When I aggregate over more data, I get the below error message. I've tried multiple ways of diagnosis like going back to a version I know it was working fine (but still got the same error below). Please advise as this is a critical report where the b...
@Jeff Wu :The error message suggests that there is a syntax error in a SQL statement, specifically near the end of the input. Without the full SQL statement or additional information, it's difficult to pinpoint the exact cause of the error. However,...
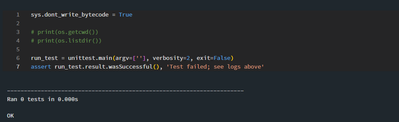
I have a test file (test_transforms.py) which has a series of tests running using Python's unittest package. I can successfully run the tests inside of the file with expected output. But when I try to run this test file from a different notebook (run...
@Fuad Goloba :When running tests on Databricks, you need to ensure that the test file is uploaded to the Databricks workspace and that the correct path is specified when importing the test module in the notebook that is running the tests. Here's an ...
The master notebook is calling a child notebook using dbutils.notebook.run("PathToChildnotebook"). The child notebook defines a user-defined function (UDF) and registers it using spark.udf.register. However, when the child notebook finishes running a...
@andrew li :The reason why the UDF cannot be found is that when the child notebook finishes running, the Spark context that was used to define and register the UDF is destroyed. Therefore, the UDF is no longer available in the Spark context used by ...
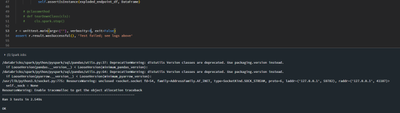
The below error I am encountering . I am using microbatch for autoloader. please help to rectify this issuejava.lang.AssertionError: assertion failed: Invalid batch: path#36188,modificationTime#36189,length#36190L,content#36191,PROVIDER#36192,LOCATIO...
@Ayesha Rahmatali :The error message you provided suggests that there is an assertion failure due to invalid batch data in your AutoLoader implementation. The error specifically indicates that the schema of the incoming data is not matching with the...
I want to use the same spark session which created in one notebook and need to be used in another notebook in across same environment, Example, if some of the (variable)object got initialized in the first notebook, i need to use the same object in t...
In an init script or a notebook, we can:pip install --index-url=<our private pypi url> --extra-index-url=https://pypi.org/simple <a module>In the cluster web UI (libraries -> install library), we can give only the url of our private repository, but n...
Hi @Philippe CRAVE Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answer...
I can connect ArcGIS to Databricks using ODBC, but using the same ODBC DSN for QGIS I get an error - Unable to initialize ODBC connection to DSNHas anyone got this working?
@Grainne Farrant :It is possible to connect QGIS to Databricks using ODBC, but it requires additional configuration. Here are the general steps to follow:Install the ODBC driver for Databricks on your machine where QGIS is installed. You can downloa...
Hi @Sabyasachi Samaddar We are going through a contract renewal with our vendor, Accredible. Once our new contract goes through you will get your badge this week.Thank you for understanding.
I was trying to find information about configuring the consumer groups for kafka stream in databricks. By doing so I want to parallelize the stream and load it into databricks tables. Does the databricks handle this internally? If we can configure th...
Hi, we have a few examples on stream processing using Kafka (https://docs.databricks.com/structured-streaming/kafka.html), there is no straight public document for Kafka consumer group creation. You can refer to https://kafka.apache.org/documentation...
I have set the delta table property at cluster level.spark.databricks.delta.retentionDurationCheck.enabled falseWhen I create a new table, retentionDurationCheck property is not shown in the table details. But when I set this with ALTER TABLE for a s...
Hi @Mahesh Chahare Hope everything is going great.Just wanted to check in if you were able to resolve your issue. If yes, would you be happy to mark an answer as best so that other members can find the solution more quickly? If not, please tell us s...
Hi Team,My databricks exam got suspened on 16th April today Morning and it is still in the suspended state. I have raised a support request using the below linkhttps://help.databricks.com/s/contact-us?ReqType=training . but I haven’t received the ti...
Hi @Sachin Kumara We are going through a contract renewal with our vendor, Accredible. Once our new contract goes through you will get your badge this week. Thank you for understanding!
Hi everyone,I was stuck at this for very long time. Not a very familiar user of using Spark for image processing. I was trying to resize images that are loaded into a Spark DF. However, it keeps throwing error that I am not able to access the element...
@Yan Chong Tan :The error you are facing is due to the fact that you are trying to access the attribute "width" of a string object in the resize_image function. Specifically, input_dim is a string object, but you are trying to access its width attr...
When I use SQL code like "create table myTable (column1 string, column2 string) using csv options('delimiter' = ',', 'header' = 'true') location 'pathToCsv'" to create a table from a single CSV file stored in a folder within an Azure Data Lake contai...
Hi @andrew li, When you specify a path with LOCATION keyword, Spark will consider that to be an EXTERNAL table. So when you dropped the table, you underlying data if any will not be cleared. So in you case, as this is an external table, you folder s...
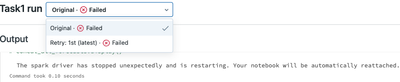
I have a daily job run that occasionally fails with the error: The spark driver has stopped unexpectedly and is restarting. Your notebook will be automatically reattached. After I get the notification that this job failed on schedule, I manually run ...
I’ve had success with R magic (R cells in a Python notebook) and running an R script from a Python notebook, up to the point of connecting R to a Spark cluster. In either case, I can’t get a `SparkSession` to initialize. 2-cell (Python) notebook exa...
The answer I can give you to have this work for you is to call the R notebooks from your Python notebook. Just save each dataframe as a delta table to pass between the languages.How to call a notebook from another notebook? here is a link