Hi All Enthusiasts !As per my understanding when a user submits an application in spark cluster it specifies how much memory, executors etc. it would need . But in Data bricks notebooks we never specify that anywhere. If we have submitted the noteboo...
@DBEnthusiast great question! Today, with Job Clusters, you have to specify this. As @btafur note, you do this by setting CPU, memory etc. We are in early preview of Serverless Job Clusters where you no longer specify this configuration, instead Data...
While scheduling the Databricks job using continuous mode - what will happen if the job is configured to run with Job cluster.At the end of each run will the cluster be terminated and re-created again for the next run? The official documentation is n...
Hello @youssefmrini So how is the DBU calculated? As the cluster is reused, the DBU should be calculated per hour on all the jobs run in an hour correct? Or will it be calculated based on each run?I would like to know the cost calculation when runnin...
I want to define a variable and use it in a query, like below: %sql
SET database_name = "marketing";
SHOW TABLES in '${database_name}';However, I get the following error:ParseException:
[PARSE_SYNTAX_ERROR] Syntax error at or near ''''(line 1, pos...
Another option is demonstrated by this example:%sql
SET database_name.var = marketing;
SHOW TABLES in ${database_name.var};
SET database_name.dummy= marketing;
SHOW TABLES in ${database_name.dummy};do not use quotesuse format that is variableName...
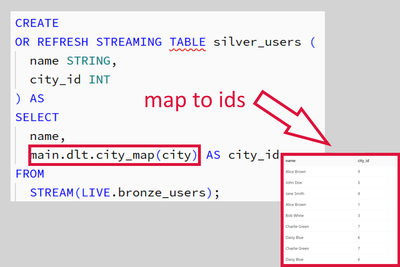
Streamline Data Modeling Normalization with Databricks Delta Live Tables in Just a Few Steps:- Use the "Apply changes" function to populate tables with slowly changing dimensions using auto-increment IDs.- Register SQL mapping functions to associate ...
When importing a .csv file with leading and/or trailing empty spaces around the separators, the output results in strings that appear to be trimmed on the output table or when using .display() but are not actually trimmed.It is possible to identify t...
I discovered an in-depth article that went beyond the physical aspects of aging and testosterone. It examined the emotional https://misterolympia.shop/buy/injectable-steroids/testosterone/testosterone-cypionate/ and psychological aspects of growing o...
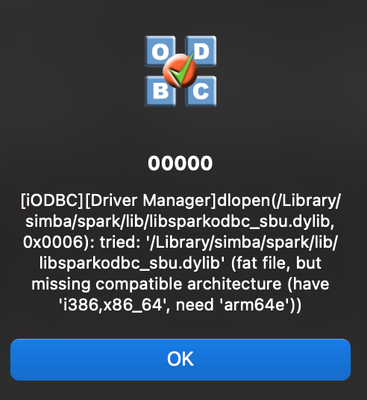
Hi,There's a way to make work the Simba ODBC Driver for M1 Macbook Pros?I find myself able to run on an old intel version of Macbook easily, but now every time I even test the connection with the iODBC Manager fails.Definitely, the issue is around no...
Things seem to be mostly working for me now. I've added a bit more detail on my connection steps and process in case it's helpful for anyone on Stack Overflow: https://stackoverflow.com/questions/76407426/connecting-rstudio-desktop-to-databricks-comm...
Trying to determine a root cause of UDFException that occurs when returning a variable length ArrayType. If I hardcode the data returned from the UDF to a fixed length, say 19, the error does not occur. Setup codesplit_runs_UDF = udf(split_runs_udf, ...
After further investigation, It reproduces slightly differently on single user mode.Single user mode: runs foreverShared: gives the above messageI've determined that there was a corner case in the dataset which lead to UDF never returning. I am am as...
Hi,According to the latest release notes, the current channel of DLT should be using Databricks runtime 11.3 and the preview channel should be using 12.2. The current channel was using correct runtime version 11.3 still yesterday morning, but since ...
I'm seeing the same issue with 12 current / 13 preview. Updating the channel didn't bump the runtime version and even creating a pipeline with the preview channel uses the current version.
Hi Team,I am new to databricks and currently working on creating sql udf 's in databricks .In udf we are calculating min date and that date column using in where clause also.While running udf getting Correlated column is not allowed in non predica...
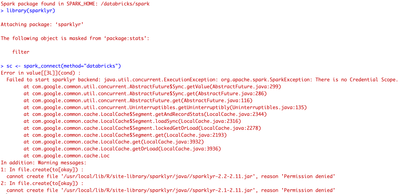
If I start a RStudio Server with in cluster init script as described here in a Unity Catalog Cluster the sparklyr connection fails with an error about a missing Credential Scope.=LI tried it both in 11.3LTS and 12.0 Beta. I tried it only in a Persona...
When running multiple notebooks parallelly using dbutils.notebook.run from a parent notebook, an url to that running notebook is printed, like belowNotebook job #211371132480519Is there a way I can print the notebook name or some customized string in...
Hi @Debayan Thank you for your reply.However, the answer I am looking for is : how to print/get a more meaningful name of the jobs when running multiple notebooks parallelly using dbutils.notebook.run from a parent notebook.Now in the parent notebook...
I want to open some CSV files as an RDD, do some processing and then load it as a DataFrame. Since the files are stored in an Azure blob storage account I need to configure the access accordingly, which for some reason does not work when using an RDD...
I decided to load the files into a DataFrame with a single column and then do the processing before splitting it into separate columns and this works just fine.@Hyper Guy thanks for the link, I didn't try that but it seems like it would resolve the ...
Hi All,Can some one please help me with the error.This is my small python code.binmaster = binmasterdf.withColumnRenamed("tag_number","BinKey")\.withColumn ("Category", when (length("Bin")==4,'SMALL LOT'),(length("Bin")==7,'RACKING'))TypeError : with...
Hi @JohnJustus If you see closely in .withColumn ("Category", when (length("Bin")==4,'SMALL LOT'), when (length("Bin")==7,'RACKING'), otherwise('FLOOR')), withcolumn would take 2 parameters. The first parameter as a string and the second as the colum...
I would like to try out liquid clustering, but all the examples I see seem to be SQL tables created from selecting from other tables. Our gold tables are pyspark tables written directly to a table, e.g. like this: silver_df.writeStream.partitionBy(["...
Hi, I have recently deployed a new Workspace in AWS and getting the following error when trying to start the cluster:"NPIP tunnel setup failure during launch. Please try again later and contact Databricks if the problem persists. Instance bootstrap f...