Hello everyone,I work as a Business Intelligence practitioner, employing tools like Alteryx or various low-code solutions to construct ETL processes and develop data pipelines for my Dashboards and reports. Currently, I'm delving into Azure Databrick...
In my SQL data transformation pipeline, I'm doing chained/cascading window aggregations: for example, I want to do average over the last 5 minutes, then compute average over the past day on top of the 5 minute average, so that my aggregations are mor...
Semenax has truly transformed my life. With its natural ingredients, I've experienced a boost in energy and confidence like never before. Incorporating it into my routine has made a noticeable difference in how I feel every day. Not only do I have mo...
In azure AD, it's shows users are synced to Databricks. But in Databricks, it's showing users is not a part of the group. The user is not part of only one group , he is part of remaining groups. All the syncing works fine till yesterday. I don't now ...
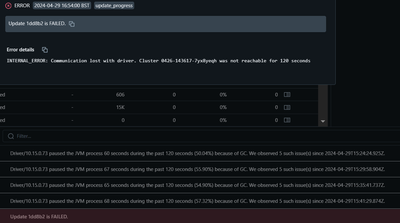
Hi, i am using delta live table in continuous mode for a real time streaming data pipeline. After running the pipeline like 2-3 days i am getting this garbage collection error:Driver/10.15.0.73 paused the JVM process 68 seconds during the past 120 se...
In JupyterLab notebooks, we can --In edit mode, you can press Ctrl+Shift+Minus to split the current cell into two at the cursor position In command mode, you can click A or B to add a cell Above or Below the current cellare there equivalent shortcuts...
What's the status of the ctrl-alt-minus shortcut for splitting a cell? That keyboard combination does absolutely nothing in my interface (running Databricks via Chrome on GCP).
Hello All,In my Databricks workflows, I have three tasks configured, with the final task set to run only if the condition "ALL_DONE" is met. During the first deployment, I observed that the dependency "ALL_DONE" was correctly assigned to the last tas...
After updating my CLI, I successfully deployed the job from Databricks CLI and it is functioning correctly. However, when attempting to deploy the same job using Azure DevOps, I encounter the same issue.
Hello,I am attempting to configure Autoloader in File Notification mode with Delta Live Tables. I configured an instance profile, but it is not working because I immediately get AWS access denied errors. This is the same issue that is referenced here...
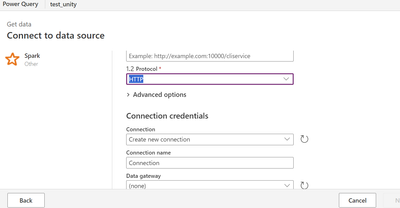
Hi All,Currently I trying to connect databricks Unity Catalog from Powerapps Dataflow by using spark connector specifying http url and using databricks personal access token as specified in below screenshot: I am able to connect but the issue is when...
I install the newest version "databricks-connect==13.0.0". Now get the issue Command C:\Users\Y\AppData\Local\pypoetry\Cache\virtualenvs\X-py3.9\Lib\site-packages\pyspark\bin\spark-class2.cmd"" not found konnte nicht gefunden werden. Traceback...
I am trying to schedule some jobs using workflows and leveraging dynamic variables. One caveat is that when I try to use {{job.start_time.[iso_date]}} it seems to be defaulted to UTC, is there a way to change it?
Hi, all the dynamic values are in UTC (documentation).
Maybe you can use the code like the one presented below + pass the variables between tasks (see Share information between tasks in a Databricks job) ?
%python
from datetime import datetime, timed...
from pyspark.sql import functions as F
from pyspark.sql import types as T
from pyspark.sql import DataFrame, Column
from pyspark.sql.types import Row
import dlt
S3_PATH = 's3://datalake-lab/XXXXX/'
S3_SCHEMA = 's3://datalake-lab/XXXXX/schemas/'
...
Just want to post this issue we're experiencing here in case other people are facing something similar. Below is the wording of the support ticket request I've raised:SQL code that has been working is suddenly failing due to syntax errors today. Ther...
Hi Team,Please provide guidance on enabling SQL cells parallel execution in a notebook containing multiple SQL cells. Currently, when we execute notebook and all the SQL cells they run sequentially. I would appreciate assistance on how to execute th...
Hi @Phani1 ,Can you please explain your usecase as databricks notebook support the sequential executions we have to look for workaround so it will great if you can explain it more.For now you can manually run multiple cell for sql but it's not possib...
Hi Team,We are currently planning to implement Databricks cell-level code parallel execution through the Python threading library. We are interested in comprehending the resource consumption and allocation process from the cluster. Are there any pot...