- 1181 Views
- 1 replies
- 1 kudos

- 1181 Views
- 1 replies
- 1 kudos
Latest Reply
- 1 kudos
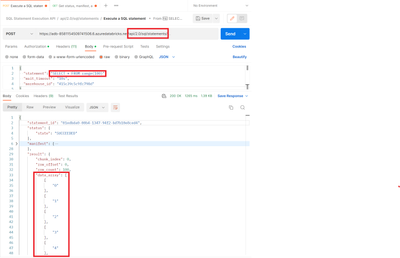
Hello @M Shee ,In a drop down you can select a value from a list of provided values, not type the values in. What you might be interested in is a combobox - It is combination of text and dropdown. It allows to select a value from a provided list or ...
- 1 kudos