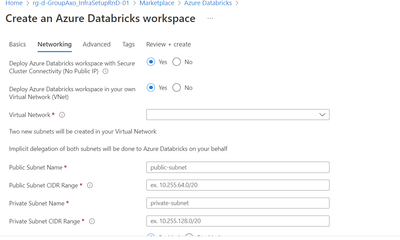
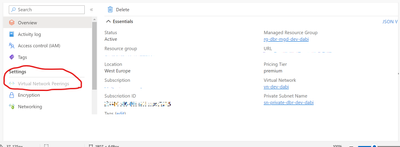
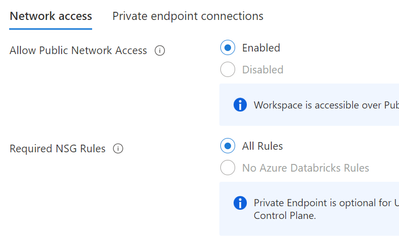
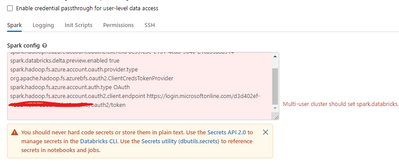
Hi All,Vnet peering settings is not enabled in Azure databricks , even though its deployed inside my VNET?Here i not mentioned my vnet and subnet details , but filled this and created databricks (without private endpoint - allow public access)virtual...
Hi, VNET peering is not supported or possible on VNET-injected workspaces. Please refer: https://learn.microsoft.com/en-us/azure/databricks/administration-guide/cloud-configurations/azure/vnet-peering#requirements
Hello all,I want to know how to update new data in delta table from new csv file.here is the code that i have used to create delta table from csv file and loaded data. but i have go new updated file and trying to load new data but not able to any gui...
Thank you, i tried that and it ended in error, the table created with delta are from csv which must have converted to parquet file and all the columns are varchar or string. so not if i want to entered new file it ends in incmopatibility error for da...
Hi All,Kindly help me , how i can add the ADLS gen2 OAuth 2.0 authentication to my high concurrency shared cluster. I want to scope this authentication to entire cluster not for particular notebook.Currently i have added them as spark configuration o...
Hi @Sunilprasath Elangovan , We haven’t heard from you since the last response from @Hubert Dudek, and I was checking back to see if his suggestions helped you. Or else, If you have any solution, please do share that with the community as it can b...
Here is the situation I am working with. I am trying to extract source data using Databricks JDBC connector using SQL Server databases as my data source. I want to write those into a directory in my data lake as JSON files, then have AutoLoader ing...
To add to @werners point, I would use ADF to load SQL server data into ADLS Gen 2 as json. Then Load these Raw Json files from your ADLS base location into a Delta table using Autoloader.Delta Live Tables can be used in this scenario.You can also reg...
i tried some code to create border for excel sheet, for particular cell iam able to write but while i am trying with some set of cells means it is showing error.
Hi @Mohammed sadamusean ,Can you please try similar to below code using loops, I have implemented a similar use case that might be useful, please let me know if you need further top = Side(border_style = 'thin',color = '00000000')
bottom = Side(bor...
"If Condition" has lot of activities that can succeeded or fail. If any activity fails then whole "If Condition" fails. I have to get the status of the "If Condition" activity (pass or fail) so that i can use it for processing in the next notebook t...
Hi @srikanth nair, We haven’t heard from you since the last response from @Hubert Dudek and @Uma Maheswara Rao Desula, and I was checking back to see if their suggestions helped you. Or else, If you have any solution, share that with the communit...
Hi team.Would you please help check on my case?From 30-Nov I have placed an order "Databricks Certification: Fully Sponsored" on https://communitydatabricks.mybrightsites.com/ and after waiting 10 bussiness days. I still not receive that voucher.Is t...
Hi, I would like to understand Databricks JAR based workflow tasks. Can I interpret JAR based runs to be something like a spark-submit on a cluster? In the logs, I was expecting to see the spark-submit --class com.xyz --num-executors 4 etc., And, the...
Hi, I did try using the Workflows>Jobs>CreateTask>JarTaskType>UploadedMyJAR and Class and created JobCluster and tested this task. This JAR reads some tables as input, does some transformations and output as writing some other tables. I would like t...
Hi All, I am trying to read streams directly from AWS S3. I set the instance profile , but when i run the workflow it fails with below error"No AWS Credentials provided by TemporaryAWSCredentialsProvider : shaded.databricks.org.apache.hadoop.fs.s3a.C...
Hi @SUDHANSHU RAJ is UC enabled on this workspace? What is the access mode set on the cluster? Is this coming from the metastore or directly when you read from S3? Is the S3 cross-account?
Hello ! I playing with autoloader schema inference on a big S3 repo with +300 tables and large CSV files. I'm looking at autoloader with great attention, as it can be a great time saver on our ingestion process (data comes from a transactional DB gen...
PySpark by default is using \ as an escape character. You can change it to "Doc: https://docs.databricks.com/ingestion/auto-loader/options.html#csv-options
@Kaniz Fatma Is that tool (dbvim) still maintained? It looks like it has been abandoned and there are a couple of unresolved issues.Are there any plans to support vim keybindings in Databricks? This is possible in many other web-based editors such a...
Hi Team,I want to connect to collibra to fetch details from Collibra.Currently we are using username and password to connect.I want to know recommended practice to connect Collibra account from databricks notebook.
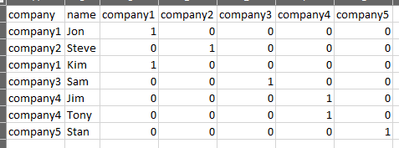
Hi,I have a dataframe that has name and companyfrom pyspark.sql import SparkSessionspark = SparkSession.builder.appName('SparkByExamples.com').getOrCreate()columns = ["company","name"]data = [("company1", "Jon"), ("company2", "Steve"), ("company1", "...
In my opinion, it doesn't make sense, but...you can Mount SMB Azure file share on a Windows Machine https://learn.microsoft.com/en-us/azure/storage/files/storage-how-to-use-files-windows and then mount the same folder on databricks using pip install ...
I have taken a trial version of Databricks and wanted to configure it with AWS. but after login it was showing as blank screen since 20 hours. can someone help me with this. Note: strictly i have to use AWS with Databricks for configuration.