- 4050 Views
- 1 replies
- 0 kudos
Hi everyone,I have a concern that is there any way to read stream from 2 different kafka topics with 2 different in 1 jobs or same cluster? or we need to create 2 separate jobs for it ? (Job will need to process continually)
- 4050 Views
- 1 replies
- 0 kudos
- 1708 Views
- 0 replies
- 0 kudos
I have a merge function for streaming foreachBatch kind ofmergedf(df,i): merge_func_1(df,i) merge_func_2(df,i)Then I want to add new merge_func_3 into it. Is there any best practices for this case? when streaming always runs, how can I process...
- 1708 Views
- 0 replies
- 0 kudos
- 16531 Views
- 1 replies
- 1 kudos
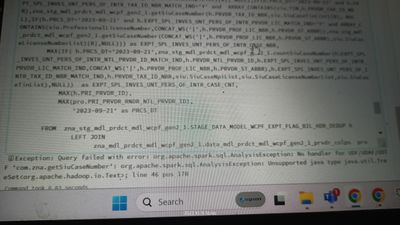
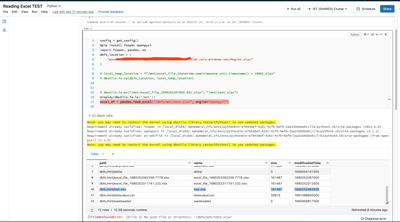
It's more a spark question then a databricks question, I'm encountering an issue when writing data to an Oracle database using Apache Spark. My workflow involves removing duplicate rows from a DataFrame and then writing the deduplicated DataFrame to ...
- 16531 Views
- 1 replies
- 1 kudos
Latest Reply
The difference in behaviour between using foreachPartition and data.write.jdbc(...) after dropDuplicates() could be due to how Spark handles data partitioning and operations on partitions. When you use foreachPartition, you are manually handling the ...