Job is scheduled on interactive cluster, and it failed with below error and in the next scheduled run it ran fine. I want to why this error occurred and how can I prevent from occurring this again.How to debug these types of error? com.databricks.b...
@JKR Could you try setting the configurations below at the cluster level and retry the job?spark.databricks.python.defaultPythonRepl pythonshellspark.databricks.pyspark.py4j.pinnedThread false
Is there a way to mount Workspace folder (WSFS) to the Docker container if I'm using the Databricks Container Services ofr running a general purpose cluster?If I create a cluster without a Docker image, the `!ls` command in Databricks notebook return...
Hello:Thanks for contacting Databricks Support!
I'm afraid that mounting the WSFS directly into a Docker container isn't directly supported. The Databricks workspace is a specialized environment and isn't directly analogous to a regular filesystem.
W...
Hi allHaving some fun trying to run a notebook on a shared UC-aware, shared cluster - I keep on running into this error:py4j.security.Py4JSecurityException: Method public static org.apache.spark.sql.SparkSession org.apache.sedona.spark.SedonaContext....
Hi @abhaigh , Certainly! It seems you’re encountering a security issue related to the Py4J framework when running your notebook on a shared cluster.
Let’s address this and explore potential solutions:
Py4J Security Exception:
The error message y...
Started getting this error while running all the scripts. All the scripts were running fine before. I tried de-attaching and also restart nothing seems to work.Internal error. Attach your notebook to a different cluster or restart the current cluste...
Hi @210573 (Customer) ,I got the same error, tried to restart and create a new cluster but the solution does not work. What I did to fix the issue: Instead of putting in function, break the code out to run line by line. I just want to see where the ...
Hello all, I am following the Databrick's documentation on unit testing found here: Run tests with pytest for the Databricks extension for Visual Studio Code - Azure Databricks | Microsoft LearnHowever, when taking it a step further I get an ImportEr...
HelloImport errors happen often with Pytest. To Debug this error you can add this in your "test_myfunction_test.py":import sys
# printing all directories for
# interpreter to search
sys.pathsys.path is a built-in variable within the sys module. I...
Is there a way to make databricks-connector wait for cluster to be running?Details:databricks-connector==13.1.0 and the python minor version of cluster and environment are both 3.10If the cluster is not running this will start it, but any commands af...
Hi @AFox , I want to express my gratitude for your effort in selecting the most suitable solution. It's great to hear that your query has been successfully resolved. Thank you for your contribution.
We have 3 workspaces - 1 old version in one AWS account, 2 latest versions in another.We are PAYG full edition, not using SSO.Our admins (existing DBX users in the `admins` group) can invite new users via the Admin Console from the 1 old and 1 new wo...
We are facing same issue, We are on azure. @AndyAtINX you mean if user exist in workspace with abc@gmail.com we should add the user in workspace2 with abc@gmail.com not ABC@GMAIL.COM. if this the case we tried this and its not working for us.
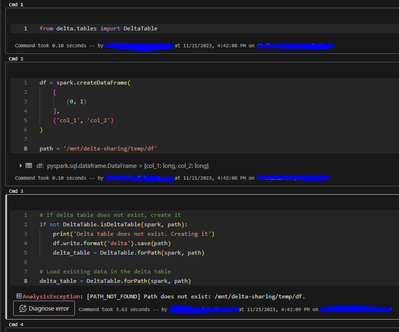
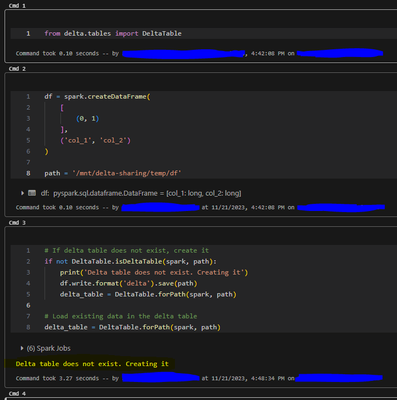
I am performing some tests with delta tables. For each test, I write a delta table to Azure Blob Storage. Then I manually delete the delta table. After deleting the table and running my code again, I get this error: AnalysisException: [PATH_NOT_FOUN...
Good afternoon,I'm currently going through Module 4 of the Data Engineering Associate pathway, specifically lesson 4.1 - DLT UI Walkthrough. We are instructed to specify the Cluster Policy as 'DBAcademy DLT' when configuring the pipeline. However, th...
I am trying to learn more about Vacuum operation and came across the two properties: delta.deletedFileRetentionDurationdelta.logRetentionDurationSo, let's say I have a delta table where few records/files have been deleted. The delta.deletedFileRetent...
I'm trying this code but getting the following error testDF = (eventsDF
.groupBy("user_id")
.pivot("event_name")
.count("event_name")) TypeError: _api() takes 1 positional argument but 2 were givenPlease guide how to fix...
If anyone has example code for building a CDC live streaming pipeline generated by AWS DMS using import dlt, I'd love to see it.I'm currently able to see the parquet file starting with Load on the first full load to S3 and the cdc parquet file after ...
Hi @rt-slowth ,
Certainly! Let’s explore how to create a Change Data Capture (CDC) live streaming pipeline using Delta Live Tables and AWS Database Migration Service (DMS).
Delta Live Tables and AWS DMS:
Delta Live Tables is an open-source storage ...
Hello, I am trying to generate a DLT but need to use a UDF Table Function in the process. This is what I have so far, everything works (without e CREATE OR REFRESH LIVE TABLE wrapper)```sqlCREATE OR REPLACE FUNCTION silver.portal.get_workflows_from_...
Hi @alexiswl , I want to express my gratitude for your effort in selecting the most suitable solution. It's great to hear that your query has been successfully resolved. Thank you for your contribution.