Hi Team,Recently we had created new Databricks project/solution (based on Medallion architecture) having Bronze-Silver-Gold Layer based tables. So we have created Delta-Live-Table based pipeline for Bronze-Layer implementation. Source files are Parqu...
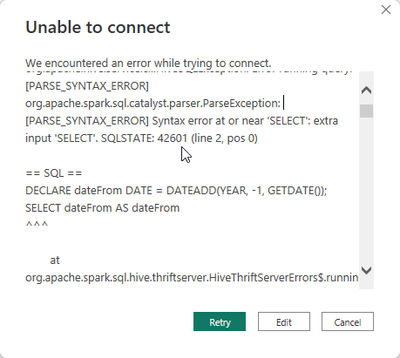
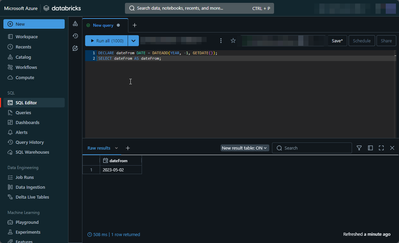
Hello everyone,I'm trying to use the ODBC DirectQuery option in PowerBI, but I keep getting an error about another command. The SQL query works while using the SQL Editor. Do I need to change the setup of my ODBC connector?DECLARE dateFrom DATE = DA...
May be I am new to Databricks that's why I have confusion.Suppose I have worker memory of 64gb in Databricks job max 12 nodes...and my job is failing due to Executor Lost due to 137 (OOM if found on internet).So, to fix this I need to increase execut...
Hi All,Please help me understand how the billing is calculated for using the Job cluster.Document says they are charged hourly basis, so if my job ran for 1hr 30mins then will be charged for the 30mins based on the hourly rate or it will be charged f...
I am having an issue where when I do a shallow clone using :create or replace table `catalog_a_test`.`schema_a`.`table_a` shallow clone `catalog_a`.`schema_a`.`table_a` I get:[TABLE_OR_VIEW_NOT_FOUND] The table or view catalog_a_test.schema_a.table_a...
Hi,I am migrating from dbx to databricks asset bundles. Previously with dbx I could work on different features in separate branches and launch jobs without issue of one job overwritting the other. Now with databricks asset bundles it seems like I can...
Any updates here?My team is migrating from dbx to DABs and we are running into the same issue. Ideally, we would like to deploy multiple, parametrized jobs from a single bundle. If this is not possible, we have to keep dbx.Thank you!
Good morning, I'm trying to run: databricks bundle run --debug -t dev integration_tests_job My bundle looks: bundle:
name: x
include:
- ./resources/*.yml
targets:
dev:
mode: development
default: true
workspace:
host: x
r...
Getting following error while saving a dataframe partitioned by two columns.Job aborted due to stage failure: Task 5774 in stage 33.0 failed 4 times, most recent failure: Lost task 5774.3 in stage 33.0 (TID 7736) (13.2.96.110 executor 7): ExecutorLos...
I am currently exploring testing methodologies for Databricks notebooks and would like to inquire whether it's possible to write pytest tests for notebooks that contain code not encapsulated within functions or classes.***********************a = 4b ...
Hi Team,Please provide guidance on enabling SQL cells parallel execution in a notebook containing multiple SQL cells. Currently, when we execute notebook and all the SQL cells they run sequentially. I would appreciate assistance on how to execute th...
I need help with migrating from dbfs on databricks to workspace. I am new to databricks and am struggling with what is on the links provided.My workspace.yml also has dbfs hard-coded. Included is a full deployment with great expectations.This was don...
There are multiple tables in the config/metadata table. These tables need to bevalidated for DQ rules.1.Natural Key / Business Key /Primary Key cannot be null orblank.2.Natural Key/Primary Key cannot be duplicate.3.Join columns missing values4.Busine...
Hi @subha2, To dynamically validate the data quality (DQ) rules for tables configured in a metadata-driven system using PySpark, you can follow these steps:
Define Metadata for Tables:
First, create a metadata configuration that describes the rules ...
Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answers your question?This...
from pyspark.sql import functions as F
from pyspark.sql import types as T
from pyspark.sql import DataFrame, Column
from pyspark.sql.types import Row
import dlt
S3_PATH = 's3://datalake-lab/XXXXX/'
S3_SCHEMA = 's3://datalake-lab/XXXXX/schemas/'
...
Hello,I am attempting to configure Autoloader in File Notification mode with Delta Live Tables. I configured an instance profile, but it is not working because I immediately get AWS access denied errors. This is the same issue that is referenced here...