I am working on Data Engineering with Databricks v3 course. In notebook DE 4.1 - DLT UI Walkthrough, I countered an error in cmd 11: DA.validate_pipeline_config(pipeline_language)The error message is: AssertionError: Expected the parameter "suite" to...
The DA validate function is just to check that you named the pipeline correctly, set up the correct number of workers, 0, and other configurations. The name and directory aren't crucial to the learning process. The goal is to get familiar with the ...
Hi community,We have the need of removing more than 4 byte characters using pyspark in databricks since these are not supported by amazon Redshift. Does someone know how can I accomplish this?Thank you very much in advanceRegards
assuming you are having a string type column in pyspark dataframe, one possible way could beidentify total number of characters for each value in column (say identify no of bytes taken by each character (say b)use substring() function to select first...
I have a few notebooks in workspaces that I created before linking repo to my git. I have tried importing them from the repo (databricks repo). The only two options are a local file from my pc or a url. The url for a notebook does not work. Do I need...
Hi @Stian Arntsen , when you click on the down arrow beside your notebook name (in your workspace), you will have a option called 'clone'. You can use it to clone your notebook from your workspace to repos. Hope it helps!
We are processing the josn file from the storage location on every day and it will get archived once the records are appended into the respective tables.source_location_path: "..../mon=05/day=01/fld1" , "..../mon=05/day=01/fld2" ..... "..../mon=05/d...
@Hare Krishnan the issues highlighted can easily be handled using the .option("mergeSchema", "true") at the time of reading all the files.Sample code:spark.read.option("mergeSchema", "true").json(<file paths>, multiLine=True)The only scenario this w...
I'm using Auto Loader in a SQL notebook and I would like to configure file notification mode, but I don't know how to retrieve the client secret of the service principal from Azure Key Vault. Is there any example notebook somewhere? The notebook is p...
Hi @Magnus Johannesson , you must use the Secrets utility (dbutils.secrets) in a notebook or job to read a secret.https://learn.microsoft.com/en-us/azure/databricks/dev-tools/databricks-utils#dbutils-secretsHope it helps!
We have one project requirement where we have to store only the 14 days history for delta tables. So for testing, I have set the delta.logRetentionDuration = 2 days using the below commandspark.sql("alter table delta.`[delta_file_path]` set TBLPROPER...
Hi @Priyanka Mane, We haven’t heard from you since the last response from @Werner Stinckens and @Uma Maheswara Rao Desula, and I was checking back to see if their suggestions helped you.Or else, If you have any solution, please share it with the c...
Hi @andrew li, We haven’t heard from you since the last response from @Uma Maheswara Rao Desula, and I was checking back to see if his suggestions helped you. Or else, If you have any solution, please share it with the community, as it can be helpf...
I'm getting this message with the following code:from databricks import feature_store
fs = feature_store.FeatureStoreClient()
fs.create_table(
name='feature_store.user_login',
primary_keys=['user_id'],
df=df_x,
description='user l...
Yes, it's a nice thing to do. You can report it here: https://community.databricks.com/s/topic/0TO3f000000CnKrGAK/bug-report and if it's more urgent or blocking for you, you can also open a ticket to the help center: https://docs.databricks.com/resou...
I have a dms task that processing the full-load and replication ongoing tasksfrom source (MSSQL) to target (AWS S3)then use delta lake to handle the CDC logsI've a notebook that would insert data into mssql continuously (with id as primary key)then d...
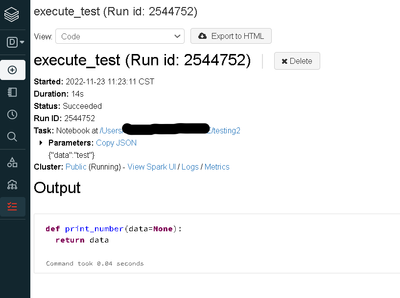
Calling a databricks notebook using the Rest API, can confirm that it is executing the notebook, but is not accepting my parameters or returning a notebook output. Any ideas on what I am doing wrong here?My code and notebook function are below, tryin...
Resolved this by using dbutils within the notebook being called from the API.# databricks notebook function
data = dbutils.widgets.get('data') # pulls base_parameters from API call
def add_test(i):
result = i + ' COMPLETE'
return result
...
I wanted to query a MySQL Table using Databricks rather than reading the complete data using a dbtable option, which will help in incremental loads.remote_table = (spark.read .format("jdbc") .option("driver", driver) .option("url", URL) .option("quer...
Hi @Kaniz Fatma and @Nadia Elsayed ,i have taken databricks data engineer associate exam on nov 27th . in result mail it is mentioned i have obtained below 70% in assessment but as per the section wise results i have gained more than 70% . Can you ...
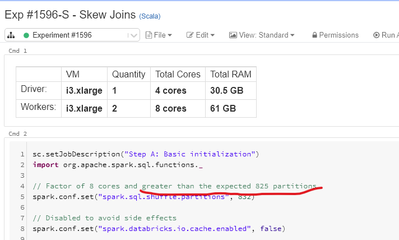
I am learning how to optimize Spark applications with experiments from Spark UI Simulator. There is experiment #1596 about data skew and in command 2 there is comment about how many partitions will be set as default:// Factor of 8 cores and greater ...
Hi @Bartosz Maciejewski Generally we arrive at the number of shuffle partitions using the following method.Input Size Data - 100 GBIdeal partition target size - 128 MBCores - 8Ideal number of partitions = (100*1028)/128 = 803.25 ~ 804To utiltize the...
![204293406-01bf6cc1-bb6f-42bb-9bfe-e9b1f5135ae9[1]](/t5/image/serverpage/image-id/1103i5E2E130C9E462F86/image-size/medium?v=v2&px=400)