Hello, I am trying to download lists from SharePoint into a pandas dataframe. However I cannot get any information successfully. I have attempted many solution mentioned in stackoverflow. Below is one of those attempts: # https://pypi.org/project/sha...
Hi @kalle preetham Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Tha...
Lakehouse Fundamentals Accreditation badge not receivedI just passed the Lakehouse Fundamentals Accreditation at https://partner-academy.databricks.com/ and I haven't received my badge yet and cant find the credentials. Please advise.
Hi @Prashant Singh Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Tha...
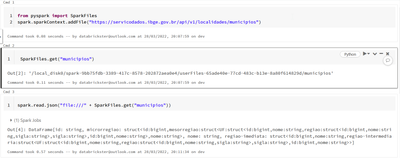
How to process files from the internet in databricks?"spark.sparkContext.addFile" download file to HDFS directory. "SparkFiles.get" return the path and the name. However, as Databricks use the DBFS file system, we need to add the "file:///" prefix to...
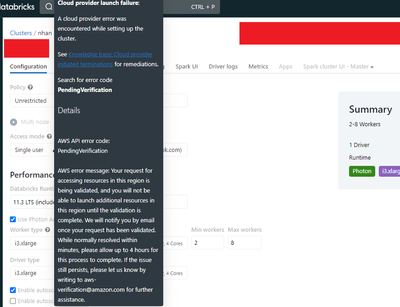
@Hubert Dudek Do you know if addFile should work with abfss:// path? Trying to add a file from azure data lake with external location in unity catalog.
I have [very] recently started using DLT for the first time. One of the challenges I have run into is how to include other "modules" within my pipelines. I missed the documentation where magic commands (with the exception of %pip) are ignored and was...
I like the approach @Arvind Ravish shared since you can't currently use %run in DLT pipelines. However, it took a little testing to be clear on how exactly to make it work. First, ensure in the Admin Console that the repos feature is configured as f...
Hey guys,Databricks academy login is not working. I have been trying for the past 1 hour and still doesn't work. It seems to be with the Databricks https certificate being expired but not sure. I'm attaching an image with the error. Any help with thi...
Hi @Andre Paiva ,Can you please try now I can able to load both customer and partner academy websites, I think the Academy team has fixed the issue. Happy Learning!!
how to add a current date after filename suffix while copy from the dbutils like report20221223.xlsxdbutils.fs.cp('dbfs://temp/balancing/report.xlsx','abfss://con@adls/provsn/result/report.xlsx',True)i need to add the current date in the file like ...
Hi @Mohammed sadamusean, We haven’t heard from you since the last response from @Aviral Bhardwaj and @Ratna Chaitanya Raju Bandaru, and I was checking back to see if their suggestions helped you. Or else, If you have any solution, please do share ...
I recently tried the new editor, and usual shortcuts like CTRL + / to comment is ineffective. Is this a known issue? It's working fine with the classic editor, so I am switching back to it in the meantime, but it would be great to use this new additi...
Deltalake Vs Datalake in Databricks Delta Lake DatabricksDelta Lake is an open-source storage layer that sits on top of existing data lake storage, such as Azure Data Lake Store or Amazon S3. It provides a more robust and scalable alternative to tra...
I have an Azure KeyVault with private endpoint created in the same Vnet as Azure Databricks. While trying to add it as a scope using the private DNS Zone ie <KVname>.privatelink.vaultcore.azure.netgetting error "DNS is invalid and cannot be reached....
I got it working by creating the KV backed scope via UI. I used the the dns without the private part: <KVName>.vault.azure.netThe private dns will resolve it to the right IP.You do have to check the "Allow trusted Microsoft services to bypass this fi...
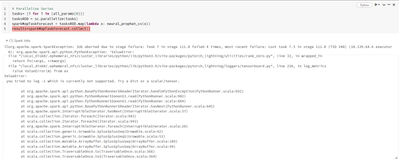
I'm training a NeuralProphet for a time series forecasting problem. I'm trying to parallelize my training, but this error is appearingThe folder lightning_logs has a hparams.yaml but it's empty. Is this related to permissions on the cluster? Thanks i...
Understanding Unity Catalog in Databricks In Databricks, the Unity Catalog is a data catalog that allows you to store, access, and manage data within your Databricks workspace. It provides a unified interface for working with data across different s...
Hello, I have the following minimum example working example using multiprocessing:from multiprocessing import Pool
files_list = [('bla', 1, 3, 7), ('spam', 12, 4, 8), ('eggs', 17, 1, 3)]
def f(t):
print('Hello from child process', flush = Tr...
Hello,I'm trying to write to a Delta Table in my Databricks instance from a remote Spark session on a different cluster with the Simba Spark driver. I can do reads, but when I attempt to do a write, I get the following error:{ df.write.format("jdbc...
Could you try setting the flag to ignore transactions? I’m not sure what the exact flag is, but there should be more details in the JDBC manual on how to do this