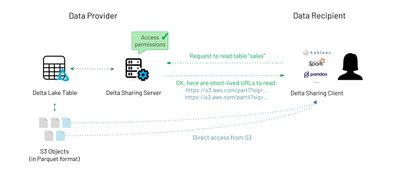
How does Delta Sharing work?Delta Sharing is a simple REST protocol that securely shares access to part of a cloud dataset. It leverages modern cloud storage systems, such as S3, ADLS or GCS, to reliably transfer large datasets. There are two parties...
Generally it is limited by cloud provider, initially yo get around 350 cores that can be increased by request to cloud vendor, Till now I have seen 1000 cores and it can go much moreIn addition to subscription limits, the total capacity of cluster...
Shallow clone: only duplicates the metadata of the table being cloned; the data files of the table itself are not copied. These clones are cheaper to create but are not self-contained and depend on the source from which they were cloned as the sourc...
Since a shallow clone only copies the metadata of the original table, I'm wondering where new data would end up. Is it even possible to add data to a shallow clone? Is the data written back to the original source file location?
Shallow Clones are really useful for short-lived use cases such as testing and experimentation . It duplicates the metadata from the source table - and any new data added would go to the location specified while creating the shallow table. >Is the da...
On the Data tab in the workspace I have the "Create Table" button which gives me the option to upload a local file as a data source. Can I upload an Excel file here? Not sure what kind of files work for this.
Currently the file types supported there are CSV, JSON and Avro. You could, however upload the excel file to the dbfs path under FileStore and write code in a notebook to parse it and persist it to a table
The clone is not a replica and so updates made to the original delta table wouldn't be applies to the clone. However, shallow clones reference data files in the source directory. If you run vacuum on the source table, clients will no longer be able t...
I know the skew in my dataset has the potential to cause issues with my job performance, so just wondering if there is anything I can do to help my performance other than repartitioning the whole dataset.
For scenarios like this, it is recommend to use a cluster with Databricks Runtime 7.3 LTS or above where AQE is enabled. AQE dynamically handles skew in sort merge join and shuffle hash join by splitting (and replicating if needed) skewed tasks into ...
From what I have read about AQE it seems to do a lot of what skew join hints did automatically. So should I still be using skew hints in my queries? Is there harm in using them?
With AQE Databricks has the most up-to-date accurate statistics at the end of a query stage and can opt for a better physical strategy and or do optimizations that used to require hints,In the case of skew join hints, is recommended to rely on AQE...
In addition to subscription limits, the total capacity of clusters in each workspace is a function of the masks used for the workspace's enclosing Vnet and the pair of subnets associated with each cluster in the workspace. The masks can be changed if...
Wondering if there any dangers to doing this, and if it's a best practice. I'm concerned there could be conflicts but I'm not sure how Delta would handle it.
>Can multiple streams write to a Delta table at the same time?Yes delta uses optimistic concurrency control and configurable isolation levels>I'm concerned there could be conflicts but I'm not sure how Delta would handle it.Write operations can resul...
OPTIMIZE as you alluded has two operations , Bin-packing and multi-dimensional clustering ( zorder)Bin-packing optimization is idempotent, meaning that if it is run twice on the same dataset, the second run has no effectZ-Ordering is not idempotent b...
The biggest advantage is the ease with which you can star ingesting data from your Cloud Storage directly into a Delta Table. You can choose Directory Listing mode or File Notification mode, depending on what fits your use case best.
Most possibly in future as we progress down our Roadmap.Currently it is per-workspace, and only accessible in Databricks notebooks/jobs.Please refer to our docs:https://docs.databricks.com/applications/machine-learning/feature-store.html#known-limita...