hey @Ajay Pandey yes recently the new excel feature also comes in the market that we can enable the delta sharing from excel also so whatever the changes you will made to delta , it will automaticaly get saved in the excel file also ,refer this lin...
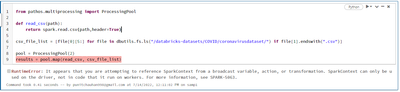
I'm using PySpark and Pathos to read numerous CSV files and create many DF, but I keep getting this problem.code for the same:-from pathos.multiprocessing import ProcessingPooldef readCsv(path): return spark.read.csv(path,header=True)csv_file_list =...
Hi,
Dataframe.Display method in Databricks notebook fetches only 1000 rows by default. Is there a way to change this default to display and download full result (more than 1000 rows) in python?
Thanks,
Ratnakar.
display method doesn't have the option to choose the number of rows. Use the show method. It is not neat and you can't do visualizations and downloads.
So I have two delta live tables. One that is the master table that contains all the prior data, and another table that contains all the new data for that specific day. I want to be able to merge those two table so that the master table contains would...
When I tried to access specific version data and set the arguments value to the specific number, I get all version data.data1 = delta_sharing.load_table_changes_as_spark(table_url, starting_version=1, ending_version=1)data2 = delta_sharing.load_table...
Hi, I have followed this guide (https://learn.microsoft.com/en-us/azure/databricks/_static/notebooks/image-data-source.html) to successfully load some image data into a spark df and display it as a thumbnail. I would like to display a single image fr...
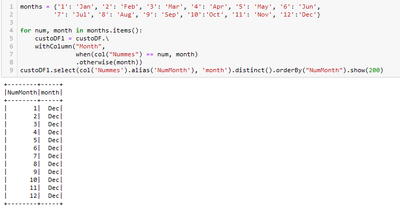
Hey everyone, I'm avoiding repeating the When Function for 12x, so I thought of the dictionary. I don't know if it's a limitation of the Spark function or a Logic error. Does the function allow this concatenation?
Hello everyone, I found this alternative to reduce repeated code.custoDF = (custoDF.withColumn('month', col('Nummes').cast('string'))
.replace(months, subset=['month']))
Hi,I am trying to set git credentials for my service principal. I follow the process described here but I get a 403 error when making the POST request to ${DATABRICKS_HOST}/api/2.0/git-credentials with service principal token.By the way, I also canno...
Hi @Sébastien FALQUIER it works for me, there are no restrictions. Maybe the PAT token you generated for the service principle got expired. Can you generate a new token and try to run GET/git-credentials API?How are you creating PAT for service prin...
When I want to create a cluster a get this error message:DetailsAWS API error code: InvalidGroup.NotFoundAWS error message: The security group 'sg-0ded75eefd66bf421' does not exist in VPC 'vpc-0ec7da3d5977f6ec9'And when I inspect the security groups ...
Hi, I am running into a similar issue. but in my case, the security has been deleted by mistake.Is there a way to make Databricks recreate the missing group ?@Kaniz Fatma , where can the CreateSecurityGroup command be ran ? Does it change the securi...
I need some solution for below problem.We have set of json files which are keep coming to aws s3, these files contains details for a property . please note 1 property can have 10-12 rows in this json file. Attached is sample json file.We need to read...
Is there any sand box kind of thing where we can do some hands-on on Databricks SQL/run the Note books attaching to the Clusters apart from the free trial provided by Databricks.
Hi @KVNARK ., We haven’t heard from you since the last response from @Harun Raseed Basheer, @Christopher Shehu and @Daniel Sahal and I was checking back to see if their suggestions helped you.Or else, If you have any solution, please share it wi...
I have a table with 600 columns and the table name is long. I want to use a table alias with autocomplete but it's not working. Any ideas how I can get this to work? works%sql
--autocomplete works
SELECT
verylongtablename.column200
verylongtabl...
Hi all,I am trying to create a table with a GUID column.I have tried using GUID, UUID; but both of them are not working.Can someone help me with the syntax for adding a GUID column?Thanks!