Hi, I am new to DB SQL. I have a table where the array column (cities) contains multiple arrays and some have multiple duplicate values. I need to unpack the array values into rows so I can list the distinct values. The following query works for this...
Today I was working in Timezone kind of data but my Singapore user want to see their time in the Data and USA user want to see their time in the datainstead of both, we all are getting UTC time,how to solve this issuePlease guide Data can be anything...
Hi there!!we are planning to use databricks -tableau on prem integration for reporting. Data would reside in delta lake and using ta leau-databricks connector, user would be able to generate reports from that data .question is: a private end point wi...
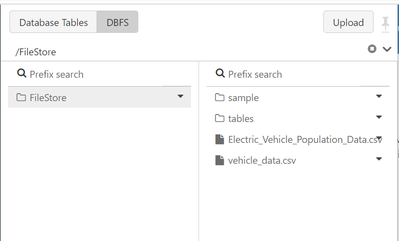
Hi,I am new to databricks, and was trying to follow some tutorial to upload a file and move it under some different folder. I used DBFS option.While trying to move/rename the file I am getting below error, can you please help to understand why I am g...
use these three commands and it will workdbutils.fs.ls('dbfs:/FileStore/vehicle_data.csv')dbutils.fs.ls('/dbfs/FileStore/vehicle_data.csv')dbutils.fs.ls('/dbfs/dbfs/FileStore/vehicle_data.csv')ThanksAviral
I am trying to read messages from kafka topic using spark.readstream, I am using the following code to read it.My CODE:df = spark.readStream .format("kafka") .option("kafka.bootstrap.servers", "192.1xx.1.1xx:9xx") .option("subscr...
You can try this approach:https://stackoverflow.com/questions/57568038/how-to-see-the-dataframe-in-the-console-equivalent-of-show-for-structured-st/62161733#62161733ReadStream is running a thread in background so there's no easy way like df.show().
How to copy DELTA to AZURE SQL DB using ADF? Earlier we are using parquet format. Now, We have converted parquet to Delta by using below command: CONVERT TO DELTA parquet.path (Azure Blob Path)
Hi,I have cloned a remote repository into my folder in Repos. The repository has several feature branches.When I want to pull any branch, I select the desired branch in Repos and click on "Pull" button. And then I need to select another branch. Is th...
I'm trying to use the notebook with python to access our server through ssh. But I am not able to connect through the paramiko library. I have already authorized our server's firewall to accept the databrick ip. Have you ever had a similar case? can ...
yes this can happen you have to whitelist that Port in the databricks configuration, there is one spark configuration that you can add to your cluster, that will whitelist your particular portas that configuration can only give by databricks, you can...
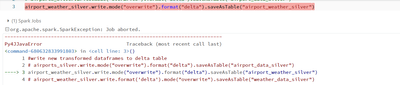
I'm trying to write a dataframe to a delta table and am getting this error.Im not sure what the issue is as I had no problem successfully writing other dataframes to delta tables. I attached a snippet of the data as well along with the schema:
Hi @Ravi Teja, We haven’t heard from you since the last response from @Rishabh Pandey, and I was checking back to see if his suggestions helped you.Or else, If you have any solution, please share it with the community, as it can be helpful to oth...
So I'm used to developing notebooks interactively. Write some code, run to see if I made an error and if no error, filter and display dataframe to see that I did what I intended. With DLT pipelines, however, I can't run interactively. Is my understan...
yes exactly i am also working on the dlt , and what i get to know about from this is that if we want to check our error , we have to run the pipeline again and again for debugging it , but this is not the best practice to do so , so the other metho...
Using AIrflow, I have created a DAG with a sequence of notebook tasks. The first notebook returns a batch id; the subsequent notebook tasks need this batch_id.I am using the DatabricksSubmitRunOperator to run the notebook task. This operator pushes ...
From what I understand - you want to pass a run_id parameter to the second notebook task?You can: Create a widget param inside your databricks notebook (https://docs.databricks.com/notebooks/widgets.html) that will consume your run_idPass the paramet...
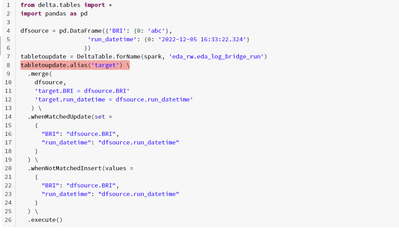
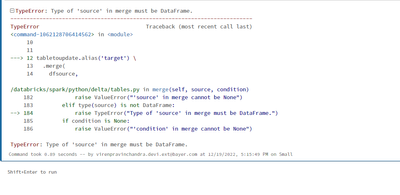
Hello,I would like to UPDATE the data in the delta table. For the same MERGE option came to my attention.However my below code ends up with errors as shown at the end. Kindly advice what am I missing here. Thank you.**********************************...
Hi there,We would like to create a data quality database that helps us understand how complete our data is. We would like to run a job each day that basically outputs the same table data as dbutils.data.summarize(df) for a given table and save it to ...
From what I know there's no easy way to save dbutils.data.summarize() into a df.You can still create your custom python/pyspark code to profile your data and save the output.