This seems to only be affecting single-node clusters in GCP and not multi-node clusters. I'm seeing 403 responses for all the css/js assets, among other things. I have not encountered this issue in an Azure workspace I have access to.My cluster is ru...
I used ISO-8859-1 codepage to read the some special characters like A.P. MØLLER - MÆRSK A/S usinh pypsark. But the output is not coming as expected and getting output like this A.P. M?LLER - M?RSK A/S. Can some one help to resolve it.
@Venkat_335 I am not able to reproduce the issue. Please let me know which DBR you are using. It works fine with DBR 12.2 without mentioning the ISO-8859-1
Hi all,recently I am facing a strange behaviour after an OPTIMZE ZOrder command. For a large table around (400 mio. rows) I executed the OPTIMIZE command with ZOrder for 3 columns. However, it seems that the command does not have any effect and the c...
There are several potential reasons why your OPTIMIZE ZORDER command may not have had any effect on your table:The existing data files may already be optimally sorted based on the ZOrder and/or column ordering.If the data is already optimized based o...
Hi community,How can I start SparkSession out of Notebook?I want to split my Notebook into small Python modules, and I want to let some of them to call Spark functionality.
in general (as already stated) a notebook automatically gets a sparksession.You don't have to do anything.If you specifically need to have separate sessions (isolation), you should run different notebooks (or plan different jobs) as these get a new s...
I defined a dictionary variable Dict, populated it, and print(dict) in the first cell of my notebook. In the next cell, I executed the command print(dict) again. However, this time it gave me an error NameError: name 'Dict is not definedHow can that ...
Running pip install restarts the interpreter, meaning that any variable defined prior to the pip install is lost, so indeed the solution is so run the pip install first, or better is to add the library you want to installl directly to the cluster con...
I have a pyspark dataframe, 61k rows, 3 columns, one of which is a string column which has a max length of 4k. I'm doing about 100 different regexp_replace functions on this dataframe, so, very resource intensive. I'm trying to write this to a delta ...
It seems that you're trying to apply a lot of transformations, but it's basic stuff, so I'd go for the best practices documentation and find a way to create a compute-optimized cluster.Ref.: https://docs.databricks.com/en/clusters/cluster-config-best...
reading data form url using spark ,community edition ,got a path related error ,any suggestions please ?
url = "https://raw.githubusercontent.com/thomaspernet/data_csv_r/master/data/adult.csv"
from pyspark import SparkFiles
spark.sparkContext.addFil...
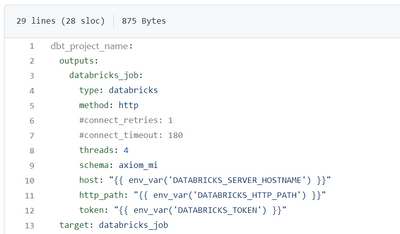
I'm trying to run a dbt project which reads data from ADLS and writes back to ADLS using a Databricks Workflow. When I run the same project from my local machine (using python virtual environment from Visual Studio Code), it's running perfectly fine ...
Tried installing an older version (2.1.0) of databricks-sql-connector (instead of 2.7.0) and surprisingly a new error message appeared. Don't know how to fix this now.
Hi everyone!We have started using Unity Catalog in our Project and I am seeing weird behavior with the schemas from external tables imported to Databricks. On Data Explorer when I expand some tables I see that the schema of those specific tables is w...
It seems like you are encountering an issue with the schema mapping when importing external tables to Unity Catalog in Databricks.To troubleshoot thisBased on the information you've provided, it sounds like the issue you're experiencing could be rel...
I am trying to execute the following command to test API but getting response 400 import jsonimport osfrom urllib.parse import urljoin, urlencodeimport pyarrowimport requests# NOTE set debuglevel = 1 (or higher) for http debug loggingfrom http.client...
A 400 status code response indicates that the server was unable to process the request due to a client error, e.g., incorrect syntax, invalid parametersBased on the code you provided, it appears that you are trying to execute a SQL query against your...
Hi!Getting error message:DatabricksError: User XXX is not part of org: YYY. Config: host=https://adb-ZZZ.azuredatabricks.net, auth_type=runtimeI am in the admin's group, but I cannot alter this in any way. I've tried using the databricks-SDK using:fr...
To resolve this issue, I would recommend taking the following steps:Verify that you have the correct access and permissions:Check with your Databricks organization admin to ensure that your user account has the appropriate access level and permission...
Not sure if this is the right place to ask this question, so let me know if it is not. I am trying to read an xls file which containts #REF values in databricks with pyspark.pandas. When I try to read the file with "pyspark.pandas.read_excel(file_pat...
It sounds like you're trying to open an Excel file that has some invalid references, which is causing an error when you try to read it with pyspark.pandas.read_excel().One way to handle invalid references is to use the openpyxl engine instead of xlr...
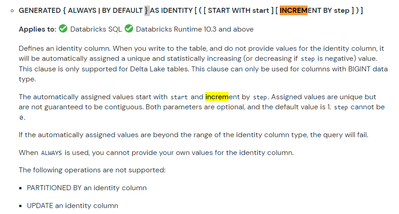
I made multiple inserts (by error) in a Delta table and I have now strict duplicates, I feel like it's impossible to delete them if you don't have a column "IDENTITY" to distinguish lines (the primary key is RLOC+LOAD_DATE):it sounds odd to me not to...
There are several great ways to handle this: https://stackoverflow.com/questions/61674476/how-to-drop-duplicates-in-delta-tableThis was my preference: with cte as(Select col1,col2,col3,etc,row_number()over(partition by col1,col2,col3,etc order by co...
Do we have any explicit benefits with Databricks Views when the view going to be a simple select of table?Does it improve performance by using views over tables?Giving access to views vs Tables?
There can be several benefits to using Databricks views, even when the view is a simple select of a table:Improved query readability and maintainability:By encapsulating queries in views, you can simplify complex queries, making them more readable an...
I have a table created at unity catalog that was dropped, the files are not deleted due to the 30 day soft delete. Is there anyway to copy the files to a different location? When I try to use dbutils.fs.cp I get location overlap error with unity cata...
You can use the dbutils.fs.mv command to move the files from the deleted table to a new location. Here's an example of how to do it: python# Define the pathssource_path = "dbfs:/mnt/<unity-catalog-location>/<database-name>/<table-name>"target_path =...