I've created a new job with the new UI / feature enabled.
I managed to create one task with a new job cluster successfully but when adding a second task with a new job cluster and trying to save it I received the following error:
Error updating [Job...
Hi, I have a similar issue.I'm using the 14 day free trial, setting up the default basic-starter cluster.Then I just followed the basic introduction of dbx with python. https://docs.databricks.com/dev-tools/dbx.htmlCommand Execute is working, but whe...
Hi there,I'm taking a class in Databricks academy on DataBricks SQL and my company dashboard and community dashboard both are missing the SQL dropdown option. How can those taking classes in the academy actually use the tools we are learning about if...
I want to update one widget based on another widget. It gets updated but the dropdown shows the last selected in the dashboard view, but if I go to the notebook view from the dashboard view it updates. Any help? is it a bug?
It will be attached to the same cluster, and both will see live the same situation (so it will be, in fact, not run two times but one shared)You can use Repos and branches so everyone will get their branch and own notebook.
Hi,AllWhen I check cloud resources, the VPC status is BROKEN.However, the cluster is runnning without any problems.What is the BROKEN state?And how can I get it healthy?Regards.
Hey all, We're trying to analyze the data in a 23 GB JSON file. We're using the basic starter cluster - one node, 2 cpu x 8GB.We can read the JSON file into a spark dataframe and print out the schema but if we try and do any operations that won't c...
Hi there.I can get Databricks cost(dbus) from usage_log. But, how do I get AWS cost information?I want to show Databricks and AWS cost in my Databricks SQL Dashborad.
How do I configure plot options through the `display` function as code (not through the interactive UI)? Specifically asking since when a notebook is scheduled to run in a databricks job there is no way of configuring the plot type.
I want to create a personal access token for a service principal so that I can use that service principal personal access token in the databricks-connect configure command in an automated build. I followed the instructions from here.https://docs.data...
The context is not shared between Scala and Python so you won't be able to access the same variables directly. However you can use createOrReplaceTempView to create a temporary view of your dataframe and read it in the other language with read_df = s...
I need to create a dataset that is dependent on multiple streaming datasets. However, when I attempt to create the new single stream I am getting an error. Append output mode not supported when there are streaming aggregations on streaming DataFrame...
Hi Kaniz/Jose, I was able to resolve the issue. I used 'union all' to avoid aggregation on the stream and have it continue to write to the table in append mode.This issue can be closed.
I need to update most of the settings that are visible on the Admin Console UI by using Terraform. In another post in this forum I saw that I can use `custom_config` in a `databricks_workspace_conf` resource to achieve that but the options seem limit...
In my current company, we have a Hadoop cluster in which we extensively use conda environments and conda-packs. What are the requirements for Databricks to work with this setup?
Hi @Hugo Ferreira, Databricks Runtime with Conda was a Databricks runtime based on Conda environments instead of Python virtual environments, available only in Beta. If you want to use Conda to manage Python libraries and environments, use a support...
unable to create delta tables in aws glue catalogThe project requires that we integrate with the AWS Glue catalog.We would like to be able to create tables in delta format in the glue catalog.To test this functionality. We did the followingCreated th...
Hi @extCheeren.John, We haven't heard from you since my last response, and I was checking back to see if my suggestions helped you. Or else, If you have any solution, please share it with the community as it can be helpful to others. Also, please do...
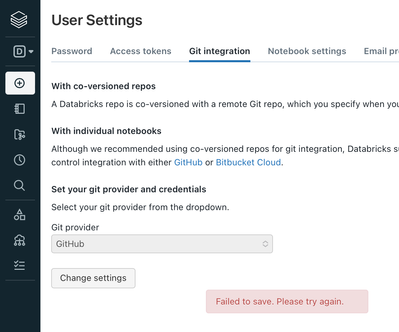
When I attempt to save my username and token for Github I receive a “Failed to Save. Try again.” message. I’ve used Azure DevOps with another DB workspace and never had an issue saving my PAT. I’ve tried using both my GitHub username and email wi...
Quick update that I’ve now attempted to save my PAT for Github using two different computers and browser types (Safari and Chrome) and all have given the same “Failed to save. Please try again” message. Thankfully I can still clone from public repo...