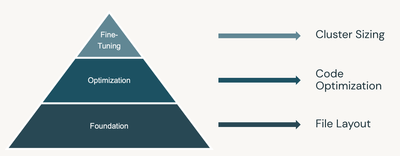
Recommendations for performance tuning best practices on DatabricksWe recommend also checking out this article from my colleague @Franco Patano on best practices for performance tuning on Databricks.Performance tuning your workloads is an important...
Hi,We have a databricks deployment in our AWS account in a dedicated VPC which we created a VPC peering to our EKS VPC, in the EKS main security group we added a rule that opens all TCP ports from the Databricks VPC and now it's working. Once I try t...
Hi, I have Azure Hbase cluster and Databricks. I want to run jobs on Databricks that write data to Hbase. To connect to Hbase I need to get Hbase-site.xml and have it in the classpath or env of a job.Question: How can I run the Databricks job with an...
We are trying to configure a job cluster for a workflow. It looks as though we no longer have the option in the Access mode drop down for 'Custom'. We need custom as we have additional Spark configuration key/value settings we apply. The UI throws an...
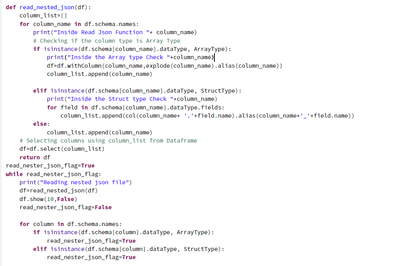
I have a total of 5000 files (Nested JSON ~ 3.5 GB). I have written a code which converts the json to Table in minutes (for JSON size till 1 GB) but when I am trying to process 3.5GB GZ json it is mostly getting failed because of Garbage collection. ...
Hey @Rahul Kumar Hope everything is going great.Just checking in. Does @Kaniz Fatma's response answer your question? If yes, would you be happy to mark it as best so that other members can find the solution more quickly? Else please let us know if ...
As many of you, we have implemented a "medallion architecture" (raw/bronze/silver/gold layers), which are each stored on seperate storrage accounts. We only create proper hive tables of the gold layer tables, so our powerbi users connecting to the da...
I can answer the first question:You can define data storage by setting the `path` parameter for tables. The "storage path" in pipeline settings will then only hold checkpoints (and some other pipeline stuff) and data will be stored in the correct acc...
Hi All,I am unable to execute "Classroom-Setup-06.1" & "Classroom-Setup-06.2" setups in DataEngineering Course. On checking, I found that "DA = DBAcademyHelper()" statement is not executing in the include section of the code.I am using the community ...
Hostinc is the best place to match the price and quality of the product at the most affordable price. If you are looking for a server that can make your marketing campaign a huge success here you go with our one of the most powerful Dedicated Server ...
I need to delete from a temp view in databricks, but it looks like i can do only merge, select and insert. Maybe i missed something but I did not find any documentation on this.
I have this delta lake in ADLS to sink data through spark structured streaming. We usually append new data from our data source to our delta lake, but there are some cases when we find errors in the data that we need to reprocess everything. So what ...
Hi @Manish P , You have three options for converting a Parquet table to a Delta table.Convert files to Delta Lake format and then create a Delta table:CONVERT TO DELTA parquet.`/data-pipeline/`
CREATE TABLE events USING DELTA LOCATION '/data-pipelin...
Hi,I have a Delta Live Tables pipeline, using Auto Loader, to ingest from JSON files. I need to do some transformations - in this case, converting timestamps. Except one of the timestamp columns does not exist in every file. This is causing the DLT p...
I want to run aggregations on large windows (90 days) with small slide duration (5 minutes).Straightforward solution leads to giant state around hundreds of gigabytes, which doesn't look acceptable.Is there any best practices doing this?Now I conside...
Hi @Sergey Volkov, Thanks for your question. Here are some fantastic articles on EWMA and Event-time Aggregation in Apache Spark™’s Structured Streaming. Please have a look. Let us know if that helps.https://towardsdatascience.com/time-series-from-s...
HI,Is there any way to disable launch workspace option in Azure portal for ADB.We have user accesses at resource group, so we need to restrict users who are part of owner or contributor role to launch ADB worksapce as admin.Thank you
Deny Assignments don't block subscription contributor to launch workspace and become admin. Actually I haven't find any way to block that after many tries of different methods.