Hi @Deepak Kini Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answers y...
I'm getting cannot read python file on running this job which is configured to run a python script from git repo. Run result unavailable: run failed with error message Cannot read the python file /Repos/.internal/7c39d645692_commits/ff669d089cd8f93e9...
Hi Vidula,Yes, the above solution worked out for me. Tried debugging using all of the above steps and it turned out the path I was using in the job config was incorrect.
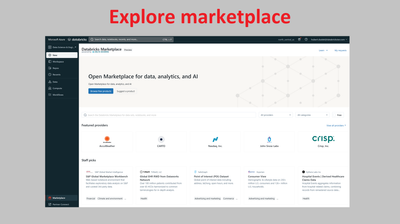
Databricks marketplace is here. With Databricks Marketplace, you can easily browse and discover data that suits your needs and get instant access with Delta Sharing. Once you find a dataset you like, you can add it to your Databricks catalog.
I want to load incremental data to the delta live table, I wrote function to load data for 10 tables, every time that I run the pipe line, some tables are empty and have a schema, and when I run again, the other tables are empty and the previous tabl...
@zahra Jalilpour How the DLT tables and views are updated depends on the update type:Refresh all: All live tables are updated to reflect the current state of their input data sources. For all streaming tables, new rows are appended to the table.Full...
Hi @ananthakrishna raikar Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best...
Can somebody give me good definition of delta lake vs delta table? What are the use cases of each, similarities and differences? Sorry I’m new to databricks ans trying to learn.
Delta Lake and Delta table are related concepts in the Apache Delta Lake project. which extends Apache Spark with ACID (Atomicity, Consistency, Isolation, Durability) capabilities for data lakes. Delta Lake provides a storage layer that enables trans...
I'm trying to setup autoloader to read some csv files. I tried with both autoloader with the DLT decorator as well as just autoloader by itself. The first column of the data is called "run_id", when I do a spark.read.csv() directly on the file it com...
Does anyone have a workflow or pattern that works for developing with autoloader/DLT? I'm still new to but the fact that while testing it's creating checkpoints using schema locations makes it really tricky to develop with and hammer out a working ve...
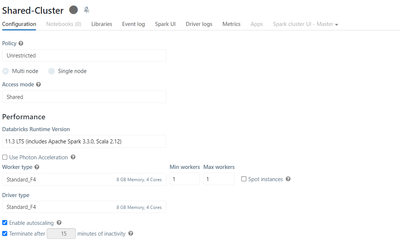
Hi Experts,Am using 'DataScience and Engineering' Workspace in Azure databricks and want to test 'table access control' on legacy Hive metastore on cluster.i did all what is mentioned in the link 'https://learn.microsoft.com/en-us/azure/databricks/da...
Hi @nishin kumar Hope everything is going great.Just wanted to check in if you were able to resolve your issue. If yes, would you be happy to mark an answer as best so that other members can find the solution more quickly? If not, please tell us so ...
I want to generate a personal access token on a service principal. I generated a service principal in Azure active directory and using Azure devops pipeline, I got it added to databricks workspace- where I am a work space administrator. After adding ...
Hi @Anurag Ranjeet Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answer...
Hi @joao vnb Hope everything is going great.Just wanted to check in if you were able to resolve your issue. If yes, would you be happy to mark an answer as best so that other members can find the solution more quickly? If not, please tell us so we c...
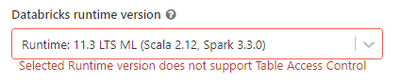
After reviewing this Deprecations, I discovered that Table Access Control is not supported in Databricks Runtime for Machine Learning.I want to understand why table access control is not designed for ML runtime. Is there any reason behind this?
@Thanapat Sontayasara Table Access Control (TAC) is a feature in Databricks that allows you to restrict access to specific tables in your workspace based on user or group identity.According to the Databricks documentation, TAC is not supported in th...
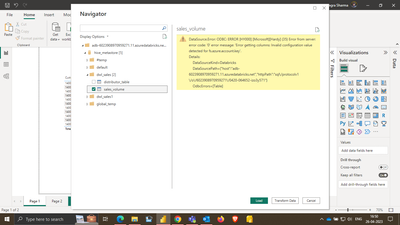
Hi everyone .. i have an issue while connecting azure Databricks cluster delta tables(location Abfs) with PowerBi for analytics Purpose. but after succesfully linking cluster using Server Hostname and HTTP Path with powerbi is showing an error:-Data...
`AttributeError` when attempting to transfer files from `dbfs` filestore in DataBricks to a local directory. import pyspark.dbutils as pdbutils
pdbutils.fs.cp("/dbfs/Data/file1.csv", "/Users/Downloads/")
Traceback (most recent call last):
...
Hi @Keval Shah Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answers yo...