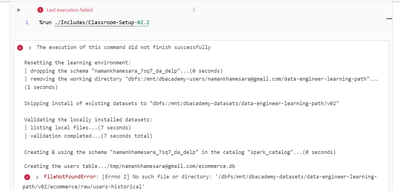
I can list out the file using dbutils but can not able to read files in databricks. PFB in screenshot. I can able to see the file using dbutils.fs.ls but when i try to read this file using read_excel then it is showing me an error like "FileNotFound...
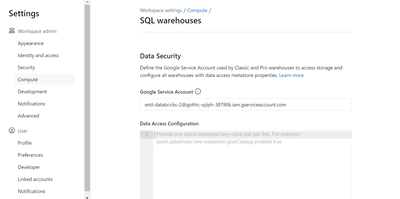
Hello there,I am trying to start a serverless databricks SQL cluster in GCP. I am following this databricks doc: https://docs.gcp.databricks.com/en/admin/sql/serverless.htmlI have checked that all my requirements are fulfilled for activating the clus...
I am using a tqdm progress bar to monitor the amount of data records I have collected via API. I am temporarily writing them to a file in the DBFS, then uploading to a Spark DataFrame. Each time I write to a file, I get a message like 'Wrote 8873925 ...
Hi @halox6000, To stop the progress bar output from tqdm, you can use the disable argument. Set it to True to silence any tqdm output. In fact, it will not only hide the display but also skip the progress bar calculations entirely1. Here’s an examp...
Hi,I have configured 20 different workflows in Databricks. All of them configured with job cluster with different name. All 20 workfldows scheduled to run at same time. But even configuring different job cluster in all of them they run sequentially w...
@jainshasha base on the screenshot you sent, looks like your jobs are starting at 12:30 and runs in parallel Why do you thin your jobs are waiting for clusters?
Hi Databricks Community,I am following https://customer-academy.databricks.com/learn/course/1266/data-engineering-with-databricks?generated_by=575333&hash=6edddab97f2f528922e2d38d8e4440cda4e5302a this course provided by databricks. In this when I am ...
Hi All, My job is breaking as the cluster is not able to autoscale. below is the log,can it be due to AWS vms are not spinning up or can be due to issue databricks configuration.Does anyone has faced it before ?TERMINATING Compute terminated. Reason:...
As of this morning we started receiving the following error message on a Databricks job with a single Pyspark Notebook task. The job has not had any code changes in 2 months. The cluster configuration has also not changed. The last successful run of ...
As advised, I double confirmed that no code or cluster configuration was changed (even got a second set of eyes on it that confirmed the same).I was able to find a "fix" which puts a bandaid on the issue:I was able to pinpoint that the issue seems to...
Hi Everyone,I am trying to implement parallel processing in databricks and all the resources online point to using ThreadPool from the pythons multiprocessing.pool library or concurrent future library. These libraries offer methods for creating async...
I am not super expert but I have been using databricks for a while and I can say that - when you use any Python library like asyncio, ThredPool and so one - this is good only to some maintenance things, small api calls etc.When you want to leverage s...
Hi y'all.I'm trying to export metrics and logs to AWS cloudwatch, but while following their tutorial to do so, I ended up facing this error when trying to initialize my cluster with an init script they provided.This is the part where the script fail...
@digui Did you figure out what to do? We're facing the same issue, the script works for the executors.I was thinking on adding an if that checks if there is log4j.properties and modify it only if it exists
Hello everyone,I have a workflow setup that updates a few Delta tables incrementally with autoloader three times a day. Additionally, I run a separate workflow that performs VACUUM and OPTIMIZE on these tables once a week.The issue I'm facing is that...
Hi @Menegat, It seems you’re encountering an issue with your Delta tables during incremental updates.
Let’s dive into this and explore potential solutions.
Delta Live Tables and Incremental Updates:
Delta Live Tables allow for incremental updates...
Hello,Some variations of this question have been asked before but there doesn't seem to be an answer for the following simple use case:I have the following file structure on a Databricks Asset Bundles project: src
--dir1
----file1.py
--dir2
----file2...
Hi @georgef, It appears that you’re encountering issues with importing modules within a Databricks Asset Bundles (DABs) project.
Let’s explore some potential solutions to address this problem.
Bundle Deployment and Import Paths:
When deploying a ...
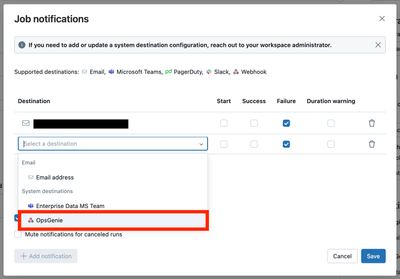
I'm trying to set up a Workflow Job Webhook notification to send an alert to OpsGenie REST API on job failure. We've set up Teams & Email successfully.We've created the Webhook and when I configure "On Failure" I can see it in the JSON/YAML view. How...
Hi @ChingizK, Configuring the payload for OpsGenie Webhook integration is essential to ensure that the data sent to OpsGenie meets your requirements.
Let’s walk through the steps:
Create a Webhook Integration in OpsGenie:
Go to Settings > Integra...
I have a terraform project that creates a workspace in Databricks, assigns it to an existing metastore, then creates external location/storage credential/catalog. The apply works and all expected resources are created. However, without touching any r...
Hi @lindsey, It seems you’re encountering an issue with Terraform and Databricks when trying to destroy resources. Let’s explore some potential solutions to address this problem:
Resource Order in Terraform Configuration:
Ensure that the databric...
I have tried multiples way to set row group for delta tables on data bricks notebook its not working where as I am able to set it properly using spark.I tried 1. val blockSize = 1024 * 1024 * 60spark.sparkContext.hadoopConfiguration.setInt( "dfs.bloc...
Hi @dlaxminaresh, Setting row groups for Delta tables in Databricks can be a bit tricky, but let’s explore some options to achieve this.
First, let’s address the approaches you’ve tried:
Setting Block Sizes:
You’ve attempted to set the block size...