Hi, Is there any connectivity pipeline established already to access MuleSoft or AnyPoint exchange data using Databricks. I have seen many options to access databricks data in mulesoft but can we read the data from Mulesoft into databricks. Please gi...
Hi @sasi2, Connecting MuleSoft or AnyPoint to exchange data with Databricks is possible, and there are several options you can explore.
Let’s dive into some solutions:
Using JDBC Driver for Databricks in Mule Applications:
The CData JDBC Driver...
Hello, we have Databricks Python workbooks accessing Delta tables. These workbooks are scheduled/invoked by Azure Data Factory. How can I enable Photon on the linked services that are used to call Databricks?If I specify new job cluster, there does n...
When you create a cluster on Databricks, you can enable Photon by selecting the "Photon" option in the cluster configuration settings. This is typically done when creating a new cluster, and you would find the option in the advanced cluster configura...
There are some tables under schema/database under Unity Catalog.The Notebook need to read the table parallel using loop and thread and execute the query configuredBut the sql statement is not getting executed via spark.sql() or spark.read.table().It ...
Hi @subha2, It seems you’re encountering an issue related to executing SQL statements in Spark.
Let’s troubleshoot this step by step:
Check the Unity Catalog Configuration:
Verify that the Unity Catalog configuration is correctly set up. Ensure t...
I have Data Engineering Pipeline workload that run on Databricks.Job cluster has following configuration :- Worker i3.4xlarge with 122 GB memory and 16 coresDriver i3.4xlarge with 122 GB memory and 16 cores ,Min Worker -4 and Max Worker 8 We noticed...
Hi @DBX-2024,
Let’s break down your questions:
High CPU Utilization Spikes: Are They Problematic?
High CPU utilization spikes can be problematic depending on the context. Here are some considerations:
Normal Behavior: It’s common for CPU utilizat...
The chunk of code in questionsys.path.append(
spark.conf.get("util_path", "/Workspace/Repos/Production/loch-ness/utils/")
)
from broker_utils import extract_day_with_suffix, proper_case_address_udf, proper_case_last_name_first_udf, proper_case_ud...
Hi @gabe123 , It seems like you’re encountering a ModuleNotFoundError when trying to import the broker_utils module in your Python code.
Let’s troubleshoot this issue step by step:
Check Module Location:
First, ensure that the broker_utils.py fil...
Hello,I am working on a Spark job where I'm reading several tables from PostgreSQL into DataFrames as follows: df = (spark.read
.format("postgresql")
.option("query", query)
.option("host", database_host)
.option("port...
Hi @lieber_augustin, Optimizing the performance of your PostgreSQL queries involves several considerations.
Let’s address both the potential optimizations and the reason behind multiple Scan JDBCRelation operations.
Database Design:
Properly des...
Hello,We are currently utilizing an autoloader with file listing mode for a stream, which is experiencing significant latency due to the non-incremental naming of files in the directory—a condition that cannot be altered.In an effort to mitigate this...
Hi @Ulman ,i think that by default this method will try to create Event Grid and Storage Queue on the same Storage Account as your data.Please not that PREMIUM Blob Storage do not have QUEUE service.In my opinion the easiest way would be to create ma...
Good morning, I'm trying to run: databricks bundle run --debug -t dev integration_tests_job My bundle looks: bundle:
name: x
include:
- ./resources/*.yml
targets:
dev:
mode: development
default: true
workspace:
host: x
r...
Hi @jorperort,
The error message you’re seeing, “no deployment state. Did you forget to run ‘databricks bundle deploy’?”, indicates that the deployment state is missing.
Here are some steps you can take to resolve this issue:
Verify Deploym...
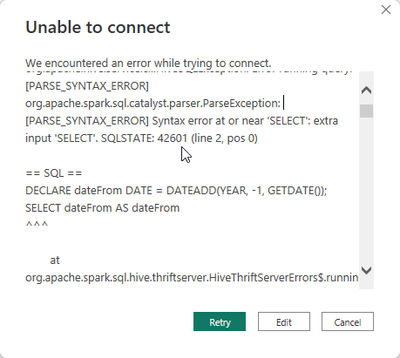
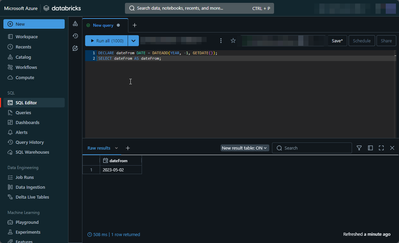
Hello everyone,I'm trying to use the ODBC DirectQuery option in PowerBI, but I keep getting an error about another command. The SQL query works while using the SQL Editor. Do I need to change the setup of my ODBC connector?DECLARE dateFrom DATE = DA...
Hi @mamiya , Here are a few steps you can take to address the error:
Check Power Query Editor Steps:
The error might be related to a specific step in the Power Query Editor. Try opening the Power Query Editor and reviewing the steps. If there’s a...
I have setup my Databricks notebook to use Service Principal to access ADLS using below configuration.service_credential = dbutils.secrets.get(scope="<scope>",key="<service-credential-key>")
spark.conf.set("fs.azure.account.auth.type.<storage-accou...
Below is the implementation of same code in scala:spark.sparkContext.hadoopConfiguration.set("fs.azure.account.key.<accountName>.dfs.core.windows.net",<accountKey>)
Hi @prats33 You can use databricks cluster API for terminate your cluster at any specific time, create notebook for API and schedule it as databricks workflow job on job cluster at 11:59.
Hi,We would like to use Azure Managed Identity to create mount point to read/write data from/to ADLS Gen2?We are also using following code snippet to use MSI authentication to read data from ADLS Gen2 but it is giving error,storage_account_name = "<<...
Hi all,I'm in the progress of migrating from Databricks Azure to Databricks AWS.One part of this is migrating all our workflows which I wanted to via the /api/2.1/jobs/create api with the workflow passed via the json body. I have successfully created...
Hello, many thanks for your question, as per the error message showed it was mentioning a possible timeout or network issue. As first step have you tried to open the page on another browser or using incognito mode?Also have you tried using different ...
I have done the below steps1. Created a databricks managed service principal2. Created a Oauth Secret3. Gave all necessary permissions to the service principalI'm trying to use this Service principal in Azure Devops to automate CI/CD. but it fails as...
Have you follow the steps available for service principal for CI/CD available here: https://learn.microsoft.com/en-us/azure/databricks/dev-tools/ci-cd/ci-cd-sp