
- 9 replies
- 12 kudos
Latest Reply
- 12 kudos
Good job, congratulations on all of your achievements.
- 12 kudos
Good job, congratulations on all of your achievements.
https://www.databricks.com/notebooks/recitibikenycdraft/data-preparation.htmlCould someone help to see in that Step 3: Prepare Calendar Info# derive complete list of dates between first and last datesdates = ( spark .range(0,days_between).withCol...
Hi @THIAM HUAT TAN In your notebook, you are creating a integer column days_between with the codedays_between = (last_date - first_date).days + 10Logically speaking, what the nb trying to do is to fetch all the dates between two dates to do a foreca...
I just noticed i can only run limited number of SQL queries. Is that the default or norm?
Hi there, you can only run 10 concurrent SQL queries per cluster.
I tried contact details on the bottom, but they seem to be generic Databricks contact and support links. The issue I faced was this:I think this word made its way to the stop list by a mistake.

Hey @Vladimir Ryabtsev and @Hubert Dudek,Thank you for highlighting this. Seems they were added to the block list in combination with other words.We will have this fixed as soon as possible.It's always great to have help from our community members....
If i have two stages bronze and silver and when i create delta live tables we need to give the target schema to store the results , but i need to store tables in two databases bronze AND silver , for this i need to create two different delta live tab...
Hi @Rishabh Pandey , yes you have to create 2 DLT tables
Below is the integrity check error we are getting when trying to set the deletedRetentionFileDuration table property to 10 days. Observation: The table data is sitting in S3. The size of all the files in S3 is in TB. There are millions of files for t...


Please backup your table, then run the repair of filesFSCK REPAIR TABLE table_nameyou can also try to make dry run firstFSCK REPAIR TABLE table_name DRY RUNif data is partitioned can be helpful to refresh metastoreMSCK REPAIR TABLE mytable
Hi Team,I have a requirement in workflow job. Job has two tasks, one is python-task and another one is scala-task (both are running their own cluster).I have defined dbutils.job.taskValue in python which is not able to read value in scala because o...
Hi @Sreekanth Nallapa please refer this link This might help you in this
Hi,I am currently experimenting with databricks-jdbc : 2.6.29 and trying to execute batch insert queries What is the optimal batch size recommended by Databricks for performing Batch Insert queries?Currently it seems that values are inserted row by r...
Just an observation : By using auto optimize table level property, I was able to see batch inserts inserting records in single file.https://docs.databricks.com/optimizations/auto-optimize.html
Hello Friends,We have an application which extracts dat from various tables in Azure Databricks and we extract it to postgres tables (postgres installed on top of Azure VMs). After extraction we apply transformation on those datasets in postgres tabl...
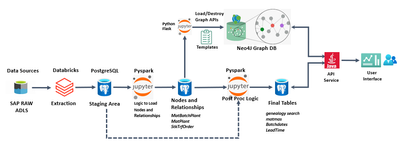
You can leverage Airflow, which provides a connector for databricks jobs API, or can use databricks workflow to orchestrate your jobs where you can define several tasks and set dependencies accordingly.
Hello,I have an issue with the import of a custom library, in Azure Databricks.(roughly) 95% of the times it works fine, but sometimes it fails.I searched the internet and this community with no luck, so far.It is a scala library in a scala notebook,...
Even I also encountered the same error. While Importing a file getting an error as "Import failed with error: Could not deserialize: Exceeded 16777216 bytes (current = 16778609)"
I configured ADLS Gen2 standard storage and successfully configured Autoloader with the file notification mode.In this documenthttps://docs.databricks.com/ingestion/auto-loader/file-notification-mode.html"ADLS Gen2 provides different event notificati...
Hi, @Chris Konsur. You do not need anything with the FlushWithClose event REST API that is just the event type that we listen to. As for backfill setting, this is for handling late data or late event that are being triggered. This setting largely de...
I am trying to compute outliers using approxQuantile on a Dataframe. It works fine in a Databricks notebook, but the call doesn't work correctly when it is part of a delta live table pipeline. (This is python.) Here is the line that isn't working a...
Good recommendation. I was able to do something similar that appears to work.# Step 2. Compute the is outlier sessions based on duration_minutes lc = session_agg_df.selectExpr("percentile(duration_minutes, 0.25) lower_quartile") session_agg_d...
DEC 13 MEETUP: Arbitrary Stateful Stream Processing in PySparkFor folks in the Bay Area- Dr. Karthik Ramasamy, Databricks' Head of Streaming, will be joined by engineering experts on the streaming and PySpark teams at Databricks for this in-person me...
HI Team,I have gone through Lot of articles, but it looks there is some gap on pricing. can anyone please let me know accurate way to calculate DBU Pricing into dollarsas per my understandingTotal DBU Cost: DBU /hour * total job ran in hours (Shows a...
DBU is per VM, and every VM has a different DBU price
How do I add a column to an existing delta table with SQL if the column does not already exist?I am using the following code: <%sqlALTER TABLE table_name ADD COLUMN IF NOT EXISTS column_name type; >but it prints the error: <[PARSE_SYNTAX_ERROR] Synta...
Hi @Christine Pedersen I guess IF NOT EXISTS or IF EXISTS can be used in conjunction with DROP or PARTITIONS according to the documentation. If you want to do this the same checking way, you can do using a try catch block in pyspark or as per your l...
| User | Count |
|---|---|
| 1601 | |
| 736 | |
| 343 | |
| 284 | |
| 246 |