Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
yesterday all of my notebooks seemingly changed to have python formatting (which seems to be in this week's release), but the unintended consequence is that shift + tab (which used to show docstrings in python) now just un-indents code, and tab inser...
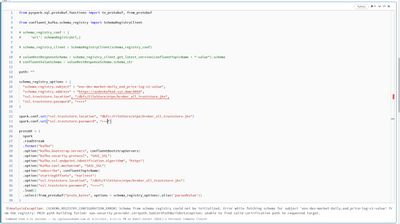
Hi,I am unable to connect to secure schema registry(running on https) as it is breaking with below mentioned error.SCHEMA_REGISTRY_CONFIGURATION_ERROR] Schema from schema registry could not be initialized. Error while fetching schema for subject 'env...
Hi @rahulgulati89, The error message you're encountering indicates that the Java process cannot validate the SSL certificate presented by the Schema Registry.
This is a common issue when the Schema Registry uses a self-signed certificate or a certif...
Hi AllI am trying to insert DF into Synapse table. I need to insert string type columns in DF into Nvarchar fields in Synapse table. I am getting the error ' data type that cannot participate in a columnstore index Error' Can someone guide on the i...
Hi @DataEng1, you are trying to insert a DataFrame with string type columns into a Synapse table with NVARCHAR fields and encountering a ’data type that cannot participate in a columnstore index Error’.
The issue is likely occurring because you are t...
Hi @shivalanka, it seems you are encountering issues due to not deleting clusters and other resources associated with the workspace before deleting the workspace.
Databricks recommends terminating all clusters and instance pools associated with a wo...
Hello Databricks Community, I asked the same question on the Get Started Discussion page but feels like here is the right place for this question. I'm reaching out with a query regarding access control in the hive_metastore. I've encountered behavior...
That is expected. The single user mode is the legacy standard + UC ACL enabled. https://docs.databricks.com/en/archive/compute/cluster-ui-preview.html#how-does-backward-compatibility-work-with-these-changes
For your case, you need the hive table acl ...
Always set a timeout for your jobs! It not only safeguards against unforeseen hang-ups but also optimizes resource utilization. Equally essential is to consider having a threshold warning. This can alert you before a potential failure, allowing proac...
Hi @Someswara Durga Prasad Yaralgadda (Customer), We haven’t heard from you since the last response from @Suteja Kanuri (Customer), and I was checking back to see if her suggestions helped you.Or else, If you have any solution, please share it w...
I created a notebook that uses Autoloader to load data from storage and append it to a bronze table in the first cell, this works fine and Autoloader picks up new data when it arrives (the notebook is ran using a Job).In the same notebook, a few cell...
Thanks @Kaniz_Fatma, in a case where it's not possible or not practical to implement a pipeline with DLTs, what would be that "retry mechanism" based on ? I.e., is there an API other that the table history that can be leveraged to retry until "it wo...
Concerning job cluster configuration, I'm trying to figure out what happens if AWS node type availability is smaller than the minimum number of workers specified in the configuration json (either availabilty<num_workers or, for autoscaling, availabil...
thanks, @Kaniz_Fatma , useful info!My specific scenario is running a notebook task with Job Clusters, and I've noticed that I get the best overall notebook run time by going without Autoscaling, setting the cluster configuration with a fixed `num_wor...
I am running the following structured streaming Scala code in DB 13.3LTS job: val query = spark.readStream.format("delta")
.option("ignoreDeletes", "true")
.option("maxFilesPerTrigger", maxEqlPerBatch)
.load(tblPath)
.writeStream
.qu...
Hi @DE-cat ,
• The given code is a structured streaming Scala code that reads data from a Delta table, processes it, and writes the output to a streaming sink.• The job gets cancelled around 30 minutes after starting with error messages like DAGSche...
I have proto files (offline data storage) that I'd like to read from a Databricks notebook. I found this documentation (https://docs.databricks.com/structured-streaming/protocol-buffers.html), but it only covers how to read the protobuf data once the...
When starting a DB job using 13.3 LTS (includes Apache Spark 3.4.1, Scala 2.12) cluster, I am seeing a lots of these errors in log4j output. Any ideas? Thx23/09/11 13:24:14 ERROR CommandLineHelper$: Command [REDACTED] failed with exit code 2 out: err...
Hi @DE-cat , To configure an AWS instance connection in Databricks, you need to follow these steps:1. Create an access policy and a user with access keys in the AWS Console: - Go to the IAM service. - Click the Policies tab in the sidebar. - Click...
Hi,I'm connecting to a Databricks instance on Azure from a Windows Application using Simba ODBC driver, and when running SQL statements on delta tables, like INSERT, UPDATE, DELETE commands using Execute, the result doesn't indicate the no. of rows a...
Hi @DBUser2 ,
When using the Simba ODBC driver to connect to Databricks on Azure and running SQL statements like INSERT, UPDATE, or DELETE, it's common to encounter a result of -1 for the number of rows affected.
This behaviour is not specific to th...
I have "Git provider" job created and running fine on the remote git. The problem is that I have to manually trigger it. Is there a way to run the job automatically whenever a new commit to the branch? (In "Schedules & Triggers section", I can find a...
Hi @yzhang, To automatically trigger a job whenever there is a new commit to the branch in a remote Git repository, you can follow these steps:
1. Go to your job's "Schedules and Triggers" section.2. Click on the "Add Trigger" button.3. In the trigge...
Hello,This is question on our platform with `Databricks Runtime 11.3 LTS`.I'm running a Job with multiple tasks in // using a shared cluster.Each task runs a dedicated scala class within a JAR library attached as a dependency.One of the task fails (c...
Hi,This actually should not be marked as solved. We are having the same problem, whenever a Shared Job Cluster crashes for some reason (generally OoM), all tasks will start failing until eternity, with the error message as described above. This is ac...