Hi @Janga Reddy,Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Thanks...
Hi @Pavan Kumar,Hope you are well. Just wanted to see if you were able to find an answer to your question and would you like to mark an answer as best? It would be really helpful for the other members too.Cheers!
Hi,Would like to ask if anyone knows how to connect to GCS - basically read csv file from GCS bucket.I have no issue connecting to Data Lake.Thank you so much in advance.
Hi @James C,Just checking in. If @Kaniz Fatma's answer helped, would you let us know and mark the answer as best? If not, would you be happy to give us more information?We'd love to hear from you.Cheers!
Hi all ! .This is my first post here !I have a problem when I launch a "run all" on my notebook : at a moment (always on the same cell), all the following cells are skipped.As you can see the command 38 is correctly executed and in the command 40 I ...
Hi @valskyyy valentin.lewandowski.partner,Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd lo...
Hi,am trying to apply batch size in autoloader and code is as below. But its picking all the changes in one go even if I have put maxFilesPerTrigger as 10. Appreciate any help.(spark.readStream.format("json").schema(streamSchema).option("cloudFiles.b...
Hi @Sanjay Jain , Since you have provided the trigger as once, the maxFilesPerTrigger will not take effect here. With trigger once, all the files will be read together. You need to change the trigger for this option to come into effect.Please refer ...
Hi, I am new to Databricks and setting up the non-prod environment. I am wanted to know, IS there any way by which I can run a regression suite so that existing setup should not break in case of any feature addition and also how can I make available ...
@deepak prasad :Yes, you can run regression tests to ensure that your changes do not break existing functionality. Databricks supports a number of testing frameworks like PyTest, which can be used to automate regression testing. You can write test c...
Hi, I received free voucher for lakehouse webinar, My friend also got free voucher, by any chance can i use my friend voucher to shedule another exam for me.
Hi guysUnfortunately, it is not possible to share an exam voucher with another Databricks account. Exam vouchers are typically tied to specific accounts or individuals and cannot be transferred or shared. Free Fire
@jin park :You can use the Databricks Delta Lake SHOW TABLE EXTENDED command to get the size of each partition of the table. Here's an example:%sql
SHOW TABLE EXTENDED LIKE '<table_name>'
PARTITION (<partition_column> = '<partition_value>')
SELECT...
I'm having an issue accessing the excel through dlt pipeline. the file is in ADLS I'm using pandas to read the Excel. It seems pandas are not able to understand abfss protocol is there any way to read Excel with pandas in dlt pipeline?I'm getting thi...
We are using Databricks on Azure. Infra team noticed we have some VMs created in the past for DataBricks clusters on version Linux (ubuntu 18.04). Is there maintenance previewed for that, upgrade? Are there any patches for created in Azure objects by...
Finally while I was posting this question, AzureDataBricks upgraded VMs to the supported version 20, not the latest , 22. It was a week after old version was no longer supported by Microsoft
Currently my Alert is an HTML table using data pointing to an SQL query.I was wondering if it is possible to attach the resulting table from this SQL query as a PDF to the alert email.If anyone has successfully implemented this, please let me know! T...
Ok understood the concern, so basically the issue is with PDF rendering as much I understood. Let me know if I am wrong. Let me see if there is any improvement by our engineering team on this front.
Seems to work now actually. No idea what changed, as I tried multiple times exactly in this way and it did.not.work.from pyspark.sql.functions import expr
from pyspark.sql.utils import AnalysisException
import pyspark.sql.functions as f
data = [(...
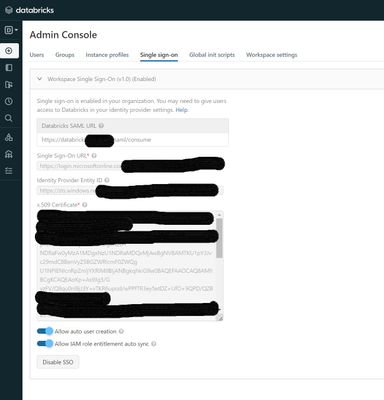
We have Azure AD SSO setup on our workspace but the three year certificate is due to expire on Monday. I have logged onto the Admin Console & Single Sign-on tab. All the options are greyed out and there is no update or edit buttons as can be seen in ...
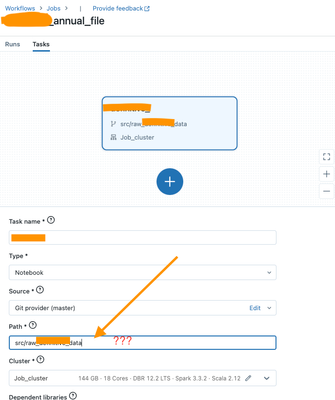
I'm trying to create a workflow job that fetches the notebook from a remote git repository (Bitbucket cloud)I tried everything in the Path field and nothing is working. Note that the bitbucket repo is connected to databricks already and no issues che...
Hi @harraz (Customer) , Could you please confirm if files in repos has been enabled? https://docs.databricks.com/files/workspace.html#configure-support-for-files-in-repos.You can use the command %sh pwd in a notebook inside a repo to check if Files ...