I have a table with 600 columns and the table name is long. I want to use a table alias with autocomplete but it's not working. Any ideas how I can get this to work? works%sql
--autocomplete works
SELECT
verylongtablename.column200
verylongtabl...
Hi all,I am trying to create a table with a GUID column.I have tried using GUID, UUID; but both of them are not working.Can someone help me with the syntax for adding a GUID column?Thanks!
Hi,Has anyone cleared professional DE? please advise on professional data engineer exam. will advance DE learning path be sufficient? Or need to follow some other resource as well.
Hi TeamI have passed the Databricks Lakehouse Fundamentals Accreditation (V2) on Dec 8th.Still have not received the Badge in credentials or any email of that kind.Please have a look.@Kaniz Fatma
Dear @Vidula Khanna Hope you're having great day. This is of HIGH priority for me, I've to schedule exam in December before slots are full.I gave Databricks Certified Associate Developer for Apache Spark 3.0 exam on 30th Nov but missed by one perc...
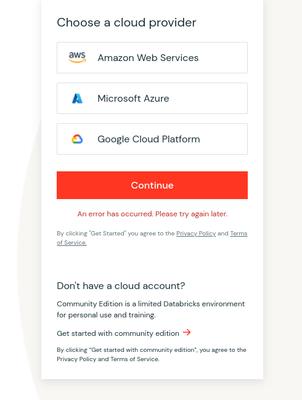
As you can see, I get the error underneath the big orange button. This is after I click the link at the bottom to try the community edition. I have tried a couple of locations since I am currently based in South Korea but I am actually from the UK. T...
Hi @Muhammad Ali Just a friendly follow-up. Are you able to log in to your Community-Edition account? If yes, then mark the answer as best or if you need further assistance kindly let me know. Thanks and Regards
Hi All,I am trying to write a streaming DF into dynamoDB with below code.tumbling_df.writeStream \ .format("org.apache.spark.sql.execution.streaming.sinks.DynamoDBSinkProvider") \ .option("region", "eu-west-2") \ .option("tableName", "PythonForeac...
Hi @SUDHANSHU RAJ ,I can't seem to find much on the "DynamoDBSinkProvider" source. Have you checked out the link for the streaming to DynamoDB documentation?
I was looking forward to using the Data Quality features that are provided with DLT but as far as I can the ingestion process is more restrictive than other methods. It doesn't seem like you can do much as far as setting delimiter type, headers or an...
DLT uses Autoloader to ingest data. With autoloader, you can provide read options for the table. https://docs.databricks.com/ingestion/auto-loader/options.html#csv-options has the docs on CSV. I attached a picture of an example.
Hi, How can I load an Excel File (located in Databricks Repo connected to Azure DevOps) into a dataframe? When I pass the full path into the load method, it displays an error.java.io.FileNotFoundException Has someone done it previously?
Hi,Just managed to do it.Upgraded the cluster to the latest version because Files in Repos only works in most recent versions of the cluster.When loading the dataframe, specify the path as follows: file:/Workspace/Repos/user@email.com/filepath/filena...
Hi everyone,I want to do some tests regarding data quality and for that I pretend to use PyDeequ on a databricks notebook. Keep in mind that I'm very new to databricks and Spark.First I created a cluster with the Runtime version "10.4 LTS (includes A...
Dear DB Experts,I am reaching out to check whether can i still use postgressql in notebooks with notebook as sql and try postgresql , as far as i know from reading the back end db is mysql correct me my understanding ?
My team uses a shared cluster. We've been having issues with spark_connect failing to work at times (can't easily reproduce). One thing I've recently noticed is that the Spark user through sparklyr seems to be set to the first person who connects to ...
I want to cast the data type of a column "X" in a table "A" where column "ID" is defined as GENERATED ALWAYS AS IDENTITY. Databricks refer to overwrite to achieve this: https://docs.databricks.com/delta/update-schema.htmlThe following operation:(spar...
Looks like it works when using GENERATED BY DEFAULT AS IDENTITY instead. There's no way of updating the schema from GENERATED ALWAYS AS IDENTITY to GENERATED BY DEFAULT AS IDENTITY, right? I have to create a new table (and then insert it with data fr...