As the title suggests, whenever I create a streaming live table it creates a __apply_changes_storage_"mytablename" section in the database on databricks. Is there a way to specify a different cloud location for these files?
Hi @Logan Nicol Great to meet you, and thanks for your question! Let's see if your peers in the community have an answer to your question first. Or else bricksters will get back to you soon. Thanks
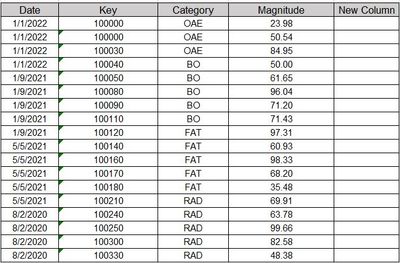
Details of the requirement is as below:I have a table with below structure:So i have to write a code in pyspark to calculate a new column.Logic for new column is Sum of Magnitude for different Categories divided by the total Magnitude.And it should b...
Hi @Faizan Arefin Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Than...
hi,i'm trying to test create a new job api (v 2.1) with python, but i got error:{ 'error_code': 'MALFORMED_REQUEST', 'message': 'Invalid JSON given in the body of the request - expected a map'}How do i validate json body before posting ?this is my js...
Hi @tum m Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Thanks!
Hi,After appending new values to a delta table, I need to delete duplicate rows.After deleting duplicate rows using PySpark, I overwrite the table (keeping the schema).My question is, do I have to do ZORDER again?Another question, is there another wa...
Is there syllabus change in self paced Data Engineering with Databrick course video?Last week i started that video lecture, but today i found that everything is change.https://partner-academy.databricks.com/learn/course/62/data-engineering-with-datab...
I’m not able to find a source where it explains how to determine how many job a written piece of pyspark code will trigger. Can you please help me here. About stages I know that the number of shuffles equals to the number of stages.
Hi @sagar Varma Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Thanks...
Hi there,I've had horrible experiences Vacuuming tables in the past and losing tons of data so I wanted to confirm a few things about Vacuuming and Z-Order.Background:Each day we run an ETL job that appends data in a table and stores the data in S3 b...
Hi @Avkash Kana Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Thanks...
Our use case is simple - to store our PB scale data and transform and use for BI, reporting and analytics. As my title says am trying to eliminate expenditure on Redshift as we are starting as a green field. I know I have designed/used just Delta lak...
Hi @Swetha Marakani Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Th...
Whenever I apply a CROSS JOIN to my Databricks SQL query I get a message letting me know that a column does not exists, but I'm not sure if the issue is with the CROSS JOIN.For example, the code should identify characters such as http, https, ://, / ...
@CARLTON PATTERSON Since you have given an alias "tt" to your table "basecrmcbreport.organizations", to access corresponding columns you will have to access them in format tt.<column_name>in your code in line #4, try accessing the column 'homepage_u...
With Unity Catalog gone GA on Azure, we are working through initial tests for setup within Databricks and Azure. However, we are not seeing the "Create Metastore" button available as indicated in documentation. We're also not seeing any additional pr...
I used this source https://docs.databricks.com/workflows/jobs/jobs.html#:~:text=You%20can%20use%20Run%20Now,different%20values%20for%20existing%20parameters.&text=next%20to%20Run%20Now%20and,on%20the%20type%20of%20task. But there is no example of how...
Hi @Andre Ten That's exactly how you specify the json parameters in databricks workflow. I have been doing in the same format and it works for me..removed the parameters as it is a bit sensitive. But I hope you get the point.Cheers.
Hi! I'm doing some tests to get an idea of how much time could be saved starting a cluster by using a pool and was wondering if the results I get are what should be expected.We're using AWS Databricks and used i3.xlarge as instance type (if that matt...
Hi @Paul Pelletier Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Tha...
We have enabled Cluster, Pool and Job access, and non-job owners can not run a job even though they are administrators. This disables users from creating cluster resources.When a non-owner of a job attempts to run, they get a permission denied.My un...
Hi @Marcus Simonsen Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Th...
My apologies in advance for sounding like a newbie. This is really just a curiosity question I have as an outsider observing my team clash with our client. Please ask any questions you have, and I will try my best to answer it.Currently, we are stori...
Hi @Nick ConnorsHope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Thanks...