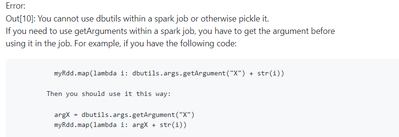
I'm trying to reuse a Python Package to do a very complex series of parsing binary files into workable data in Delta Format. I have made the first part (binary file parsing) work with a UDF:asffileparser = F.udf(File()._parseBytes,AsfFileDelta.getSch...
PrivilegesSELECT: gives read access to an object.CREATE: gives ability to create an object (for example, a table in a schema).MODIFY: gives ability to add, delete, and modify data to or from an object.USAGE: does not give any abilities, but is an add...
Scenario: I Have a dataframe with more than 1000 rows, each row having a file path and result data column. I need to loop through each row and write files to the file path, with data from the result column.what is the easiest and time effective way ...
Hi,I agree with Werners, try to avoid loop with Pyspark Dataframe.If your dataframe is small, as you said, only about 1000 rows, you may consider to use Pandas.Thanks.
I have a quick question about %run <notebook path>. I am using the %run command to import functions from a notebook. It works fine when I run %run once. But when I run two %run commands, I lose the reference from the first %run. I get NameError when ...
I have created a UDF using:%sqlCREATE OR REPLACE FUNCTION f_timestamp_max()....And I've confirmed it works with:%sqlselect f_timestamp_max()But when I try to use it in a Window function (lead over partition), I get:AnalysisException: Using SQL functi...
Afternoon everyone! I logged in hoping to see some suggestions but think maybe I need to reword the question a little How can I create a UDF that converts '30000101' to timestamp and then use it in a query like below?%sqlselectfield1,field2,nvl(some...
Hi there, I am trying to build a delta live tables pipeline that ingests gzip compressed archives as they're uploaded to S3. The archives contain 2 files in a proprietary format, and one is needed to determine how to parse the other. Once the file co...
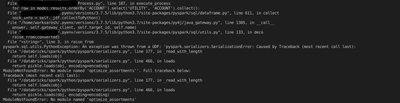
I have a job running with no issues in Databricks runtime 7.3 LTS. When I upgraded to 8.3 it fails with error An exception was thrown from a UDF: 'pyspark.serializers.SerializationError'... SparkContext should only be created and accessed on the driv...
Adding to @Sean Owen comments, The only reason this is working is that the optimizer is evaluating this locally rather than creating a context on executors and evaluating it.
Thanks i modified my code as per your suggestion and it worked perfectly Thanks again for all your inputsdflist= spark.createDataFrame(list(a.columns), "string").toDF("Name")dfg=dflist.filter(col('name').isin('ref_date')).count()if dfg==1 : a = a.wi...
I am using databricks sql notebook to run these queries. I have a Python UDF like %python
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType, DoubleType, DateType
def get_sell_price(sale_prices):
return sale_...
I am running into the following error when I run a model fitting process over databricks-connect.It looks like worker nodes are unable to access modules from the project's parent directory. Note that the program runs successfully up to this point; n...
Hello,I am currently working on a time series forecasting with FBProphet. Since I have data with many time series groups (~3000) I use a @pandas_udf to parallelize the training. @pandas_udf(schema, PandasUDFType.GROUPED_MAP)
def forecast_netprofit(pr...
Thank you for the answers. Unfortunately this did not solve the performance issue.What I did now is I saved the results into a table:results.write.mode("overwrite").saveAsTable("db.results") This is probably not the best solution but after I do that ...
I have a delta table with about 300 billion rows. Now I am performing some operations on a column using UDF and creating another columnMy code is something like thisdef my_udf(data):
return pass
udf_func = udf(my_udf, StringType())
data...
That udf code will run on driver so better not use it for such a big dataset. What you need is vectorized pandas udf https://docs.databricks.com/spark/latest/spark-sql/udf-python-pandas.html
I have created custom UDF's that generate logs. These logs can be flushed by calling another API exposed which is exposed by an internal layer. However I want to call this API just after the execution of the UDF comes to an end. Is there any way of d...
@Krishna Kashiv May be ExecutorPlugin.java can help. It has all the methods you might required. Let me know if it works or not.You need to implement this interface org.apache.spark.api.plugin.SparkPluginand expose it as spark.plugins = com.abc.Imp...
def squared(s):
return s * s
spark.udf.register("squaredWithPython", squared)You can optionally set the return type of your UDF. The default return type is StringType.from pyspark.sql.types import LongType
def squared_typed(s):
return s * s
spark...