Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
I want to create a surrogate in the delta table And i used the identity column id-Generated as DefaultCan i insert rows into the delta table using only spark.sql like Insert query ? or i can also use write delta format options? If i use the df.write ...
Hi @Menaka Murugesan(Customer), We haven’t heard from you since the last response from @Nandini N (Customer), and I was checking back to see if her suggestions helped you.Or else, If you have any solution, please share it with the community, as ...
Helo today ,i think i was scheduled to do an exams at 2.15 PM but unfortunately i made a mistake put the time to 2.15 AM, could it be rescheduled? i already submit a ticket to https://help.databricks.com/s/contact-us?ReqType=training but no reply yet...
Hi @heron halim (Customer), We haven't heard from you since the last response from @Akshay Padmanabhan, and I was checking back to see if his suggestions helped you. Or else, If you have any solution, please share it with the community, as it ca...
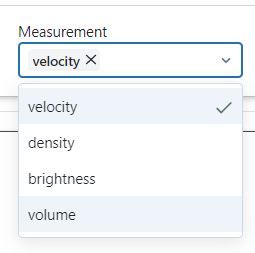
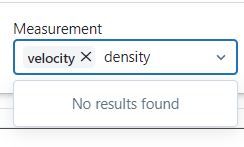
In the AWS databricks widgets.multiselect, I'm unable to find input by typing input in the mulitselect bar. It was working before. Although I can find the inputs by scrolling down the list, it's annoying if the list is long.Here's my script:measlis...
Hi @Philip Teu Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Thanks!
Hello expertI am new to spark. I am using same price of code but getting different resultsWhen i am using below piece of code, i am getting errorpy4j.Py4JException: Method or([class java.lang.String]) does not existdf.filter(F.col("state").isNull() ...
Hi @Saswata Dutta Thank you for your question! To assist you better, please take a moment to review the answer and let me know if it best fits your needs.Please help us select the best solution by clicking on "Select As Best" if it does.Your feedbac...
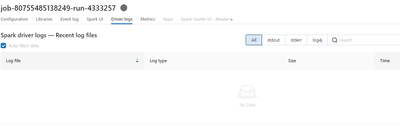
I am running jobs on databricks clusters. When the cluster is running I am able to find the executor logs by going to Spark Cluster UI Master dropdown, selecting a worker and going through the stderr logs. However, once the job is finished and cluste...
Hi @Atul Arora Thank you for your question! To assist you better, please take a moment to review the answer and let me know if it best fits your needs.Please help us select the best solution by clicking on "Select As Best" if it does.Your feedback w...
Partner want to use adf managed identity to connect to my databricks cluster and connect to my azure storage and copy the data from my azure storage to their azure storage storage
Hi @SAI PUSALA Thank you for your question! To assist you better, please take a moment to review the answer and let me know if it best fits your needs.Please help us select the best solution by clicking on "Select As Best" if it does.Your feedback w...
Yesterday I had a basic DLT pipeline up and running, and was able to query the hive_metastore tables successfully. The pipeline uses autloader to ingest a few csv files from cloud storage to streaming live bronze and silver tables. Today after star...
Hi @Jennette Shepard Thank you for your question! To assist you better, please take a moment to review the answer and let me know if it best fits your needs.Please help us select the best solution by clicking on "Select As Best" if it does.Your feed...
Hi @Frank Munz Thank you for your question! To assist you better, please take a moment to review the answer and let me know if it best fits your needs.Please help us select the best solution by clicking on "Select As Best" if it does.Your feedback w...
Hi @Vijay Gadhave Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Than...
Hello Everyone,I am facing the challenge while collecting a spark dataframe into an R dataframe, this I need to do as I am using TraMineR algorithm whih is implemented in R only and the data pre-processing I have done in pysparkI am trying this:event...
Hi @Niraj Tanwar Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Thank...
Hi Team,Good morning.As of now, for the deployment of our code to Databricks, dbx is configured providing the parameters such as cloud provider, git provider, etc., Say, I have a code repository in any one of the git providers. Can this process of co...
Hi @Arunsundar Muthumanickam Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear fr...
Hi,I have a PySpark DataFrame with 11 million records. I created the DataFrame on a cluster. It is not saved on DBFS or storage account. import pyspark.sql.functions as F
from pyspark.sql.functions import col, when, floor, expr, hour, minute, to_time...
I'm trying to get rid of the warning below:/databricks/spark/python/pyspark/sql/context.py:117: FutureWarning: Deprecated in 3.0.0. Use SparkSession.builder.getOrCreate() instead.In my setup, I have a front-end notebook that gets parameters from the ...
That fixes it. Thanks. I need to do spark = SparkSession.builder.getOrCreate() df = spark.table("prod.some_schema.some_table")instead of sc = SparkSession.builder.getOrCreate() sqlc = SQLContext(sc) df = sqlc.table(f"prod.some_schema.some...
Hi Everyone,I need a job to be triggered every 5 minutes. However, if that job is already running, it must not be triggered again until that run is finished. Hence, I need to set the maximum run concurrency for that job to only one instance at a time...
@Michael Okulik :To ensure that a Databricks job is not triggered again until a running instance of the job is completed, you can set the maximum concurrency for the job to 1. Here's how you can configure this in Databricks:Go to the Databricks work...
Hi Team,I am getting error that voucher code expired when trying to register for "Databricks Certified Associate Developer for Apache Spark 3.0 - Python" certification.Can you please help here
Hi @Sandeep Venishetti Hope everything is going great.Just wanted to check in if you were able to resolve your issue. If yes, would you be happy to mark an answer as best so that other members can find the solution more quickly? If not, please tell ...