I have Data Engineering Pipeline workload that run on Databricks.Job cluster has following configuration :- Worker i3.4xlarge with 122 GB memory and 16 coresDriver i3.4xlarge with 122 GB memory and 16 cores ,Min Worker -4 and Max Worker 8 We noticed...
Hi there,I am new to Spark SQL and would like to know if it possible to reproduce the below T-SQL query in Databricks. This is a sample query, but I want to determine if a query needs to be executed or not. DECLARE
@VariableA AS INT
, @Vari...
Since you are looking for a single value back, you can use the CASE function to achieve what you need.%sqlSET var.myvarA = (SELECT 6);SET var.myvarB = (SELECT 7);SELECT CASE WHEN ${var.myvarA} = ${var.myvarB} THEN 'Equal' ELSE 'Not equal' END AS resu...
Parameters can be passed to Tasks and the values can be retrieved with:dbutils.widgets.get("parameter_name")More recently, we have been given the ability to add parameters to Jobs.However, the parameters cannot be retrieved like Task parameters.Quest...
an update to my answer: Databricks has advised us that the `dbutils.notebook.entry_point` method is not supported (could be deprecated), and the recommended way to read in a job parameter is through widgets, i.e. `dbutils.widgets.get("param_key")` (...
Hello,I am attempting to configure Autoloader in File Notification mode with Delta Live Tables. I configured an instance profile, but it is not working because I immediately get AWS access denied errors. This is the same issue that is referenced here...
HiI am facing issues when deploying work flows to different environment. The same works for Notebooks and Scripts, when deploying the work flows, it failed with "Authorization Failed. Your token may be expired or lack the valid scope". Anything shoul...
There are some tables under schema/database under Unity Catalog.The Notebook need to read the table parallel using loop and thread and execute the query configuredBut the sql statement is not getting executed via spark.sql() or spark.read.table().It ...
Good morning, I'm trying to run: databricks bundle run --debug -t dev integration_tests_job My bundle looks: bundle:
name: x
include:
- ./resources/*.yml
targets:
dev:
mode: development
default: true
workspace:
host: x
r...
Hi @jorperort,
The error message you’re seeing, “no deployment state. Did you forget to run ‘databricks bundle deploy’?”, indicates that the deployment state is missing.
Here are some steps you can take to resolve this issue:
Verify Deploym...
I am currently exploring testing methodologies for Databricks notebooks and would like to inquire whether it's possible to write pytest tests for notebooks that contain code not encapsulated within functions or classes.***********************a = 4b ...
Hi @vinayaka_pallak, Testing Databricks Notebooks is essential to ensure the correctness and reliability of your code. While notebooks are often used for exploratory analysis and prototyping, it’s still possible to write tests for code blocks withi...
We use Terraform to manage most of our infrastructure, and I would like to extend this to Unity Catalog. However, we are extensive users of tagging to categorize our datasets, and the only programmatic method I can find for adding tags is to use SQL ...
Currently, the bronze table ingests JSON files using @Dlt.table decorator on a spark.readStream functionA daily batch job does some transformation on bronze data and stores results in the silver table.New ProcessBronze still the same.A stream has bee...
Hi @Manzilla, When using Delta Live Tables’ dlt.apply_changes for change data capture (CDC), it’s essential to understand how it works.
Let’s break down the process and address your specific scenario:
CDC with Delta Live Tables:
Delta Live Tables...
Getting following error while saving a dataframe partitioned by two columns.Job aborted due to stage failure: Task 5774 in stage 33.0 failed 4 times, most recent failure: Lost task 5774.3 in stage 33.0 (TID 7736) (13.2.96.110 executor 7): ExecutorLos...
Hi @amitkmaurya , The error message you’re encountering indicates that your Spark job failed due to a stage failure.
Task Failure and Exit Code 137:
The error message mentions that Task 5774 in stage 33.0 failed 4 times, with the most recent fai...
Hi everyone! I'm new to Databricks and moving my first steps with Delta Live Tables, so please forgive my inexperience. I'm building my first DLT pipeline and there's something that I can't really grasp: how to clear all the objects generated or upda...
Hi, It seems that when databricks-connect is installed, pyspark is at the same time modified so that it will not anymore work with local master node. This has been especially useful in testing, when unit tests for spark-related code without any remot...
Hi @htu,
When you install Databricks Connect, it modifies the behaviour of PySpark in a way that prevents it from working with the local master node. This can be frustrating, especially when you’re trying to run unit tests for Spark-related code w...
Hi All,Please help me understand how the billing is calculated for using the Job cluster.Document says they are charged hourly basis, so if my job ran for 1hr 30mins then will be charged for the 30mins based on the hourly rate or it will be charged f...
Job clusters consume DBUs per hour depending on the VM size. The Databricks billing happens at "per second granularity", see here. That means if you run your job for 1.5 hours, you will be charged DBUs/hour*1.5*SKU_price; accordingly, if you run your...
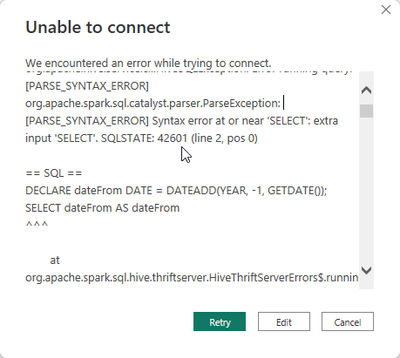
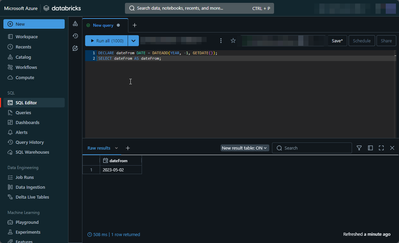
Hello everyone,I'm trying to use the ODBC DirectQuery option in PowerBI, but I keep getting an error about another command. The SQL query works while using the SQL Editor. Do I need to change the setup of my ODBC connector?DECLARE dateFrom DATE = DA...
Hi @mamiya , Here are a few steps you can take to address the error:
Check Power Query Editor Steps:
The error might be related to a specific step in the Power Query Editor. Try opening the Power Query Editor and reviewing the steps. If there’s a...