Hi, I'm new here.Currently I have to read information from a query in databricks. I've used the query API to get the query definition but so far I'm not able to run the query and get the results.Is it possible? Thanks
When using the JobsAPI you need to specify dbutils.notebook.exit("returnValue") to pass the results once the notebook finished it's job (https://docs.databricks.com/notebooks/notebook-workflows.html#notebook-workflows-exit).Then you can get notebook_...
in my dataframe it have one column name like count, if that particular column value is greater than zero, the job needs to get failed, how can i perform that one?
Code without collect, which should not be used in production:if df.filter("count > 0").count() > 0: dbutils.notebook.exit('Notebook Failed')you can also use a more aggressive version:if df.filter("count > 0").count() > 0: raise Exception("count bigge...
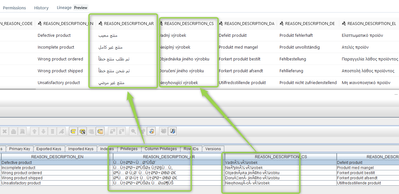
A Parquet file contains character data for various languages and is shown by the Data Explorer UX. A simple "select *" query using the Databricks JDBC driver (version 2.6.29) with a tool such as SQLSquirrel displays invalid characters.
I'm using PyDeequ data quality checks in one of our jobs. After adding this check, I noticed that the job does not complete and keeps running indefinitely after PyDeequ checks are completed and results are returned.As stated in Pydeequ documentation ...
Hm, deequ certainly works as I have read about multiple people using it.And when reading the issues (open/closed) on the github pages of pydeequ, databricks is mentioned in some issues so it might be possible after all.But I think you need to check y...
how can we parameterize key of the spark-config in the job cluster linked service from Azure datafactory, we can parameterize the values but any idea how can we parameterize the key so that when deploying to further environment it takes the PROD/QA v...
@KVNARK . You can use Databricks Secrets (create a Secret scope from AKV https://learn.microsoft.com/en-us/azure/databricks/security/secrets/secret-scopes) and then reference a secret in spark configuration (https://learn.microsoft.com/en-us/azure/d...
Hey Guys, I'm having some permission issues using service principal and instance profile and i hope you could help me.I created a service principal and attached to it an instance profile - databricks-my-profile.I have a s3 bucket with policy that all...
Hey @Kaniz Fatma , @Debayan Mukherjee, Thanks for your answers.Actually, Databricks is not support using DBFS API with service principal & attached instance profile on a mounted s3 bucket.I'm not sure if this exists in docs (might miss it) but thi...
I am trying to read a folder with partition files where each partition is date/hour/timestamp.csv where timestamp is the exact timestamp in ISO format, e.g. 09-2022-12-05T20:35:15.2786966Z It seems like spark having issues with reading files with col...
Hi @Hanan Shteingart (Customer), We haven’t heard from you since the last response from @Debayan Mukherjee (Customer) , and I was checking back to see if his suggestions helped you.Or else, If you have any solution, please share it with the co...
i want to write title with some combination of rows in pandas df, and write into excel sheet. i tried some method but i could see styler object is not subscriptable
Hi @Mohammed sadamusean (Customer), We haven’t heard from you since the last response from @Ratna Chaitanya Raju Bandaru, and I was checking back to see if his suggestions helped you.Or else, If you have any solution, please share it with the com...
I am trying to access files stored in Azure blob storage and have followed the documentation linked below:https://docs.databricks.com/external-data/azure-storage.htmlI was successful in mounting the Azure blob storage on dbfs but it seems that the me...
I'm trying to reuse a Python Package to do a very complex series of parsing binary files into workable data in Delta Format. I have made the first part (binary file parsing) work with a UDF:asffileparser = F.udf(File()._parseBytes,AsfFileDelta.getSch...
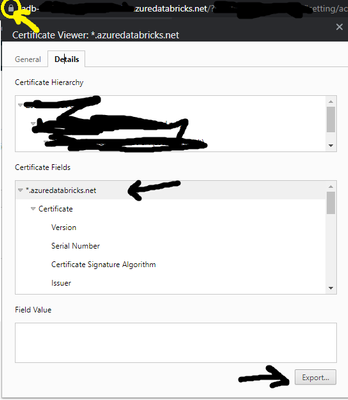
I am trying to setup databricks-connect in my windows machine. While doing databricks-connect test I am getting the below error complaining java certificate is not found. ''Caused by: sun.security.validator.ValidatorException: PKIX path building fail...
I setup a notebook to ingest data using Auto Loader from an S3 bucket that contains over 500K CSV files into a hive table.Recently the amount of rows (and input files) in the table grew from around 150M to 530M and now each batch takes around an hour...
Hi @Dotan Schachter Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Th...
Is it possible to schedule refresh and share a csv format of a table visual in a dashboard? Also, is it possible to share only one visual in a dashboard when there are more than one?
Hi @Sujitha Bommayan Hope everything is going great.Does @Kaniz Fatma response answer your question? If yes, would you be happy to mark it as best so that other members can find the solution more quickly?We'd love to hear from you.Thanks!
I want to read 1000 GB data. As in spark we do in memory transformation. Do I need worker nodes with combined size of 1000 GB.Also Just want to understand if will reading we store 1000 GB in memory. So how the Cache Data frame is different from the a...
I have the same problem as described in this post (https://community.databricks.com/s/question/0D58Y00009ObQgdSAF/running-jobs-using-notebooks-in-a-remote-azure-devops-services-repos-git-repository-is-generating-notebook-not-found-error) and get this...